Source: LearnCpp.com by Alex
Virtual Functions
Pointers and references to the base class of derived objects
1 | Derived derived(5); |
It turns out that because rBase and pBase are a Base reference and pointer, they can only see members of Base (or any classes that Base inherited). So even though Derived::getName() shadows (hides) Base::getName() for Derived objects, the Base pointer/reference cannot see Derived::getName(). Consequently, they call Base::getName(), which is why rBase and pBase report that they are a Base rather than a Derived.
Note: this also means it is not possible to call Derived::getValueDoubled() using rBase or pBase. They are unable to see anything in Derived.
Want to take a guess what virtual functions are for? :) hhh
Virtual functions and polymorphism
A virtual function is a special type of function that, when called, resolves to the most-derived version of the function that exists between the base and derived class. This capability is known as polymorphism. A derived function is considered a match if it has the same signature (name, parameter types, and whether it is const) and return type as the base version of the function. Such functions are called overrides.
To make a function virtual, simply place the “virtual” keyword before the function declaration.
1 | class Base { |
Because rBase is a reference to the Base portion of a Derived object, when rBase.getName() is evaluated, it would normally resolve to Base::getName(). However, Base::getName() is virtual, which tells the program to go look and see if there are any more-derived versions of the function available between Base and Derived. In this case, it will resolve to Derived::getName().
A word of warning: the signature of the derived class function must exactly match the signature of the base class virtual function in order for the derived class function to be used. If the derived class function has different parameter types, the program will likely still compile fine, but the virtual function will not resolve as intended.
Use of the virtual keyword
If a function is marked as virtual, all matching overrides are also considered virtual, even if they are not explicitly marked as such. However, having the keyword virtual on the derived functions does not hurt, and it serves as a useful reminder that the function is a virtual function rather than a normal one. Consequently, it’s generally a good idea to use the virtual keyword for virtualized functions in derived classes even though it’s not strictly necessary.
Note that: return types must be matched either.
Do not call virtual functions from constructors or destructors
Here’s another gotcha that often catches unsuspecting new programmers. You should not call virtual functions from constructors or destructors. Why?
Remember that when a Derived class is created, the Base portion is constructed first. If you were to call a virtual function from the Base constructor, and Derived portion of the class hadn’t even been created yet, it would be unable to call the Derived version of the function because there’s no Derived object for the Derived function to work on. In C++, it will call the Base version instead.
A similar issue exists for destructors. If you call a virtual function in a Base class destructor, it will always resolve to the Base class version of the function, because the Derived portion of the class will already have been destroyed.
Rule: Never call virtual functions from constructors or destructors
The downside of virtual functions
Since most of the time you’ll want your functions to be virtual, why not just make all functions virtual? The answer is because it’s inefficient – resolving a virtual function call takes longer than resolving a regular one. Furthermore, the compiler also has to allocate an extra pointer for each class object that has one or more virtual functions. We’ll talk about this more in future lessons in this chapter.
The override and final specifiers, and covariant return types
To address some common challenges with inheritance, C++11 added two special identifiers to C++: override and final. Note that these identifiers are not considered keywords – they are normal identifiers that have special meaning in certain contexts.
Although final isn’t used very much, override is a fantastic addition that you should use regularly. In this lesson, we’ll take a look at both, as well as one exception to the rule that virtual function override return types must match.
Consider the following example:
1 | class A { |
In this particular case, because A and B just print their names, it’s fairly easy to see that we messed up our overrides, and that the wrong virtual function is being called. However, in a more complicated program, where the functions have behaviors or return values that aren’t printed, such issues can be very difficult to debug.
To help address the issue of functions that are meant to be overrides but aren’t, C++11 introduced the override specifier. Override can be applied to any override function by placing the specifier in the same place const would go. If the function does not override a base class function, the compiler will flag the function as an error.
Like @Override in Java!
1 | public: |
There is no performance penalty for using the override specifier, and it helps avoid inadvertent errors. Consequently, we highly recommend using it for every virtual function override you write to ensure you’ve actually overridden the function you think you have.
Rule: Apply the override specifier to every intended override function you write.
The final specifier
There may be cases where you don’t want someone to be able to override a virtual function, or inherit from a class. The final specifier can be used to tell the compiler to enforce this. If the user tries to override a function or class that has been specified as final, the compiler will give a compile error.
1 | // class A |
In the case where we want to prevent inheriting from a class, the final specifier is applied after the class name:
1 | class A { |
Covariant return type
There is one special case in which a derived class virtual function override can have a different return type than the base class and still be considered a matching override. If the return type of a virtual function is a pointer or a reference to a class, override functions can return a pointer or a reference to a derived class. These are called covariant return types. Here is an example:
1 | class Base { |
Note: some older compilers (e.g. Visual Studio 6) do not support covariant return types.
One interesting note about covariant return types: C++ can’t dynamically select types, so you’ll always get the type that matches the base version of the function being called.
In the above example, we first call d.getThis(). Since d is a Derived, this calls Derived::getThis(), which returns a Derived*. This Derived* is then used to call non-virtual function Derived::printType().
Now the interesting case. We then call b->getThis(). Variable b is a Base pointer to a Derived object. Base::getThis() is virtual function, so this calls Derived::getThis(). Although Derived::getThis() returns a Derived*, because base version of the function returns a Base*, the returned Derived* is upcast to a Base*. And thus, Base::printType() is called.
In other words, in the above example, you only get a Derived* if you call getThis() with an object that is typed as a Derived object in the first place. (6^6)
Virtual destructors, virtual assignment, and overriding virtualization
Although C++ provides a default destructor for your classes if you do not provide one yourself, it is sometimes the case that you will want to provide your own destructor (particularly if the class needs to deallocate memory). You should always make your destructors virtual if you’re dealing with inheritance. Consider the following example:
1 | // class Base |
However, we really want the delete function to call Derived’s destructor (which will call Base’s destructor in turn), otherwise m_array will not be deleted. We do this by making Base’s destructor virtual:
Using virtual:
1 | class Base { |
Rule: Whenever you are dealing with inheritance, you should make any explicit destructors virtual.
Virtual assignment
It is possible to make the assignment operator virtual. However, unlike the destructor case where virtualization is always a good idea, virtualizing the assignment operator really opens up a bag full of worms and gets into some advanced topics outside of the scope of this tutorial. Consequently, we are going to recommend you leave your assignments non-virtual for now, in the interest of simplicity.
Ignoring virtualization
Very rarely you may want to ignore the virtualization of a function. For example, consider the following code:
1 | class Base { |
There may be cases where you want a Base pointer to a Derived object to call Base::getName() instead of Derived::getName(). To do so, simply use the scope resolution operator:
1 | int main() { |
Should we make all destructors virtual
Two recommendations are as follows:
- If you intend your class to be inherited from, make sure your destructor is virtual.
- If you do not intend your class to be inherited from, mark your class as final. This will prevent other classes from inheriting from it in the first place, without imposing any other use restrictions on the class itself.
Early binding and late binding
Binding refers to the process that is used to convert identifiers (such as variable and function names) into addresses. Although binding is used for both variables and functions, in this lesson we’re going to focus on function binding. (identifiers == symbols?)
Most of the function calls that the compiler encounters will be direct function calls. A direct function call is a statement that directly calls a function. For example:
1 | void printValue(int value) { |
Direct function calls can be resolved using a process known as early binding. Early binding (also called static binding) means the compiler (or linker I think it should be the linker) is able to directly associate the identifier name (such as a function or variable name) with a machine address. Remember that all functions have a unique address. So when the compiler (or linker) encounters a function call, it replaces the function call with a machine language instruction that tells the CPU to jump to the address of the function.
Late Binding
In some programs, it is not possible to know which function will be called until runtime (when the program is run). This is known as late binding (or dynamic binding). In C++, one way to get late binding is to use function pointers. The function that a function pointer points to can be called by using the function call operator (()) on the pointer.
1 | int add(int x, int y) { |
The compiler is unable to use early binding to resolve the function call pFcn(x, y) because it cannot tell which function pFcn will be pointing to at compile time!
Late binding is slightly less efficient since it involves an extra level of indirection.
- With early binding, the CPU can jump directly to the function’s address.
- With late binding, the program has to read the address held in the pointer and then jump to that address. This involves one extra step, making it slightly slower. However, the advantage of late binding is that it is more flexible than early binding, because decisions about what function to call do not need to be made until run time.
The virtual table
To implement virtual functions, C++ uses a special form of late binding known as the virtual table. The virtual table is a lookup table of functions used to resolve function calls in a dynamic/late binding manner. The virtual table sometimes goes by other names, such as vtable, virtual function table, virtual method table, or dispatch table.
First, every class that uses virtual functions (or is derived from a class that uses virtual functions) is given its own virtual table. This table is simply a static array that the compiler sets up at compile time. A virtual table contains one entry for each virtual function that can be called by objects of the class. Each entry in this table is simply a function pointer that points to the most-derived function accessible by that class.
(markdown syntax compromise: *__vptr -> VP)
Second, the compiler also adds a hidden pointer to the base class, which we will call VP. VP is set (automatically) when a class instance is created so that it points to the virtual table for that class. Unlike the *this pointer, which is actually a function parameter used by the compiler to resolve self-references, VP is a real pointer. Consequently, it makes each class object allocated bigger by the size of one pointer. It also means that VP is inherited by derived classes, which is important.
1 | class Base { |
Because there are 3 classes here, the compiler will set up 3 virtual tables: one for Base, one for D1, and one for D2. The compiler also adds a hidden pointer to the most base class that uses virtual functions.
When a class object is created, VP is set to point to the virtual table for that class. For example, when a object of type Base is created, VP is set to point to the virtual table for Base. When objects of type D1 or D2 are constructed, VP is set to point to the virtual table for D1 or D2 respectively (VP is inherited by Base class).
Now, let’s talk about how these virtual tables are filled out. Because there are only two virtual functions here, each virtual table will have two entries (one for function1(), and one for function2()). Remember that when these virtual tables are filled out, each entry is filled out with the most-derived function an object of that class type can call.
The virtual table for Base objects is simple. An object of type Base can only access the members of Base. Base has no access to D1 or D2 functions. Consequently, the entry for function1 points to Base::function1(), and the entry for function2 points to Base::function2().
The virtual table for D1 is slightly more complex. An object of type D1 can access members of both D1 and Base. However, D1 has overridden function1(), making D1::function1() more derived than Base::function1(). Consequently, the entry for function1 points to D1::function1(). D1 hasn’t overridden function2(), so the entry for function2 will point to Base::function2().
The virtual table for D2 is similar to D1, except the entry for function1 points to Base::function1() (because D2 does not override the function), and the entry for function2 points to D2::function2().

1 | D1 d1; |
Note that because dPtr is a base pointer, it only points to the Base portion of d1. However, also note that VP is in the Base portion of the class, so dPtr has access to this pointer. Finally, note that dPtr->__vptr points to the D1 virtual table! Consequently, even though dPtr is of type Base, it still has access to D1’s virtual table (through __vptr).
What happens if we call dPtr->function1()?
1 | D1 d1; |
- First, the program recognizes that function1() is a virtual function.
- Second, the program uses dPtr->__vptr to get to D1’s virtual table.
- Third, it looks up which version of function1() to call in D1’s virtual table. This has been set to D1::function1(). Therefore, dPtr->function1() resolves to D1::function1()!
By using these tables, the compiler and program are able to ensure function calls resolve to the appropriate virtual function, even if you’re only using a pointer or reference to a base class!
Why slower?
Calling a virtual function is slower than calling a non-virtual function for a couple of reasons:
- First, we have to use the *__vptr to get to the appropriate virtual table.
- Second, we have to index the virtual table to find the correct function to call. Only then can we call the function.
- As a result, we have to do 3 operations to find the function to call, as opposed to 2 operations for a normal indirect function call, or one operation for a direct function call. However, with modern computers, this added time is usually fairly insignificant.
Pure virtual functions, abstract base classes, and interface classes
C++ allows you to create a special kind of virtual function called a pure virtual function (or abstract function) that has no body at all! A pure virtual function simply acts as a placeholder that is meant to be redefined by derived classes.
1 | class Base { |
When we add a pure virtual function to our class, we are effectively saying, it is up to the derived classes to implement this function.
Using a pure virtual function has two main consequences:
- First, any class with one or more pure virtual functions becomes an
abstract base class, which means that it cannot be instantiated! - Second, any derived class must define a body for this function, or that derived class will be considered an abstract base class as well.
Also, by making constructor protected, we don’t want people creating Base objects directly; but we still want derived classes to be able to use it.
1 | class Animal { |
When providing a body for a pure virtual function, the body must be provided separately (not inline). This paradigm can be useful when you want your base class to provide a default implementation for a function, but still force any derived classes to provide their own implementation. However, if the derived class is happy with the default implementation provided by the base class, it can simply call the base class implementation directly. For example:
1 | virtual const char* speak() { |
Interface classes
An interface class is a class that has no member variables, and where all of the functions are pure virtual! In other words, the class is purely a definition, and has no actual implementation. Interfaces are useful when you want to define the functionality that derived classes must implement, but leave the details of how the derived class implements that functionality entirely up to the derived class.
1 | class IErrorLog { |
Because interfaces have no data and no function bodies, they avoid a lot of the traditional problems with multiple inheritance while still providing much of the flexibility.
Pure virtual functions and the virtual table
Abstract classes still have virtual tables, as these can still be used if you have a pointer or reference to the abstract class. The virtual table entry for a pure virtual function will generally either contain a null pointer, or point to a generic function that prints an error (sometimes this function is named __purecall) if no override is provided.
Virtual base classes
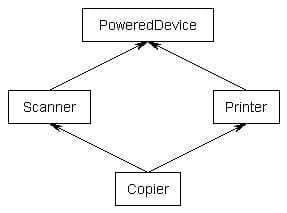
Diamond Problem (Multi-inheritance)

1 | class PoweredDevice { |
If you were to create a Copier class object, by default you would end up with two copies of the PoweredDevice class – one from Printer, and one from Scanner. This has the following structure:
1 | int main() { |
As you can see, PoweredDevice got constructed twice. To share a base class, simply insert the “virtual” keyword in the inheritance list of the derived class. This creates what is called a virtual base class, which means there is only one base object that is shared. Here is an example (without constructors for simplicity) showing how to use the virtual keyword to create a shared base class:
1 | class Powered Device {}; |
Now, when you create a Copier class, you will get only one copy of PoweredDevice that will be shared by both Scanner and Printer.
However, this leads to one more problem: if Scanner and Printer share a PoweredDevice base class, who is responsible for creating it? The answer, as it turns out, is Copier. The Copier constructor is responsible for creating PoweredDevice. Consequently, this is one time when Copier is allowed to call a non-immediate-parent constructor directly.
Note that:
First, virtual base classes are always created before non-virtual base classes, which ensures all bases get created before their derived classes.
Second, note that the Scanner and Printer constructors still have calls to the PoweredDevice constructor. When creating an instance of Copier, these constructor calls are simply ignored because Copier is responsible for creating the PoweredDevice, not Scanner or Printer. However, if we were to create an instance of Scanner or Printer, those constructor calls would be used, and normal inheritance rules apply.
Third, if a class inherits one or more classes that have virtual parents, the most derived class is responsible for constructing the virtual base class. In this case, Copier inherits Printer and Scanner, both of which have a PoweredDevice virtual base class. Copier, the most derived class, is responsible for creation of PoweredDevice. Note that this is true even in a single inheritance case: if Copier was singly inherited from Printer, and Printer was virtually inherited from PoweredDevice, Copier is still responsible for creating PoweredDevice.
Fourth, all classes inheriting a virtual base class will have a virtual table, even if they would normally not have one otherwise, and thus be larger by a pointer.
Because Scanner and Printer derive virtually from PoweredDevice, Copier will only be one PoweredDevice subobject. Scanner and Printer both need to know how to find that single PoweredDevice subobject, so they can access its members (because after all, they are derived from it). This is typically done through some virtual table magic (which essentially stores the offset from each subclass to the PoweredDevice subobject).
Object slicing
What happens if instead of setting a Base reference or pointer to a Derived object, we simply assign a Derived object to a Base object?
1 | Derived derived(5); |
Remember that derived has a Base part and a Derived part. When we assign a Derived object to a Base object, only the Base portion of the Derived object is copied. The Derived portion is not. In the example above, base receives a copy of the Base portion of derived, but not the Derived portion. That Derived portion has effectively been “sliced off”. Consequently, the assigning of a Derived class object to a Base class object is called object slicing (or slicing for short).
Because variable base does not have a Derived part, base.getName() resolves to Base::getName().
Used conscientiously, slicing can be benign. However, used improperly, slicing can cause unexpected results in quite a few different ways.
Example:
1 | // class Derived |
When you wrote this program, you may not have noticed that base is a value parameter, not a reference. Therefore, when called as printName(d), we might have expected base.getName() to call virtualized function getName() and print “I am a Derived”, that is not what happens. Instead, Derived object d is sliced and only the Base portion is copied into the base parameter. When base.getName() executes, even though the getName() function is virtualized, there’s no Derived portion of the class for it to resolve to.
Slicing vectors (std::reference_wrapper<>)
Yet another area where new programmers run into trouble with slicing is trying to implement polymorphism with std::vector. Consider the following program:
1 | std::vector<Base> v; |
Fixing this is a little more difficult. Many new programmers try creating a std::vector of references to an object. Unfortunately, this won’t compile. The elements of std::vector must be re-assignable, whereas references can’t be reassigned (only initialized).
1 | std::vector<Base*> v; |
But it’s quite a bit of additional headache since you now have to deal with dynamic memory allocation.
There’s one other way to resolve this. The standard library provides a useful workaround: the std::reference_wrapper class. Essentially, std::reference_wrapper is a class that acts like a reference, but also allows assignment and copying, so it’s compatible with std::vector.
The good news is that you don’t really need to understand how it works to use it. All you need to know are three things:
- std::reference_wrapper lives in the
<functional>header - When you create your std::reference_wrapper wrapped object, the object
can't be an anonymous object(since anonymous objects have expression scope would leave the reference dangling) - When you want to get your object back out of std::reference_wrapper, you use the
get()member function.
1 | std::vector< std::reference_wrapper<Base> > v; |
The Frankenobject
In the above examples, we’ve seen cases where slicing lead to the wrong result because the derived class had been sliced off. Now let’s take a look at another dangerous case where the derived object still exists!
Consider the following code:
1 | Derived d1(5); |
The first three lines in the function are pretty straightforward. Create two Derived objects, and set a Base reference to the second one.
The fourth line is where things go astray. Since b points at d2, and we’re assigning d1 to b, you might think that the result would be that d1 would get copied into d2 – and it would, if b were a Derived. But b is a Base, and the operator= that C++ provides for classes isn’t virtual by default. Consequently, only the Base portion of d1 is copied into d2.
As a result, you’ll discover that d2 now has the Base portion of d1 and the Derived portion of d2. In this particular example, that’s not a problem (because the Derived class has no data of its own), but in most cases, you’ll have just created a Frankenobject – composed of parts of multiple objects. Worse, there’s no easy way to prevent this from happening (other than avoiding assignments like this as much as possible).
Note: (In non-inheritance case, types are not matched)
1 | class Test1 {}; |
Although C++ supports assigning derived objects to base objects via object slicing, in general, this is likely to cause nothing but headaches, and you should generally try to avoid slicing. Make sure your function parameters are references (or pointers) and try to avoid any kind of pass-by-value when it comes to derived classes.
Note: when reassigning references or objects, consider potential object-slicing problems.
Dynamic casting (downcasting)
The need for dynamic_cast
When dealing with polymorphism, you’ll often encounter cases where you have a pointer to a base class, but you want to access some information that exists only in a derived class.
In a program, function getObject() always returns a Base pointer, but that pointer may be pointing to either a Base or a Derived object. In the case where the pointer is pointing to a Derived object, how would we call Derived::getName()?
(Base doesn’t have getName(), m_name members)
One way would be to add a virtual function to Base called getName() (so we could call it with a Base object, and have it dynamically resolve to Derived::getName()). But what would this function return if you called it with a Base object? There isn’t really any value that makes sense. Furthermore, we would be polluting our Base class with things that really should only be the concern of the Derived class.
C++ provides a casting operator named dynamic_cast that can be used for downcasting. Although dynamic casts have a few different capabilities, by far the most common use for dynamic casting is for converting base-class pointers into derived-class pointers.
1 | Base *b = getObject(true); // true means return a pointer to Base object |
dynamic_cast failure
But the above situation makes an assumption that b is pointing to a Derived object! When we try to dynamic_cast that to a Derived, it will fail, because the conversion can’t be made.
If a dynamic_cast fails, the result of the conversion will be a null pointer.
Because we haven’t checked for a null pointer result, we access d->getName(), which will try to dereference a null pointer, leading to undefined behavior (probably a crash).
Rule: Always ensure your dynamic casts actually succeeded by checking for a null pointer result.
Note that because dynamic_cast does some consistency checking at runtime (to ensure the conversion can be made), use of dynamic_cast does incur a performance penalty.
Also note that there are several cases where downcasting using dynamic_cast will not work:
- With
protectedorprivateinheritance. - For classes that do not declare or inherit any virtual functions (and thus don’t have a virtual table).
- although we set functions virtual in the base class, there is no virtual table (but a null VP pointer) if we don’t override the virtual functions (note: we don’t need to specify the virutal keyword in the subclass)
- In certain cases involving virtual base classes (see this page for an example of some of these cases, and how to resolve them).
Downcasting with static_cast
It turns out that downcasting can also be done with static_cast. The main difference is that static_cast does no runtime type checking to ensure that what you’re doing makes sense. This makes using static_cast faster, but more dangerous. If you cast a Base* to a Derived*, it will “succeed” even if the Base pointer isn’t pointing to a Derived object. This will result in undefined behavior when you try to access the resulting Derived pointer (that is actually pointing to a Base object).
If you’re absolutely sure that the pointer you’re downcasting will succeed, then using static_cast is acceptable. One way to ensure that you know what type of object you’re pointing to is to use a virtual function to indicate a type of a class. Here’s one (not great because it uses a global variable) way to do that:
1 | enum ClassID { |
dynamic_cast and references
Although all of the above examples show dynamic casting of pointers (which is more common), dynamic_cast can also be used with references. This works analogously to how dynamic_cast works with pointers.
Because C++ does not have a “null reference”, dynamic_cast can’t return a null reference upon failure. Instead, if the dynamic_cast of a reference fails, an exception of type std::bad_cast is thrown.
dynamic_cast vs static_cast
New programmers are sometimes confused about when to use static_cast vs dynamic_cast. The answer is quite simple: use static_cast unless you’re downcasting, in which case dynamic_cast is usually a better choice. However, you should also consider avoiding casting altogether and just using virtual functions.
Downcasting vs virtual functions
There are some developers who believe dynamic_cast is evil and indicative of a bad class design. Instead, these programmers say you should use virtual functions.
In general, using a virtual function should be preferred over downcasting. However, there are times when downcasting is the better choice:
- When you cannot modify the base class to add a virtual function
(e.g. because the base class is part of the standard library) - When you need access to something that is derived-class specific
(e.g. an access function that only exists in the derived class which means not using polymorphism) - When adding a virtual function to your base class doesn’t make sense
(e.g. there is no appropriate value for the base class to return). Using a pure virtual function may be an option here if you don’t need to instantiate the base class.
Printing inherited classes using operator<<
1 | class Base { |
Our purpose is like this:
1 | std::cout << "b is a " << b << '\n'; // much better |
Let’s start by overloading operator<< in the typical way:
1 |
|
Can we make operator<< virtual? No!
- First, only member functions can be virtualized.
- Second, even if we could virtualize operator<< there’s the problem that the function parameters for Base::operator<< and Derived::operator<< differ. Consequently, the Derived version wouldn’t be considered an override of the Base version, and thus be ineligible for virtual function resolution.
The solution
First, we set up operator<< as a friend in our base class as usual. But instead of having operator<< do the printing itself, we delegate that responsibility to a normal member function that can be virtualized!
Here’s the full solution that works:
1 |
|
Templates
Function templates
1 | int max(int x, int y) { |
Having to specify different “flavors” of the same function where the only thing that changes is the type of the parameters can become a maintenance headache and time-waster, and it also violates the general programming guideline that duplicate code should be minimized as much as possible. Wouldn’t it be nice if we could write one version of max() that was able to work with parameters of ANY type?
In C++, function templates are functions that serve as a pattern for creating other similar functions. The basic idea behind function templates is to create a function without having to specify the exact type(s) of some or all of the variables. Instead, we define the function using placeholder types, called template type parameters. Once we have created a function using these placeholder types, we have effectively created a “function stencil”.
When you call a template function, the compiler “stencils” out a copy of the template, replacing the placeholder types with the actual variable types from the parameters in your function call! Using this methodology, the compiler can create multiple “flavors” of a function from one template! We’ll take a look at this process in more detail in the next lesson.
You can name your placeholder types almost anything you want, so long as it’s not a reserved word. However, in C++, it’s customary to name your template types the letter T (short for “Type”).
1 | T max(T x, T y) { |
In order to make this work, we need to tell the compiler two things: First, that this is a template definition. Second, that T is a placeholder type. We can do both of those things in one line, using what is called a template parameter declaration:
1 | template <typename T> // this is the template parameter declaration |
To create a template type parameter, use either the keyword typename or class. There is no difference between the two keywords in this context, so which you use is up to you. Note that if you use the class keyword, the type passed in does not actually have to be a class (it can be a fundamental variable, pointer, or anything else that matches). Then you name your type (usually “T”, “T1”, “T2”, “S”).
One final note: Because the function argument passed in for type T could be a class type, and it’s generally not a good idea to pass classes by value, it would be better to make the parameters and return types of our templated function const references:
1 | template <typename T> |
Function template instances
C++ does not compile the template function directly. Instead, at compile time, when the compiler encounters a call to a template function, it replicates the template function and replaces the template type parameters with actual types. The function with actual types is called a function template instance.
1 | template <typename T> |
When compiling your program, the compiler encounters a call to the template function:
1 | int i = max(3, 7); // calls max(int, int) |
The compiler says, “oh, we want to call max(int, int)”. The compiler replicates the function template and creates the template instance max(int, int):
1 | const int& max(const int &x, const int &y) { |
The compiler is smart enough to know it only needs to create one template instance per set of unique type parameters (per file). It’s also worth noting that if you create a template function but do not call it, no template instances will be created.
Using template with classes:
1 | template <typename T> |
The complier will try to compile this function. See the problem here? C++ has no idea how to evaluate x > y! Consequently, this will produce a fairly-tame looking compile error, like this:
1 | error C2676: binary '>': 'const Cents' does not define this operator or a conversion to a type acceptable to the predefined operator |
To get around this problem, simply overload the operator > for any class we wish to use max() with:
1 | friend bool operator>(const Cents &c1, const Cents &c2) { |
Another example:
Calculate the average of a number of objects in an array:
1 | template <class T> |
Now let’s see what happens when we call this function on our Cents class:
1 | // same as above |
The compiler goes berserk and produces a ton of error messages!
1 | c:\consoleapplication1\main.cpp(55): error C2679: binary '<<': no operator found which takes a right-hand operand of type 'Cents' (or there is no acceptable conversion) |
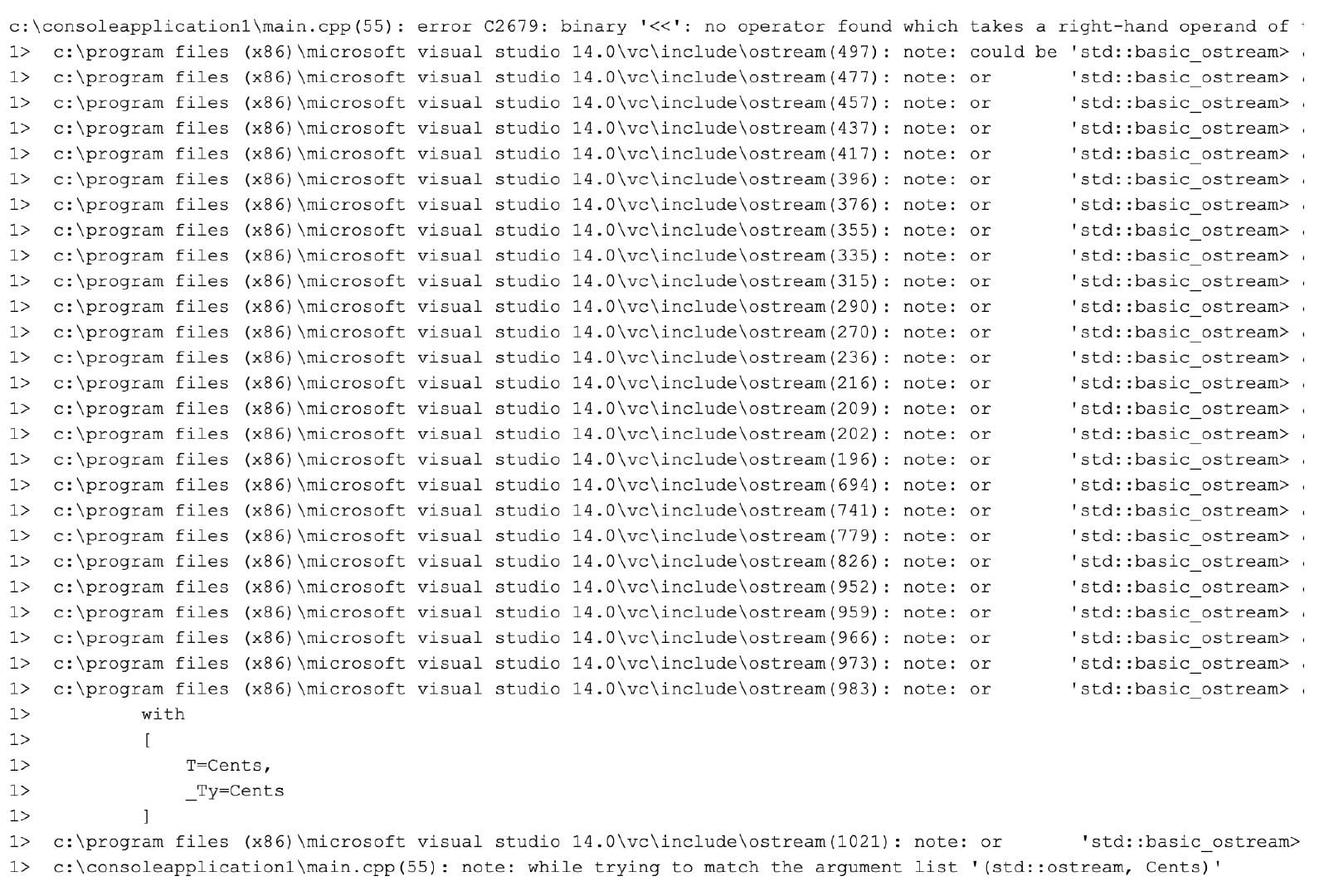
Remember what I said about crazy error messages? We hit the motherload! Despite looking intimidating, these are actually quite straightforward. The first line is telling you that it couldn’t find an overloaded operator<< for the Cents class. All of the lines in the middle are all of the different functions it tried to match with but failed. The last error points out the function call that spawned this wall of errors.
Remember that average() returns a Cents object, and we are trying to stream that object to std::cout using the << operator. However, we haven’t defined the << operator for our Cents class yet. Let’s do that:
1 | class Cents { |
Then it shows another error:
1 | c:test.cpp(14) : error C2676: binary '+=' : 'Cents' does not define this operator or a conversion to a type acceptable to the predefined operator |
The reason we are getting an error message is because of the following line: sum += array[count];
1 | // overloaded member function |
Remember in the above examples, we barely modify our templates to achieve our goals.
Template classes
Templates and container classes
Combine IntArray and DoubleArray classes.
1 | template <class T> // This is a template class, the user will provide the data type for T |
Note that we’ve also defined the getLength() function outside of the class declaration. This isn’t necessary, but new programmers typically stumble when trying to do this for the first time due to the syntax, so an example is instructive. Each templated member function declared outside the class declaration needs its own template declaration. Also, note that the name of the templated array class is Array
1 | // short example |
Template classes are instanced in the same way template functions are – the compiler stencils out a copy upon demand, with the template parameter replaced by the actual data type the user needs, and then compiles the copy. If you don’t ever use a template class, the compiler won’t even compile it.
Template classes are ideal for implementing container classes, because it is highly desirable to have containers work across a wide variety of data types, and templates allow you to do so without duplicating code. Although the syntax is ugly, and the error messages can be cryptic, template classes are truly one of C++’s best and most useful features.
Splitting up template classes
A template is not a class or a function – it is a stencil used to create classes or functions. As such, it does not work in quite the same way as normal functions or classes. In most cases, this isn’t much of an issue. However, there is one area that commonly causes problems for developers.
With non-template classes, the common procedure is to put the class definition in a header file, and the member function definitions in a similarly named code file. In this way, the source for the class is compiled as a separate project file. However, with templates, this does not work. Consider this example:
Array.h:
1 | template <class T> |
Array.cpp:
1 |
|
main.cpp:
1 | Array<int> intArray(12); |
The above program will compile, but cause a linker error:
1 | unresolved external symbol "public: int __thiscall Array::getLength(void)" (?GetLength@?$Array@H@@QAEHXZ) |
In order for the compiler to use a template, it must see both the template definition (not just a declaration) and the template type used to instantiate the template.
Also remember that C++ compiles files individually. When the Array.h header is #included in main.cpp, the template class definition is copied into main.cpp. When the compiler sees that we need two template instances, Array<int>, and Array<double>, it will instantiate these, and compile them as part of main.cpp. However, when it gets around to compiling Array.cpp separately, it will have forgotten that we need an Array<int> and Array<double>, so that template function is never instantiated. Thus, we get a linker error, because the compiler can’t find a definition for Array<int>::getLength() or Array<double>::getLength().
The easiest way is to simply put all of your template class code in the header file (in this case, put the contents of Array.cpp into Array.h, below the class). In this way, when you #include the header, all of the template code will be in one place. The upside of this solution is that it is simple. The downside here is that if the template class is used in many places, you will end up with many local copies of the template class, which can increase your compile and link times (your linker should remove the duplicate definitions, so it shouldn’t bloat your executable). This is our preferred solution unless the compile or link times start to become a problem.
If you feel that putting the Array.cpp code into the Array.h header makes the header too long/messy, an alternative is to rename Array.cpp to Array.inl (.inl stands for inline), and then include Array.inl from the bottom of the Array.h header. That yields the same result as putting all the code in the header, but helps keep things a little cleaner.
Other solutions involve #including .cpp files in .h files, but we don’t recommend these because of the non-standard usage of #include.
Another alternative is to use a three-file approach. The template class definition goes in the header. The template class member functions goes in the code file. Then you add a third file, which contains all of the instantiated classes you need:
templates.cpp:
1 | // Ensure the full Array template definition can be seen |
The template class command causes the compiler to explicitly instantiate the template class. In the above case, the compiler will stencil out both Array<int> and Array<double> inside of templates.cpp. Because templates.cpp is inside our project, this will then be compiled. These functions can then be linked to from elsewhere.
Non-type parameters
In previous lessons, you’ve learned how to use template type parameters to create functions and classes that are type independent. However, template type parameters are not the only type of template parameters available. Template classes and functions can make use of another kind of template parameter known as a non-type parameter.
Non-type parameters
A template non-type parameter is a special type of parameter that does not substitute for a type, but is instead replaced by a value. A non-type parameter can be any of the following:
- A value that has an
integertype orenumeration - A pointer or reference to a class object
- A pointer or reference to a function
- A pointer or reference to a class member function
- std::nullptr_t
In the following example, we create a StaticArray class that uses both a type parameter and a non-type parameter. The type parameter controls the data type of the array, and the non-type parameter controls how large the static array is.
1 | template <class T, int size> // size is the non-type parameter |
One noteworthy thing about the above example is that we do not have to dynamically allocate the m_array member variable! This is because for any given instance of the StaticArray class, size is actually constant. For example, if you instantiate a StaticArray<int, 12>, the compiler replaces size with 12. Thus m_array is of type int[12], which can be allocated statically. (happens in compile time)
This functionality is used by the standard library class std::array. When you allocate a std::array<int, 5>, the int is a type parameter, and the 5 is a non-type parameter!
Function template specialization
When instantiating a function template for a given type, the compiler stencils out a copy of the templated function and replaces the template type parameters with the actual types used in the variable declaration. This means a particular function will have the same implementation details for each instanced type (just using different types). While most of the time, this is exactly what you want, occasionally there are cases where it is useful to implement a templated function slightly different for a specific data type.
Template specialization is one way to accomplish this.
1 | template <class T> |
Now, let’s say we want double values (and only double values) to output in scientific notation. To do so, we can use a function template specialization (sometimes called a full or explicit function template specialization) to create a specialized version of the print() function for type double. This is extremely simple: simply define the specialized function (if the function is a member function, do so outside of the class definition), replacing the template type with the specific type you wish to redefine the function for. Here is our specialized print() function for doubles:
1 | template <> |
When the compiler goes to instantiate Storage<double>::print(), it will see we’ve already explicitly defined that function, and it will use the one we’ve defined instead of stenciling out a version from the generic templated class.
The template <> tells the compiler that this is a template function, but that there are no template parameters (since in this case, we’re explicitly specifying all of the types). Some compilers may allow you to omit this, but it’s proper to include it.
Another example:
1 | // continue |
As it turns out, instead of printing the name the user input, storage.print() prints garbage! What’s going on here?
When Storage is instantiated for type char*, the constructor for Storage<char*> looks like this:
1 | template <> |
1 | // fixed |
Class template specialization
It is not only possible to specialize functions, it is also possible to specialize an entire class!
Consider the case where you want to design a class that stores 8 objects. Here’s a simplified class to do so:
1 | template <class T> |
Consider when we use it to store bool:
1 | Storage8<bool> boolStorage; |
A variable of type bool ends up using an entire byte even though technically it only needs a single bit to store its true or false value! Thus, a bool is 1 bit of useful information and 7 bits of wasted space. Our Storage8<bool> class, which contains 8 bools, is 1 byte worth of useful information and 7 bytes of wasted space.
As it turns out, using some basic bit logic, it’s possible to compress all 8 bools into a single byte, eliminating the wasted space altogether. However, in order to do this, we’ll need to revamp the class when used with type bool, replacing the array of 8 bools with a variable that is a single byte in size. While we could create an entirely new class to do so, this has one major downside: we have to give it a different name. Then the programmer has to remember that Storage8<T> is meant for non-bool types, whereas Storage8Bool (or whatever we name the new class) is meant for bools. That’s needless complexity we’d rather avoid. Fortunately, C++ provides us a better method: class template specialization.
Class template specialization
Class template specializations are treated as completely independent classes, even though they are allocated in the same way as the templated class. This means that we can change anything and everything about our specialization class, including the way it’s implemented and even the functions it makes public, just as if it were an independent class. Here’s our specialized class:
1 | template <> |
Note that we start off with template<>. The template keyword tells the compiler that what follows is templated, and the empty angle braces means that there aren’t any template parameters. In this case, there aren’t any template parameters because we’re replacing the only template parameter (typename T) with a specific type (bool).
Now:
- When we declare a class of type
Storage8<T>, where T is not a bool, we’ll get a version stenciled from the generic templatedStorage8<T>class. - When we declare a class of type
Storage8<bool>, we’ll get the specialized version we just created.
Note: we have kept the publicly exposed interface of both classes the same – while C++ gives us free reign to add, remove, or change functions of Storage8<bool> as we see fit, keeping a consistent interface means the programmer can use either class in exactly the same manner.
Partial template specialization
Let’s take another look at the Static Array class we used in one of our previous examples:
1 | template <class T, int size> // type parameter & expression parameter |
Now, let’s say we wanted to write a function to print out the whole array. Although we could implement this as a member function, we’re going to do it as a non-member function instead because it will make the successive examples easier to follow.
1 | template <typename T, int size> |
Although this works, it has a design flaw. Consider the following:
1 | StaticArray<char, 14> char14; |
For non-char types, it makes sense to put a space between each array element, so they don’t run together. However, with a char type, it makes more sense to print everything run together as a C-style string, which our print() function doesn’t do.
One might first think of using template specialization. The problem with full template specialization is that all template parameters must be explicitly defined.
1 | template <typename T, int size> |
Although this solves the issue of making sure print() can be called with a StaticArray<char, 14>, it brings up another problem: using full template specialization means we have to explicitly define the length of the array this function will accept! Consider the following example:
1 | StaticArray<char, 12> char12; |
Calling print() with <char, 12> will call the version of print() that takes a StaticArray<T, size>, because <char, 12> is of type StaticArray<char, 12>, and our overloaded print() will only be called when passed a StaticArray<char, 14>.
Although we could make a copy of print() that handles StaticArray<char, 12>, what happens when we want to call print() with an array size of 5, or 22? We’d have to copy the function for each different array size. That’s redundant.
Obviously full template specialization is too restrictive a solution here. The solution we are looking for is partial template specialization.
Partial template specialization
Partial template specialization allows us to specialize classes (but not individual functions!) where some, but not all, of the template parameters have been explicitly defined. For our challenge above, the ideal solution would be to have our overloaded print function work with StaticArray of type char, but leave the length expression parameter templated so it can vary as needed. Partial template specialization allows us to do just that!
1 | template <int size> |
As you can see here, we’ve explicitly declared that this function will only work for StaticArray of type char, but size is still a templated expression parameter, so it will work for char arrays of any size. That’s all there is to it!
Again, print is not a member function here.
Note that as of C++14, partial template specialization can only be used with classes, not template functions (functions must be fully specialized). Our void print(StaticArray<char, size> &array) example works because the print function is not partially specialized (it’s just an overloaded function using a class parameter that’s partially specialized).
Here’s a full program:
1 |
|
Partial template specialization for member functions
The limitation on the partial specialization of functions can lead to some challenges when dealing with member functions. For example, what if we had defined StaticArray like this?
1 | public: |
Partially specialize print():
1 | // Doesn't work |
So how do we get around this? One obvious way is to partially specialize the entire class:
1 | template <class T, int size> |
While it works, this isn’t a great solution, because we had to duplicate a lot of code from StaticArray<T, size> to StaticArray<double, size>.
If only there were some way to reuse the code in StaticArray<T, size> in StaticArray<double, size>. Sounds like a job for inheritance!
You might start off trying to write that code like this:
1 | template <int size> // size is the expression parameter |
Fortunately, there’s a workaround, by using a common base class:
1 | template <class T, int size> |
This prints the same as above, but has significantly less duplicated code.
Partial template specialization for pointers
1 | template <class T> |
We showed that this class had problems when template parameter T was of type char* because of the shallow copy/pointer assignment that takes place in the constructor. In that lesson, we used full template specialization to create a specialized version of the Storage constructor for type char* that allocated memory and created an actual deep copy of m_value. For reference, here’s the fully specialized char* Storage constructor and destructor:
1 | template <> // fully specialized |
While that worked great for Storage<char*>, what about other pointer types (such as int*)? It’s fairly easy to see that if T is any pointer type, then we run into the problem of the constructor doing a pointer assignment instead of making an actual deep copy of the element being pointed to.
Because full template specialization forces us to fully resolve templated types, in order to fix this issue we’d have to define a new specialized constructor (and destructor) for each and every pointer type we wanted to use Storage with! This leads to lots of duplicate code, which as you well know by now is something we want to avoid as much as possible.
Fortunately, partial template specialization offers us a convenient solution. In this case, we’ll use class partial template specialization to define a special version of the Storage class that works for pointer values. This class is considered partially specialized because we’re telling the compiler that it’s only for use with pointer types, even though we haven’t specified the underlying type exactly.
1 | template <typename T> |
When myintptr is defined with an int* template parameter, the compiler sees that we have defined a partially specialized template class that works with any pointer type, and instantiates a version of Storage using that template.
It’s worth noting that because this partially specialized Storage class only allocates a single value, for C-style strings, only the first character will be copied. If the desire is to copy entire strings, a specialization of the constructor (and destructor) for type char* can be fully specialized. The fully specialized version will take precedence over the partially specialized version. Here’s an example program that uses both partial specialization for pointers, and full specialization for char*:
1 | template <class T> |
Using partial template class specialization to create separate pointer and non-pointer implementations of a class is extremely useful when you want a class to handle both differently, but in a way that’s completely transparent to the end-user.