Source: LearnCpp.com by Alex
Introduction to programming languages
Optional Reading: Difference between compiled and interpreted languages?
Interpreters and compilers have complementary strengths and weaknesses, it’s becoming increasingly common for language runtimes to combine elements of both. Java’s JVM is a good example of this. The Java itself is compiled to byte code, and then directly to machine code.
Also, another key point from this article is that languages are not compiled or interpreted. They are not a nature of the languages. C code is compiled, but there are C interpreters available that make it easier to debug or visualize the code.
Introduction to C++
History of C++
- 1979: Bjarne Stroustrup at Bell Labs started developing C++
- 1998: Ratified by the ISO committee in 1998
- 2003: C++03
- 2011: C++11 (a huge number of new capabilities)
- 2014: C++14
- 2017: C++17
C and C++’s philosophy
The underlying design philosophy of C and C++ can be summed up as "trust the programmer", which is both wonderful and dangerous. Although we have the freedom, it’s important to know the things you should not do with C++.
History of “bug”
The term bug was first used by Thomas Edison back in the 1870s! However, the term was popularized in the 1940s when engineers found an actual moth stuck in the hardware of an early computer, causing a short circuit. Both the log book in which the error was reported and the moth are now part of the Smithsonian Museum of American History.
Compilers, linkers, and the libraries
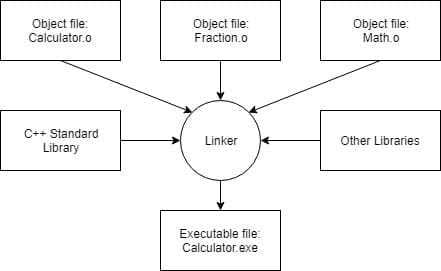
For complex projects, some development environments use a makefile, which is a file that describes how to build a program.
C++ Basics
This section covers too many C stuff. I just write down something important to notice and recall!
std::endl vs ‘\n’
Using std::endl can be a bit inefficient, as it actually does two jobs: it moves the cursor to the next line, and it “flushes” the output (makes sure that it shows up on the screen immediately; output the buffer).
When writing text to the console using std::cout, std::cout usually flushes output anyway (and if it doesn’t, it usually doesn’t matter), so having std::endl flush is rarely important.
The ‘\n’ character doesn’t do the redundant flush, so it performs better.
<<- insertion operator>>- extraction operator. The input must be stored in a variable to be used.
Expressions
Initialization can be used to give a variable a value at the point of creation. C++ supports 3 types of initialization:
- copy initialization
- direct initialization
- uniform initialization.
An expression is a combination of literals, variables, operators, and explicit function calls (not shown above) that produces a single output value. When an expression is executed, each of the terms in the expression is evaluated until a single value remains (this process is called evaluation). That single value is the result of the expression.
Statements vs. Expressions:
Statementsare used when we want the program to perform an action.Expressionsare used when we want the program to calculate a value.
Certain expressions (e.g. x = 5) are useful by themselves. However, we mentioned above that expressions must be part of a statement, so how can we use these expressions by themselves?
Fortunately, we can convert any expression into an equivalent statement (called an expression statement). An expression statement is a statement that consists of an expression followed by a semicolon. When the statement is executed, the expression will be evaluated (and the result of the expression will be discarded).
1 | int x; // this statement does not contain an expression (this is just a variable definition) |
Functions and Files
C++ does not define whether function calls evaluate arguments left to right or vice-versa.
Function parameters and variables defined inside the function body are called local variables. The time in which a variable exists is called its lifetime. Variables are created and destroyed at runtime, which is when the program is running. A variable’s scope determines where it can be accessed. When a variable can be accessed, we say it is in scope. When it cannot be accessed, we say it is out of scope. Scope is a compile-time property, meaning it is enforced at compile time.
Refactoring is the process of breaking down a larger function into many smaller, simpler functions.
Whitespace refers to characters used for formatting purposes. In C++, this includes spaces, tabs, and newlines.
- A
definitionactually implements (for functions and types) or instantiates (for variables) an identifier. - A
declarationis a statement that tells the compiler about the existence of the identifier. In C++, all definitions serve as declarations. Pure declarations are declarations that are not definitions (such as function prototypes).
Namespace
In C++, a namespace is a grouping of identifiers that is used to reduce the possibility of naming collisions. It turns out that std::cout‘s name isn’t really std::cout. It’s actually just cout, and std is the name of the namespace that identifier cout is part of. In modern C++, all of the functionality in the C++ standard library is now defined inside namespace std (short for standard).
When you use an identifier that is defined inside a namespace (such as the std namespace), you have to tell the compiler that the identifier lives inside the namespace.
Explicit namespace qualifier
std::
This is the safest way to usecout, sine there’s no ambiguity.Using directive (and why to avoid it!!!)
Ausingdirective tells the compiler to check a specified namespace when trying to resolve an identifier that has no namespace prefix. So in the above example, when the compiler goes to determine what identifiercoutis, it will check both locally (where it is undefined) and in the std namespace (where it will match to std::cout).1
2
3
4
5
6
using namespace std;
int main() {
cout << "Hello World!";
return 0;
}
Many texts, tutorials, and even some compilers recommend or use a using directive at the top of the program. However, this is a bad practice, and is highly discouraged.
1 |
|
bool & Literals
1 | int main() { |
In C++, bool is treated as 0 or 1.
C++ has two kinds of constants: literal and symbolic. In this lesson, we’ll cover literals.
Just like variables have a type, all literals have a type too. The type of a literal is assumed from the value and format of the literal itself.
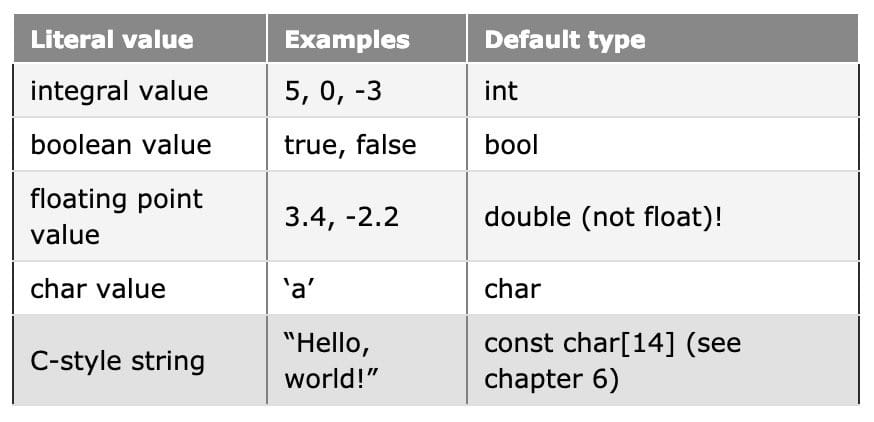
You can use literal suffixes to change the default type of a literal if its type is not what you want.
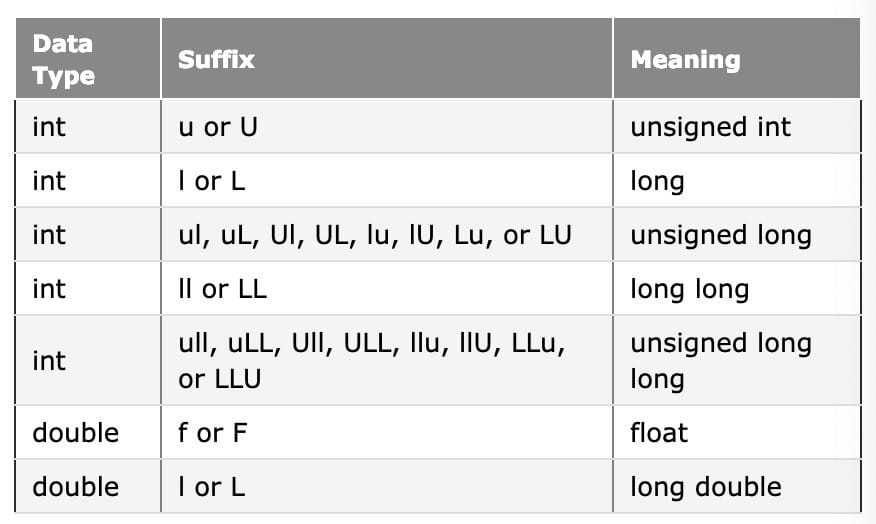
1 | float f1 = 5.0f; |
In C++14, we can assign binary literals by using 0b prefix:
1 | int bin(0); |
Because long literals can be hard to read, C++14 also adds the ability to use a quotation mark ' as a digit separator. In Java, we use _ instead.
1 | int bin = 0b1011'0010; // assign binary 1011 0010 to the variable |
const
To make a variable constant, simply put the const keyword either before or after the type identifier, like so:
1 | const double gravity { 9.8 }; // preferred use of const before type |
Although C++ will accept const either before or after the type identifier, we recommend using it before the type because it better follows standard English language convention where modifiers come before the object being modified (e.g. a green ball, not a ball green).
Const variables must be initialized when you define them, and then that value cannot be changed via assignment. Otherwise, it will cause a compile error:
1 | const double gravity; // compiler error |
Note that const variables can be initialized from non-const values:
1 | std::cout << "Enter your age: "; |
Const is used most often with function parameters:
1 | void printInteger(const int myValue) { |
Does two things:
- Let the person calling the function know that the function will not change the value of
myValue. - It ensures that the function doesn’t change the value of
myValue.
However, with parameters passed by value, like the above, we generally don’t care if the function changes the value of the parameter, since it’s just a copy that will be destroyed later. Thus, we usually don’t make parameters passed by value const.
Runtime constants are those whose initialization values can only be resolved at runtime (when your program is running). Variables such as myValue above is a runtime constant, because the compiler can’t determine their values at compile time. myValue depends on the value passed into the function (which is only known at runtime).
In most cases, it doesn’t matter whether a constant value is runtime or compile-time. However, there are a few odd cases where C++ requires a compile-time constant instead of a run-time constant (such as when defining the length of a fixed-size array — we’ll cover this later). Because a const value could be either runtime or compile-time, the compiler has to keep track of which kind of constant it is.
To help provide more specificity, C++11 introduced new keyword constexpr, which ensures that the constant must be a compile-time constant:
1 | constexpr double gravity (9.8); |
- Rule 1: Any variable that should not change values after initialization and whose initializer is known at compile-time should be declared as
constexpr. - Rule 2: Any variable that should not change values after initialization and whose initializer is not known at compile-time should be declared as
const.
Naming your const variables: Some programmers prefer to use all upper-case names for const variables. Others use normal variable names with a k prefix. However, we will use normal variable naming conventions, which is more common. Const variables act exactly like normal variables in every case except that they cannot be assigned to, so there’s no particular reason they need to be denoted as special.
Symbolic constants: A symbolic constant is a name given to a constant literal value. There are two ways to declare symbolic constants in C++. One of them is good, and the other one is not.
- Bad: Using object-like
macroswith a substitution parameter as symbolic constants. - Better: Use
constvariables, or better,constexpr.
That way using symbolic constants, if you ever need to change them, you only need to change them in one place.
Side effects in inc / dec
A function or expression is said to have a side effect if it modifies some state (e.g. any stored information in memory), does input or output, or calls other functions that have side effects.
Usually, they are useful:
1 | x = 5; // the assignment operator modifies the state of x |
However, side effects can also lead to unexpected results:
1 | int add(int x, int y) { return x + y; } |
C++ does not define the order in which function arguments are evaluated. Note that this is only a problem because one of the arguments to function add() has a side effect.
Another popular example:
1 | int main() { |
If the
++is applied toxbefore the assignment, the answer will be 1 (postfix operator++ incrementsxfrom 1 to 2, but it evaluates to 1, so the expression becomesx = 1).If the
++is applied toxafter the assignment, the answer will be 2 (this evaluates asx = x, then postfix operator++ is applied, incrementingxfrom 1 to 2).
There are other cases where C++ does not specify the order in which certain things are evaluated, so different compilers will make different assumptions.
Please don’t ask why your programs that violate the above rules produce results that don’t seem to make sense. That’s what happens when you write programs that have "undefined behavior". :)
Bit flags & Bit masks (optional)
In the majority of cases, this is fine – we’re usually not so hard-up for memory that we need to care about 7 wasted bits. However, in some storage-intensive cases, it can be useful to “pack” 8 individual boolean values into a single byte for storage efficiency purposes. This is done by using the bitwise operators to set, clear, and query individual bits in a byte, treating each as a separate boolean value. These individual bits are called bit flags.
Defining bit flags in C++14
In order to work with individual bits, we need to have a way to identify the individual bits within a byte, so we can manipulate those bits (turn them on and off). This is typically done by defining a symbolic constant to give a meaningful name to each bit used. The symbolic constant is given a value that represents that bit.
Because C++14 supports binary literals, this is easiest in C++14:
1 | // Define 8 separate bit flags (these can represent whatever you want) |
Defining bit flags in C++11 or earlier
Because C++11 doesn’t support binary literals, we have to use other methods to set the symbolic constants. There are two good methods for doing this. Less comprehensible, but more common, is to use hexadecimal.
1 | // Define 8 separate bit flags (these can represent whatever you want) |
This can be a little hard to read. One way to make it easier is to use the left-shift operator to shift a bit into the proper location.
1 | const unsigned char option0 = 1 << 0; // 0000 0001 |
Using bit flags to manipulate bits
The next thing we need is a variable that we want to manipulate. Typically, we use an unsigned integer of the appropriate size (8 bits, 16 bits, 32 bits, etc… depending on how many options we have).
1 | unsigned char myflags = 0; // all bits turned off to start |
To set a bit (turn on)
We use bitwise OR equals (operator |=):
1 | myflags |= option4; // turn option 4 on |
Turn bits off
1 | myflags &= ~option4; |
Toggle a bit state
We use bitwise XOR:
1 | myflags ^= option4; // flip option4 from on to off, or vice versa |
Determining if a bit is on or off
1 | if (myflags & option4) |
Here is an actual example for a game we might write:
1 | // Define a bunch of physical/emotional states |
Why are bit flags useful?
Astute readers will note that the above myflags example actually doesn’t save any memory. 8 booleans would normally take 8 bytes. But the above example uses 9 bytes (8 bytes to define the bit flag options, and 1 bytes for the bit flag)! So why would you actually want to use bit flags?
Bit flags are typically used in two cases:
When you have many sets of identical bitflags.
Imagine you had a function that could take any combination of 32 different options. One way to write that function would be to use 32 individual boolean parameters:
1
2
3void someFunction(bool option1, bool option2, bool option3, bool option4, bool option5, bool option6, bool option7, bool option8, bool option9, bool option10, bool option11, bool option12, bool option13, bool option14, bool option15, bool option16, bool option17, bool option18, bool option19, bool option20, bool option21, bool option22, bool option23, bool option24, bool option25, bool option26, bool option27, bool option28, bool option29, bool option30, bool option31, bool option32);
// ↓
void someFunction(unsigned int options);
An introduction to std::bitset
All of this bit flipping is exhausting, isn’t it? Fortunately, the C++ standard library comes with functionality called std::bitset that helps us manage bit flags.
To create a std::bitset, you need to include the bitset header, and then define a std::bitset variable indicating how many bits are needed. The number of bits must be a compile time constant.
1 |
|
std::bitset provides 4 key functions:
- test() allows us to query whether a bit is a 0 or 1
- set() allows us to turn a bit on (this will do nothing if the bit is already on)
- reset() allows us to turn a bit off (this will do nothing if the bit is already off)
- flip() allows us to flip a bit from a 0 to a 1 or vice versa
Bit masks
1 | const unsigned int redBits = 0xFF'00'00'00; |
Variable Scope and More Types
Local variables, scope, and duration
When discussing variables, it’s useful to separate out the concepts of scope and duration.
- A variable’s
scopedetermines where a variable is accessible. - A variable’s
durationdetermines when it is created and destroyed. The two concepts are often linked.
Variables defined inside a function are called local variables. Local variables have automatic duration, which means they are created (and initialized, if relevant) at the point of definition, and destroyed when the block they are defined in is exited. Local variables have block scope (also called local scope), which means they enter scope at the point of declaration and go out of scope at the end of the block that they are defined in.
1 | int main() { // outer block |
Note that a variable inside a nested block can have the same name as a variable inside an outer block. When this happens, the nested variable “hides” the outer variable. This is called name hiding or shadowing.
Shadowing is something that should generally be avoided, as it is quite confusing!
Rule: Avoid using nested variables with the same names as variables in an outer block. Variables should be defined in the most limited scope possible.
Global variables and linkage
Variables declared outside of a function are called global variables. Global variables have static duration, which means they are created when the program starts and are destroyed when it ends. Global variables have file scope (also informally called global scope or global namespace scope), which means they are visible until the end of the file in which they are declared.
Similar to how variables in an inner block with the same name as a variable in an outer block hides the variable in the outer block, local variables with the same name as a global variable hide the global variable inside the block that the local variable is declared in. However, the global scope operator :: can be used to tell the compiler you mean the global version instead of the local version.
1 | int value(5); |
However, having local variables with the same name as global variables is usually a recipe for trouble, and should be avoided whenever possible. By convention, many developers prefix global variable names with g_ to indicate that they are global. This both helps identify global variables as well as avoid naming conflicts with local variables.
Internal and external linkage via the static and extern keywords:
In addition to scope and duration, variables have a third property: linkage. A variable’s linkage determines whether multiple instances of an identifier refer to the same variable or not.
(Strong & weak symbols?)
A variable with no linkage can only be referred to from the limited scope it exists in. Regular local variables are an example of variables with no linkage. Two local variables with the same name but defined in different functions have no linkage – each will be considered an independent variable.
A variable with
internal linkageis called aninternal variable(orstatic variable). Variables with internal linkage can be used anywhere within the file they are defined in, but cannot be referenced outside the file they exist in.A variable with
external linkageis called anexternal variable. Variables with external linkage can be used both in the file they are defined in, as well as in other files.
If we want to make a global variable internal (able to be used only within a single file), we can use the static keyword to do so; similarly, if we want to make a global variable external (able to be used anywhere in our program), we can use the extern keyword to do so.
1 | extern double g_y(9.8); |
By default, non-const variables declared outside of a function are assumed to be external. However, const variables declared outside of a function are assumed to be internal.
Note that this means the extern keyword has different meanings in different contexts:
- In some contexts, extern means “give this variable external linkage”.
- In other contexts, extern means “this is a forward declaration for an external variable that is defined somewhere else”.
Function linkage:
Functions have the same linkage property that variables do. Functions always default to external linkage, but can be set to internal linkage via the static keyword.
Function forward declarations don’t need the extern keyword. The compiler is able to tell whether you’re defining a function or a function prototype by whether you supply a function body or not.
The one-definition rule and non-external linkage:
Forward declarations and definitions, we noted that the one-definition rule says that an object or function can’t have more than one definition, either within a file or a program.
However, it’s worth noting that non-extern objects and functions in different files are considered to be different entities, even if their names and types are identical. This makes sense, since they can’t be seen outside of their respective files anyway.
Global symbolic constants:
1 |
|
This duplication of variables isn’t really that much of a problem (since constants aren’t likely to be huge), but changing a single constant value (not names) would require recompiling every file that includes the constants header, which can lead to lengthy rebuild times for larger projects.
We can avoid this problem by turning these constants into const global variables, and changing the header file to hold only the variable forward declarations:
constants.cpp:
1 | namespace Constants { |
constants.h:
1 |
|
However, there are a couple of downsides to doing this. First, these constants are now considered compile-time constants only within the file they are actually defined in (constants.cpp), not anywhere else they are used. This means that outside of constants.cpp, they can’t be used anywhere that requires a compile-time constant (constexpr) (such as for the length of a fixed array, something we talk about in chapter 6). Second, the compiler may not be able to optimize these as much.
Given the above downsides, we recommend defining your constants in the header file. If you find that for some reason those constants are causing trouble, you can move them into a .cpp file as per the above as needed.
Link: When to use extern in C++
Why (non-const) global variables are evil?
If you were to ask a veteran programmer for one piece of advice on good programming practices, after some thought, the most likely answer would be, “Avoid global variables!”. And with good reason: global variables are one of the most abused concepts in the language. Although they may seem harmless in small academic programs, they are often hugely problematic in larger ones.
But before we go into why, we should make a clarification. When developers tell you that global variables are evil, they’re not talking about ALL global variables. They’re mostly talking about non-const global variables.
One of the reasons to declare local variables as close to where they are used as possible is because doing so minimizes the amount of code you need to look through to understand what the variable does. Global variables are at the opposite end of the spectrum — because they can be used anywhere, you might have to look through a significant amount of code to understand their usage.
Global variables also make your program less modular and less flexible. A function that utilizes nothing but its parameters and has no side effects is perfectly modular. Modularity helps both in understanding what a program does, as well as with reusability. Global variables reduce modularity significantly.
Rule: Use local variables instead of global variables whenever reasonable, and pass them to the functions that need them.
So what are very good reasons to use non-const global variables?
There aren’t many. In many cases, there are other ways to solve the problem that avoids the use of non-const global variables. But in some cases, judicious use of non-const global variables can actually reduce program complexity, and in these rare cases, their use may be better than the alternatives.
For example, if your program uses a database to read and write data, it may make sense to define the database globally, because it could be needed from anywhere. Similarly, if your program has an error log (or debug log) where you can dump error (or debug) information, it probably makes sense to define that globally, because you’re mostly likely to only have one log and it could be used anywhere. A sound library would be another good example: you probably don’t want to pass this to every function that needs it. Since you’ll probably only have one sound library managing all of your sounds, it may be better to declare it globally, initialize it at program launch, and then treat it as read-only thereafter.
If you do find a good use for a non-const global variable, a few useful bits of advice will minimize the amount of trouble you can get into.
First, prefix all your global variables with
g_, and/or put them in a namespace, both to reduce the chance of naming collisions and raise awareness that a variable is global.Second, instead of allowing direct access to the global variable, it’s a better practice to “encapsulate” the variable.
Third, when writing a standalone function that uses the global variable, don’t use the variable directly in your function body. Instead, pass it in as a parameter, and use the parameter. That way, if your function ever needs to use a different value for some circumstance, you can simply vary the parameter. This helps maintain modularity.
1
2
3
4
5
6
7
8// bad
double instantVelocity(int time) {
return g_gravity * time;
}
// good
double instantVelocity(int time, double gravity) {
return gravity * time;
}
Static duration variables
The static keyword is one of the most confusing keywords in the C++ language (maybe with the exception of the keyword class). This is because it has different meanings depending on where it is used.
Just like we use “g_” to prefix global variables, it’s common to use “s_” to prefix static (static duration) variables. Note that internal linkage global variables (also declared using the static keyword) get a “g_”, not a “s_”.
Static variables offer some of the benefit of global variables (they don’t get destroyed until the end of the program) while limiting their visibility to block scope. This makes them much safer for use than global variables.
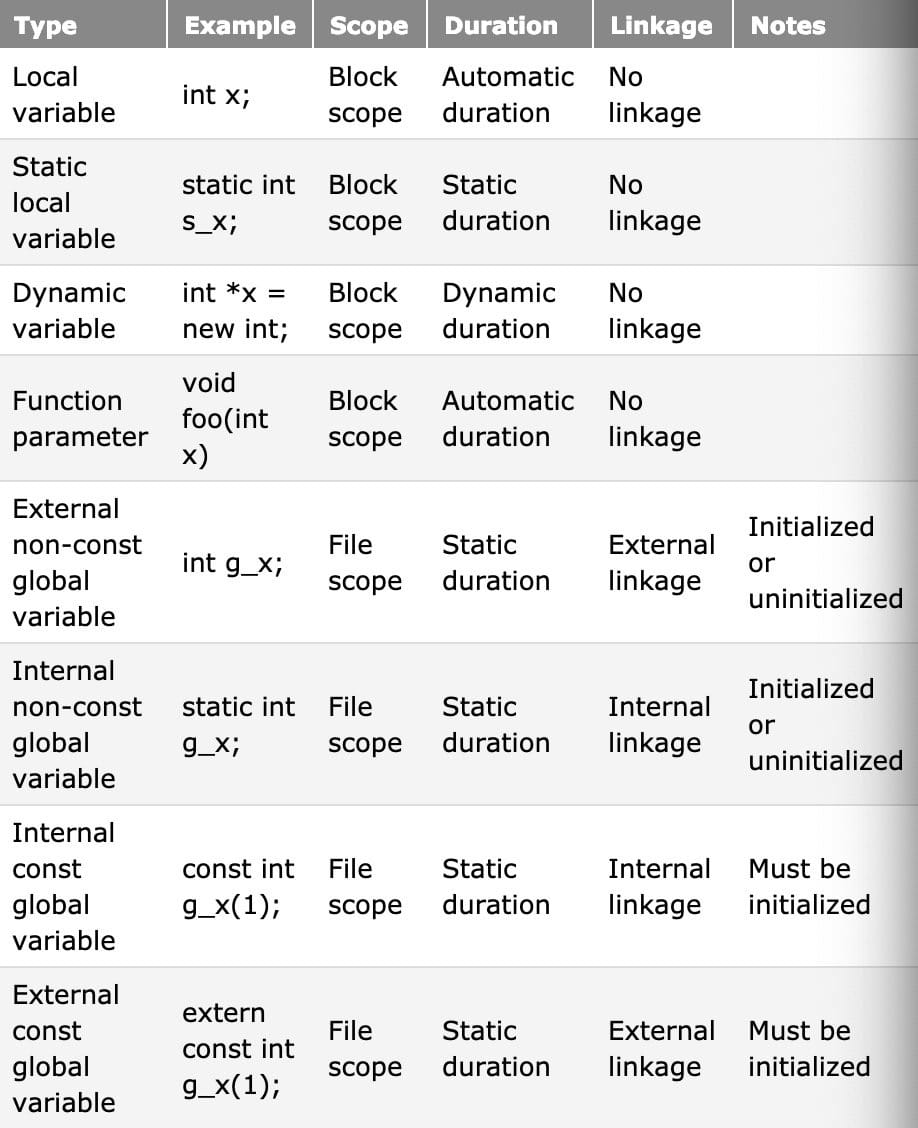
Scope, duration, and linkage summary
A variable’s duration determines when it is created and destroyed.
- automatic duration (stack)
- static duration (static section)
- dynamic duration (heap)
Linkage of an identifier determines whether multiple instances of an identifier refer to the same identifier or not.
- no linkage (the identifier only refers to itself)
- internal linkage (can be accessed anywhere within the file, by “static”)
- external linkage (the file, or the other files via forward declaration, by “extern”)
Namespaces
Problem (this is why namespaces are introduced):
foo.h
1 | int doSomething(int x, int y) { |
goo.h
1 | int doSomething(int x, int y) { |
main.cpp
1 |
|
What is a namespace?
A namespace defines an area of code in which all identifiers are guaranteed to be unique. By default, global variables and normal functions are defined in the global namespace.
foo.h:
1 | namespace Foo { |
Multiple namespace blocks with the same name are allowed. It’s legal to declare namespace blocks in multiple locations (either across multiple files, or multiple places within the same file). All declarations within the namespace block are considered part of the namespace.
add.h:
1 | namespace BasicMath { |
subtract.h:
1 | namespace BasicMath { |
The standard library makes extensive use of this feature, as all of the different header files included with the standard library have their functionality inside namespace std.
Nested namespaces and namespace aliases:
1 | namespace Foo { |
In C++17, nested namespaces can also be declared this way:
1 | namespace Foo::Goo { // left 2 right |
Because typing the fully qualified name of a variable or function inside a nested namespace can be painful, C++ allows you to create namespace aliases.
1 | namespace Foo { |
It’s worth noting that namespaces in C++ were not designed as a way to implement an information hierarchy – they were designed primarily as a mechanism for preventing naming collisions.
In general, you should avoid nesting namespaces if possible, and there are few good reasons to nest them more than 2 levels deep. However, in later lessons, we will see other related cases where the scope resolution operator needs to be used more than once.
Using statements
If you’re using the standard library a lot, typing “std::” before everything you use from the standard library can become repetitive. C++ provides some alternatives to simplify things, called using statements.
The using declaration:
1 | using std::cout; // this using declaration tells the compiler that cout should resolve to std::cout |
This doesn’t save much effort in this trivial example, but if you are using cout a lot inside of a function, a using declaration can make your code more readable. Note that you will need a separate using declaration for each name you use (e.g. one for std::cout, one for std::cin, and one for std::endl).
The using directive:
1 | using namespace std; // this using directive tells the compiler that we're using everything in the std namespace! |
For illustrative purposes, let’s take a look at an example where a using directive causes ambiguity:
Example 1:
1 | namespace a { |
Example 2:
1 | int cout() { |
Many new programmers put using directives into the global scope. This pulls all of the names from the namespace directly into the global scope, greatly increasing the chance for naming collisions to occur. This is considered bad practice.
Rule: Avoid using statements outside of a function (in the global scope).
Suggestion: We recommend you avoid using directives entirely.
It’s because there’s no way to cancel the “using namespace XXX”.
The best you can do is intentionally limit the scope of the using statement from the outset using the block scoping rules.
1 | int main() { |
Of course, all of this headache can be avoided by explicitly using the scope resolution operator :: in the first place.
Random number generation
Computers are generally incapable of generating random numbers. Instead, they must simulate randomness, which is most often done using pseudo-random number generators.
A pseudo-random number generator (PRNG) is a program that takes a starting number (called a seed), and performs mathematical operations on it to transform it into some other number that appears to be unrelated to the seed. It then takes that generated number and performs the same mathematical operation on it to transform it into a new number that appears unrelated to the number it was generated from. By continually applying the algorithm to the last generated number, it can generate a series of new numbers that will appear to be random if the algorithm is complex enough.
A short program that generates 100 pseudo-random numbers:
1 |
|
What is a good PRNG?
- The PRNG should generate each number with approximately the same probability.
- The method by which the next number in the sequence is generated shouldn’t be obvious or predictable.
- The PRNG should have a good dimensional distribution of numbers.
- All PRNGs are periodic, which means that at some point the sequence of numbers generated will eventually begin to repeat itself.
std::rand() is a mediocre PRNG
The algorithm used to implement std::rand() can vary from compiler to compiler, leading to results that may not be consistent across compilers. Most implementations of rand() use a method called a Linear Congruential Generator (LCG). If you have a look at the first example in this lesson, you’ll note that it’s actually a LCG, though one with intentionally picked poor constants. LCGs tend to have shortcomings that make them not good choices for most kinds of problems.
For applications where a high-quality PRNG is useful, I would recommend Mersenne Twister (or one of its variants), which produces great results and is relatively easy to use. Mersenne Twister was adopted into C++11, and we’ll show how to use it later in this lesson.
Although you can create a static local std::mt19937 variable in each function that needs it (static so that it only gets seeded once), it’s a little overkill to have every function that need a random number generator seed and maintain its own local generator. A better option in most cases is to create a global random number generator (inside a namespace!). Remember how we told you to avoid non-const global variables? This is an exception (also note: std::rand() and std::srand() access a global object, so there’s precedent for this).
1 |
|
A perhaps better solution is to use a 3rd party library that handles all of this stuff for you, such as the header-only Effolkronium's random library. You simply add the header to your project, #include it, and then you can start generating random numbers via Random::get(min, max).
1 |
|
Input Extraction, and dealing with invalid text input
When the user enters input in response to an extraction operation, that data is placed in a buffer inside of std::cin. A buffer (also called a data buffer) is simply a piece of memory set aside for storing data temporarily while it’s moved from one place to another. In this case, the buffer is used to hold user input while it’s waiting to be extracted to variables.
When the extraction operator >> is used, the following procedure happens:
- If there is data already in the input buffer, that data is used for extraction.
- If the input buffer contains no data, the user is asked to input data for extraction (this is the case most of the time). When the user hits enter, a ‘\n’ character will be placed in the input buffer.
- operator
>>extracts as much data from the input buffer as it can into the variable (ignoring any leading whitespace characters, such as spaces, tabs, or ‘\n’). - Any data that cannot be extracted is left in the input buffer for the next extraction.
Extraction succeeds if at least one character is extracted from the input buffer. Any unextracted input is left in the input buffer for future extractions. For example:
1 | int x; |
If the user enters “5a”, 5 will be extracted, converted to an integer, and assigned to variable x. “a\n” will be left in the input stream for the next extraction. Extraction fails if the input data does not match the type of the variable being extracted to. For example:
1 | // current buffer: "a\n" |
There are three basic ways to do input validation:
- Inline (as the uesr types)
- Prevent the user from typing invalid input the first place.
- Unfortunately,
std::cindoes not support this style of validation.
- Post-entry (after the user types)
- Let the user enter whatever they want into a string, then validate whether the string is correct, and if so, convert the string to the final variable format.
- Let the user enter whatever they want, let
std::cinand operator>>try to extract it, and handle the error cases.
Types of invalid text input:
Error A: Input extraction succeeds but the input is meaningless to the program (e.g. entering
kas your mathematical operator).1
2
3
4
5
6
7
8
9
10
11
12
13// For A
char getOperator() {
while (true) {
std::cout << "Enter:" << "\n";
char op;
std::cin >> op;
if (op == '+' || op == '-' || op == '*' || op == '/')
return op;
else
std::cout << "Oops! Try again!" << "\n";
}
}Error B: Input extraction succeeds but the user enters additional input (e.g. entering
*q helloas your mathematical operator).1
Enter a double value: 5*7
Then,
1
Enter one of the following: +, -, *, or /: Enter a double value: 5 * 7 is 35
In this case above, we cannot continue entering text since there is data in the buffer.
Since the last character the user entered must be a ‘\n’, we can tell std::cin to ignore buffered characters
until it findsa newline character (which is removed as well).1
std::cin.ignore(32767, '\n'); // clear (up to 32767) characters out of the buffer until a '\n' character is removed
Error C: Input extraction fails (e.g. trying to enter
qinto a numeric input).Now consider the following execution of the calculator program:
1
Enter a double value: a
You shouldn’t be surprised that the program doesn’t perform as expected, but how it fails is interesting:
1
2Enter a double value: a
Enter one of the following: +, -, *, or /: Enter a double value:and the problem suddenly ends. This looks pretty similar to the extraneous input case, but it’s a little different. Let’s take a closer look.
When the user enters ‘a’, that character is placed in the buffer. Then operator
>>tries to extract ‘a’ to variable x, which is of type double. Since ‘a’ can’t be converted to a double, operator>>can’t do the extraction.Two things happen at this point: ‘a’ is left in the buffer, and std::cin goes into
failure mode.Once in failure mode, future requests for input extraction will silently fail. Thus in our calculator program, the output prompts still print, but any requests for further extraction are ignored. The program simply runs to the end and then terminates (without printing a result, because we never read in a valid mathematical operation).
Fortunately, we can detect whether an extraction has failed and fix it:
1
2
3
4
5if (std::cin.fail()) {
// yep, so let's handle the failure
std::cin.clear(); // put us back in 'normal' operation mode
std::cin.ignore(32767, '\n'); // and remove the bad input since previous is still in the buffer
}Combine A, B, and C:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15double getDouble() {
while (true) {
std::cout << "Enter a double value: ";
double x;
std::cin >> x;
if (std::cin.fail()) {
std::cin.clear();
std::cin.ignore(32767, '\n');
} else {
std::cin.ignore(32767, '\n');
return x;
}
}
}Note: Prior to C++11, a failed extraction would not modify the variable being extracted to. This means that if a variable was uninitialized, it would stay uninitialized in the failed extraction case. However, as of C++11, a failed extraction due to invalid input will cause the variable to be zero-initialized. Zero initialization means the variable is set to 0, 0.0, “”, or whatever value 0 converts to for that type.
Error D: Input extraction succeeds but the user overflows a numeric value.
1
2
3
4
5
6
7
8
9
10
11
12int main() {
std::int16_t x { 0 }; // x is 16 bits, holds from -32768 to 32767
std::cout << "Enter a number between -32768 and 32767: ";
std::cin >> x;
std::int16_t y { 0 }; // y is 16 bits, holds from -32768 to 32767
std::cout << "Enter another number between -32768 and 32767: ";
std::cin >> y;
std::cout << "The sum is: " << x + y << '\n';
return 0;
}1
2Enter a number between -32768 and 32767: 40000
Enter another number between -32768 and 32767: The sum is: 32767In the above case, std::cin goes immediately into “failure mode”, but also assigns the closest in-range value (>= C++11) to the variable. Consequently, x is left with the assigned value of 32767. Additional inputs are skipped, leaving y with the initialized value of 0. We can handle this kind of error in the same way as a failed extraction.
Conclusion
For each point of text input, consider:
- Could extraction fail?
- Could the user enter more input than expected?
- Could the user enter meaningless input?
- Could the user overflow an input?
Remember that the following code will test for and fix failed extractions or overflow:
1 | if (std::cin.fail()) { // has a previous extraction failed or overflowed? |
The following statement will also clear any extraneous input:
1 | std::cin.ignore(32767,'\n'); // and remove the bad input |
Finally, use loops to ask the user to re-enter input if the original input was invalid (meaningless).