Source: LearnCpp.com by Alex
Exceptions
Basic exception handling
Three keywords: throw, try, and catch.
Throwing / raising exceptions
1 | throw -1; |
Once an exception has been caught by the try block and routed to a catch block for handling, the exception is considered handled, and execution will resume as normal after the catch block.
Catch parameters work just like function parameters, with the parameter being available within the subsequent catch block. Exceptions of fundamental types can be caught by value, but exceptions of non-fundamental types should be caught by const reference to avoid making an unnecessary copy.
1 | int main() { |
Recapping exception handling
Exception handling is actually quite simple, and the following two paragraphs cover most of what you need to remember about it:
When an exception is raised (using throw), execution of the program immediately jumps to the nearest enclosing try block (propagating up the stack if necessary to find an enclosing try block – we’ll discuss this in more detail next lesson). If any of the catch handlers attached to the try block handle that type of exception, that handler is executed and the exception is considered handled.
If no appropriate catch handlers exist, execution of the program propagates to the next enclosing try block. If no appropriate catch handlers can be found before the end of the program, the program will fail with an exception error.
Note that the compiler will not perform implicit conversions or promotions when matching exceptions with catch blocks! For example, a char exception will not match with an int catch block. An int exception will not match a float catch block.
That’s really all there is to it. The rest of this chapter will be dedicated to showing examples of these principles at work.
Exceptions are handled immediately
1 | try { |
What catch blocks typically do
- First, catch blocks may print an error (either to the console, or a log file).
- Second, catch blocks may return a value or error code back to the caller.
- Third, a catch block may
throw another exception. Because the catch block is outside of the try block, the newly thrown exception in this case is not handled by the preceding try block – it’s handled by the next enclosing try block.
Exceptions, functions, and stack unwinding
In the examples in the previous lesson, the throw statements were placed directly within a try block. If this were a necessity, exception handling would be of limited use.
One of the most useful properties of exception handling is that the throw statements do NOT have to be placed directly inside a try block due to the way exceptions propagate up the stack when thrown. This allows us to use exception handling in a much more modular fashion. We’ll demonstrate this by rewriting the square root program from the previous lesson to use a modular function.
1 | double mySqrt(double x) { |
It does work! Let’s revisit for a moment what happens when an exception is raised.
- First, the program looks to see if the exception can be handled immediately (which means it was thrown
inside a try block). - If not, the current function is terminated, and the program checks to see if the
function's callerwill handle the exception (within the same try/catch block). - If not, it terminates the caller and checks the caller’s caller.
Each function is terminated in sequence until a handler for the exception is found, or until main() is terminated without the exception being handled. This process is called unwinding the stack (see the lesson on the stack and the heap if you need a refresher on what the call stack is).
By passing the error back up the stack, each application can handle an error from mySqrt() in a way that is the most context appropriate for it! Ultimately, this keeps mySqrt() as modular as possible, and the error handling can be placed in the less-modular parts of the code.
Uncaught exceptions, catch-all handlers, and exception specifiers
When main() terminates with an unhandled exception, the operating system will generally notify you that an unhandled exception error has occurred. How it does this depends on the operating system, but possibilities include printing an error message, popping up an error dialog, or simply crashing. Some OSes are less graceful than others. Generally this is something you want to avoid altogether!
C++ provides us with a mechanism to catch all types of exceptions. This is known as a catch-all handler. A catch-all handler works just like a normal catch block, except that instead of using a specific type to catch, it uses the ellipses operator (…) as the type to catch.
1 | try { |
Often, the catch-all handler block is left empty:
catch(…) {} // ignore any unanticipated exceptions
This will catch any unanticipated exceptions and prevent them from stack unwinding to the top of your program, but does no specific error handling.
Using the catch-all handler to wrap main()
1 | int main() { |
It gives us a chance to print an error of our choosing and then save the user's state before exiting. This can be useful to catch and handle problems that may be unanticipated.
Exception specifiers
This subsection should be considered optional reading because exception specifiers are rarely used in practice, are not well supported by compilers, and Bjarne Stroustrup (the creator of C++) considers them a failed experiment.
Exception specifiers are a mechanism that allows us to use a function declaration to specify whether a function may or will not throw exceptions. This can be useful in determining whether a function call needs to be put inside a try block or not. (In Java?)
First, we can use an empty throw statement to denote that a function does not throw any exceptions outside of itself:
1 | int doSomething() throw(); // does not throw exceptions |
Note that doSomething() can still use exceptions as long as they are handled internally. Any function that is declared with throw() is supposed to cause the program to terminate immediately if it does try to throw an exception outside of itself, but implementation is spotty.
Second, we can use a specific throw statement to denote that a function may throw a particular type of exception:
1 | int doSomething() throw(double); // may throw a double |
Finally, we can use a catch-all throw statement to denote that a function may throw an unspecified type of exception:
1 | int doSomething() throw(...); // may throw anything |
Due to the incomplete compiler implementation, the fact that exception specifiers are more like statements of intent than guarantees, some incompatibility with template functions, and the fact that most C++ programmers are unaware of their existence, I recommend you do not bother using exception specifiers.
C++11 added a fourth exception specifier that is actually getting some use: noexcept. Noexcept is a exception specifier that is used to indicate that a function can not throw an exception. Semantically, it allows you to see at a glance that a function will not throw an exception. It also potentially enables some compiler optimizations. Destructors are generally implicitly noexcept (as they can’t throw an exception). If a noexcept function does try to throw an exception, then std::terminate is called to terminate the application.
Proper application of noexcept is non-trivial, and probably warrants its own lesson, so we’ll leave it here – as a mention that it exists, but as a topic for advanced users to explore further.
Exceptions, classes, and inheritance
Exceptions and member functions
1 | int& IntArray::operator[] (const int index) { |
Now if the user passes in an invalid index, the program will cause an assertion error. While this is useful to indicate to the user that something went wrong, sometimes the better course of action is to fail silently and let the caller know something went wrong so they can deal with it as appropriate.
Unfortunately, because overloaded operators have specific requirements as to the number and type of parameter(s) they can take and return, there is no flexibility for passing back error codes or boolean values to the caller. However, since exceptions do not change the signature of a function, they can be put to great use here. Here’s an example:
1 | int& IntArray::operator[] (const int index) { |
Constructors are another area of classes in which exceptions can be very useful. If a constructor must fail for some reason (e.g. the user passed in invalid input), simply throw an exception to indicate the object failed to create. In such a case, the object’s construction is aborted, and all class members (which have already been created and initialized prior to the body of the constructor executing) are destructed as per usual. However, the class's destructor is never called (because the object never finished construction).
Because the destructor never executes, you can not rely on said destructor to clean up any resources that have already been allocated. Any such cleanup can happen in the constructor prior to throwing the exception in the first place. However, even better, because the members of the class are destructed as per usual, if you do the resource allocations in the members themselves, then those members can clean up after themselves when they are destructed.
1 | class Member; |
In the above program, when class A throws an exception, all of the members of A are destructed. This gives m_member an opportunity to clean up any resources that were allocated. This is part of the reason that RAII is advocated so highly.
Recap:
RAII (Resource Acquisition Is Initialization) is a programming technique whereby resource use is tied to the lifetime of objects with automatic duration (e.g. non-dynamically allocated objects). In C++, RAII is implemented via classes with constructors and destructors. (allocation in the constructor, deallocation in the destructor!)
Under the RAII paradigm, objects holding resources should not be dynamically allocated. This is because destructors are only called when an object is destroyed. For objects allocated on the stack, this happens automatically when the object goes out of scope, so there’s no need to worry about a resource eventually getting cleaned up. However, for dynamically allocated objects, the user is responsible for deletion – if the user forgets to do that, then the destructor will not be called, and the memory for both the class object and the resource being managed will be leaked!
Rule: If your class dynamically allocates memory, use the RAII paradigm, and don’t allocate objects of your class dynamically
Exception classes
One of the major problems with using basic data types (such as int) as exception types is that they are inherently vague.
1 | try { |
Exception class is just a normal class that is designed specifically to be thrown as an exception.
1 | class ArrayException { |
Note that exception handlers should catch class exception objects by reference instead of by value. This prevents the compiler from making a copy of the exception, which can be expensive when the exception is a class object, and prevents object slicing when dealing with derived exception classes (which we’ll talk about in a moment). Catching exceptions by pointer should generally be avoided unless you have a specific reason to do so.
Exceptions and inheritance
1 | try { |
Rule: Handlers for derived exception classes should be listed before those for base classes.
std::exception
Many of the classes and operators in the standard library throw exception classes on failure. For example, operator new and std::string can throw std::bad_alloc if they are unable to allocate enough memory. A failed dynamic_cast will throw std::bad_cast. And so on. As of C++14, there are 21 different exception classes that can be thrown, with more coming in C++17.
The good news is that all of these exception classes are derived from a single class called std::exception. std::exception is a small interface class designed to serve as a base class to any exception thrown by the C++ standard library.
1 | try { |
The one thing worth noting is that std::exception has a virtual member function named what() that returns a C-style string description of the exception. Most derived classes override the what() function to change the message. Note that this string is meant to be used for descriptive text only – do not use it for comparisons, as it is not guaranteed to be the same across compilers.
Nothing throws a std::exception directly, and neither should you. However, you should feel free to throw the other standard exception classes in the standard library if they adequately represent your needs.
std::runtime_error (included as part of the stdexcept header) is a popular choice, because it has a generic name, and its constructor takes a customizable message.
Rewrite our ArrayException:
1 | class ArrayException : public std::exception { |
In C++11, virtual function what() was updated to have specifier noexcept (which means the function promises not to throw exceptions itself). Therefore, in C++11 and beyond, our override should also have specifier noexcept.
Rethrowing exceptions
1 | int getIntValueFromDatabase(Database *d, std::string table, std::string key) { |
Throwing a new exception
1 | // ... |
In the example above, the program catches the int exception from getIntValue(), logs the error, and then throws a new exception with char value ‘q’. Although it may seem weird to throw an exception from a catch block, this is allowed. Remember, only exceptions thrown within a try block are eligible to be caught. This means that an exception thrown within a catch block will not be caught by the catch block it's in. Instead, it will be propagated up the stack to the caller.
Rethrowing an exception (the wrong way)
1 | // ... |
Although this works, this method has a couple of downsides:
First, this doesn’t throw the exact same exception as the one that is caught – rather, it throws a
copy-initialized copyof variable exception. Although the compiler is free to elide the copy, it may not, so this could be less performant.Second, it may cause unintended object slicing.
1
2
3
4
5
6// ...
try {
return d->getIntValue(table, key); // throws Derived exception
} catch (Base &exception) {
throw exception; // Danger: this throws a Base object, not a Derived object (object slicing)
}
Rethrowing an exception (the right way)
Fortunately, C++ provides a way to rethrow the exact same exception as the one that was just caught. To do so, simply use the throw keyword from within the catch block (with no associated variable), like so:
1 | try { |
This throw keyword that doesn’t appear to throw anything in particular actually re-throws the exact same exception that was just caught. No copies are made, meaning we don’t have to worry about performance killing copies or slicing.
Function try blocks
Try and catch blocks work well enough in most cases, but there is one particular case in which they are not sufficient. Consider the following example:
1 | class A { |
But what if we want to catch the exception inside of B? The call to base constructor A happens via the member initialization list, before the B constructor’s body is called. There’s no way to wrap a standard try block around it. In this situation, we have to use a slightly modified try block called a function try block.
Function try blocks are designed to allow you to establish an exception handler around the body of an entire function, rather than around a block of code.
1 | // class A ... same code |
Second, note that the associated catch block is at the same level of indentation as the entire function. Any exception thrown between the try keyword and the end of the function body will be eligible to be caught here.
Finally, unlike normal catch blocks, which allow you to either resolve an exception, throw a new exception, or rethrow an existing exception, with function-level try blocks, you must throw or rethrow an exception. If you do not explicitly throw a new exception, or rethrow the current exception, the exception will be implicitly rethrown up the stack.
Although function level try blocks can be used with non-member functions as well, they typically aren’t because there’s rarely a case where this would be needed. They are almost exclusively used with constructors!
Don’t use function try to clean up resources
When construction of an object fails, the destructor of the class is not called. Consequently, you may be tempted to use a function try block as a way to clean up a class that had partially allocated resources before failing. However, referring to members of the failed object is considered undefined behavior since the object is "dead" before the catch block executes. This means that you can’t use function try to clean up after a class. If you want to clean up after a class, follow the standard rules for cleaning up classes that throw exceptions.
Function try is useful primarily for either logging failures before passing the exception up the stack, or for changing the type of exception thrown.
Exception dangers and downsides
Cleaning up resources
1 | try { |
This example should be rewritten as follows:
1 | try { |
This kind of error often crops up in another form when dealing with dynamically allocated memory:
1 | try { |
This example is a little more tricky than the previous one – because john is local to the try block, it goes out of scope when the try block exits. So there’s no way for it to deallocate the memory. However, there are two relatively easy ways to fix this.
First:
1 | Person *john = NULL; |
Second: use a local variable of a class that knows how to cleanup itself when it goes out of scope (often called “smart pointer”). The STL provides a class called std::unique_ptr that can be used for this purpose. std::unique_ptr is a template class that holds a pointer, and deallocates it when it goes out of scope.
1 | try { |
Exceptions and destructors
Unlike constructors, where throwing exceptions can be a useful way to indicate that object creation did not succeed, exceptions should never be thrown in destructors.
The problem occurs when an exception is thrown from a destructor during the stack unwinding process. If that happens, the compiler is put in a situation where it doesn’t know whether to continue the stack unwinding process or handle the new exception. The end result is that your program will be terminated immediately.
The alternative way is to write a message to a log file instead.
Performance concerns
The main performance penalty for exceptions happens when an exception is actually thrown. In this case, the stack must be unwound and an appropriate exception handler found, which is a relatively expensive operation.
As a note, some modern computer architectures support an exception model called zero-cost exceptions. Zero-cost exceptions, if supported, have no additional runtime cost in the non-error case (which is the case we most care about performance). However, they incur an even larger penalty in the case where an exception is found.
So when should I use exceptions?
- The error being handled is likely to occur only infrequently.
- The error is serious and execution could not continue otherwise.
- The error cannot be handled at the place where it occurs.
- There isn’t a good alternative way to return an error code back to the caller.
Move semantics and smart pointers
1 |
|
One of the best things about classes is that they contain destructors that automatically get executed when an object of the class goes out of scope. So if you allocate (or acquire) memory in your constructor, you can deallocate it in your destructor, and be guaranteed that the memory will be deallocated when the class object is destroyed (regardless of whether it goes out of scope, gets explicitly deleted, etc…). This is at the heart of the RAII programming paradigm that we talked about in lesson 8.7 – Destructors.
So can we use a class to help us manage and clean up our pointers? We can! Consider a class whose sole job was to hold and “own” a pointer passed to it, and then deallocate that pointer when the class object went out of scope. As long as objects of that class were only created as local variables, we could guarantee that the class would properly go out of scope (regardless of when or how our functions terminate) and the owned pointer would get destroyed.
Here’s a first draft of the idea:
1 |
|
Such a class is called a smart pointer. A Smart pointer is a composition class that is designed to manage dynamically allocated memory and ensure that memory gets deleted when the smart pointer object goes out of scope. (Relatedly, built-in pointers are sometimes called dumb pointers because they can’t clean up after themselves).
A critical flaw
The Auto_ptr1 class has a critical flaw lurking behind some auto-generated code. Before reading further, see if you can identify what it is. We’ll wait…
1 | int main() { |
Very likely (but not necessarily) your program will crash at this point. See the problem now? Because we haven't supplied a copy constructor or an assignment operator, C++ provides one for us. And the functions it provides do shallow copies. So when we initialize res2 with res1, both Auto_ptr1 variables are pointed at the same Resource. When res2 goes out of the scope, it deletes the resource, leaving res1 with a dangling pointer. When res1 goes to delete its (already deleted) Resource, crash!
1 | void passByValue(Auto_ptr1<Resource> res) {} |
In this program, res1 will be copied by value into passByValue’s parameter res, leading to duplication of the Resource pointer. Crash!
So clearly this isn’t good. How can we address this?
Well, one thing we could do would be to explicitly define and delete the copy constructor and assignment operator, thereby preventing any copies from being made in the first place. That would prevent the pass by value case (which is good, we probably shouldn’t be passing these by value anyway).
But then how would we return an Auto_ptr1 from a function back to the caller?
1 | ??? generateResource() { |
We can’t return our Auto_ptr1 by reference, because the local Auto_ptr1 will be destroyed at the end of the function, and the caller will be left with a dangling reference. Return by address has the same problem. We could return pointer r by address, but then we might forget to delete r later, which is the whole point of using smart pointers in the first place. So that’s out. Returning the Auto_ptr1 by value is the only option that makes sense – but then we end up with shallow copies, duplicated pointers, and crashes.
Another option would be to override the copy constructor and assignment operator to make deep copies. In this way, we’d at least guarantee to avoid duplicate pointers to the same object. But copying can be expensive (and may not be desirable or even possible), and we don’t want to make needless copies of objects just to return an Auto_ptr1 from a function. Plus assigning or initializing a dumb pointer doesn’t copy the object being pointed to, so why would we expect smart pointers to behave differently?
Move semantics
What if, instead of having our copy constructor and assignment operator copy the pointer (“copy semantics”), we instead transfer/move ownership of the pointer from the source to the destination object? This is the core idea behind move semantics. Move semantics means the class will transfer ownership of the object rather than making a copy.
1 | // A copy constructor that implements move semantics |
std::auto_ptr, and why to avoid it
Now would be an appropriate time to talk about std::auto_ptr. std::auto_ptr, introduced in C++98, was C++’s first attempt at a standardized smart pointer. std::auto_ptr opted to implement move semantics just like the Auto_ptr2 class does.
However, std::auto_ptr (and our Auto_ptr2 class) has a number of problems that makes using it dangerous.
First, because std::auto_ptr implements move semantics through the copy constructor and assignment operator, passing a std::auto_ptr by value to a function will cause your resource to get moved to the function parameter (and be destroyed at the end of the function when the function parameters go out of scope). Then when you go to access your auto_ptr argument from the caller (not realizing it was transferred and deleted), you’re suddenly dereferencing a null pointer. Crash!
Second, std::auto_ptr always deletes its contents using non-array delete. This means auto_ptr won’t work correctly with dynamically allocated arrays, because it uses the wrong kind of deallocation. Worse, it won’t prevent you from passing it a dynamic array, which it will then mismanage, leading to memory leaks.
Finally, auto_ptr doesn’t play nice with a lot of the other classes in the standard library, including most of the containers and algorithms. This occurs because those standard library classes assume that when they copy an item, it actually makes a copy, not does a move.
Because of the above mentioned shortcomings, std::auto_ptr has been deprecated in C++11, and it should not be used. In fact, std::auto_ptr is slated for complete removal from the standard library as part of C++17!
Rule: std::auto_ptr is deprecated and should not be used. (Use std::unique_ptr or std::shared_ptr instead)..
Moving forward
The core problem with the design of std::auto_ptr is that prior to C++11, the C++ language simply had no mechanism to differentiate “copy semantics” from “move semantics”. Overriding the copy semantics to implement move semantics leads to weird edge cases and inadvertent bugs. For example, you can write res1 = res2 and have no idea whether res2 will be changed or not!
Because of this, in C++11, the concept of “move” was formally defined, and “move semantics” were added to the language to properly differentiate copying from moving. Now that we’ve set the stage for why move semantics can be useful, we’ll explore the topic of move semantics throughout the rest of this chapter. We’ll also fix our Auto_ptr2 class using move semantics.
In C++11, std::auto_ptr has been replaced by a bunch of other types of “move-aware” smart pointers: std::scoped_ptr, std::unique_ptr, std::weak_ptr, and std::shared_ptr. We’ll also explore the two most popular of these: unique_ptr (which is a direct replacement for auto_ptr) and shared_ptr.
R-value reference
The topic of l-values and r-values is very important to understand move semantics in C++11.
L-values and r-values
Despite having the word “value” in their names, l-values and r-values are actually not properties of values, but rather, properties of expressions.
Every expression in C++ has two properties: a type (which is used for type checking), and a value category (which is used for certain kinds of syntax checking, such as whether the result of the expression can be assigned to). In C++03 and earlier, l-values and r-values were the only two value categories available.
The actual definition of which expressions are l-values and which are r-values is surprisingly complicated, so we’ll take a simplified view of the subject that will largely suffice for our purposes.
L-value: Locator values
It’s simplest to think of an l-value (also called a locator value) as a function or an object (or an expression that evaluates to a function or object). All l-values have assigned memory addresses.
When l-values were originally defined, they were defined as “values that are suitable to be on the left-hand side of an assignment expression”. However, later, the const keyword was added to the language, and l-values were split into two sub-categories: modifiable l-values, which can be changed, and non-modifiable l-values, which are const.
R-value: everything that is not an l-value
It’s simplest to think of an r-value as “everything that is not an l-value”. This notably includes literals (e.g. 5), temporary values (e.g. x+1), and anonymous objects (e.g. Fraction(5, 2)).
1 | Fraction &frac = Fraction(5, 2); // error |
R-values are typically evaluated for their values, have expression scope (they die at the end of the expression they are in), and cannot be assigned to. This non-assignment rule makes sense, because assigning a value applies a side-effect to the object. Since r-values have expression scope, if we were to assign a value to an r-value, then the r-value would either go out of scope before we had a chance to use the assigned value in the next expression (which makes the assignment useless) or we’d have to use a variable with a side effect applied more than once in an expression (which by now you should know causes undefined behavior!).
In order to support move semantics, C++11 introduces 3 new value categories: pr-values, x-values, and gl-values. We will largely ignore these since understanding them isn’t necessary to learn about or use move semantics effectively. If you’re interested, cppreference.com has an extensive list of expressions that qualify for each of the various value categories, as well as more detail about them.
L-value references
Prior to C++11, only one type of reference existed in C++, and so it was just called a “reference”. However, in C++11, it’s sometimes called an l-value reference. L-value references can only be initialized with modifiable l-values.
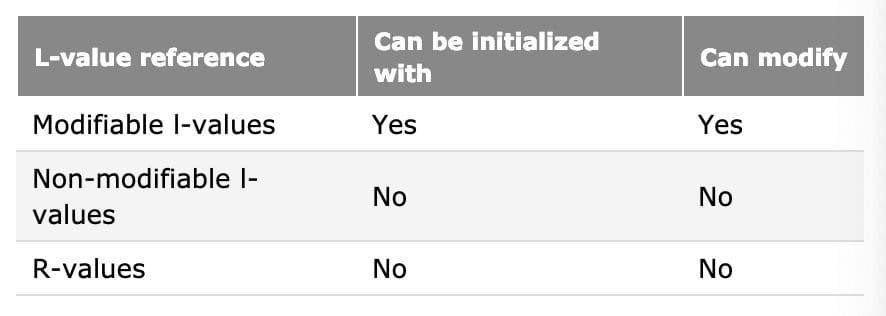
L-value references to const objects can be initialized with l-values and r-values alike. However, those values can’t be modified.
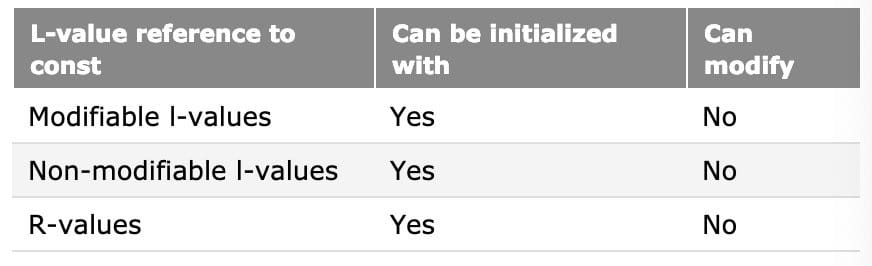
L-value references to const objects are particularly useful because they allow us to pass any type of argument (l-value or r-value) into a function without making a copy of the argument.
1 | const Fraction &frac = Fraction(); // allowed |
R-value references
C++11 adds a new type of reference called an r-value reference. An r-value reference is a reference that is designed to be initialized with an r-value (only). While an l-value reference is created using a single ampersand, an r-value reference is created using a double ampersand:
1 | int x = 5; |
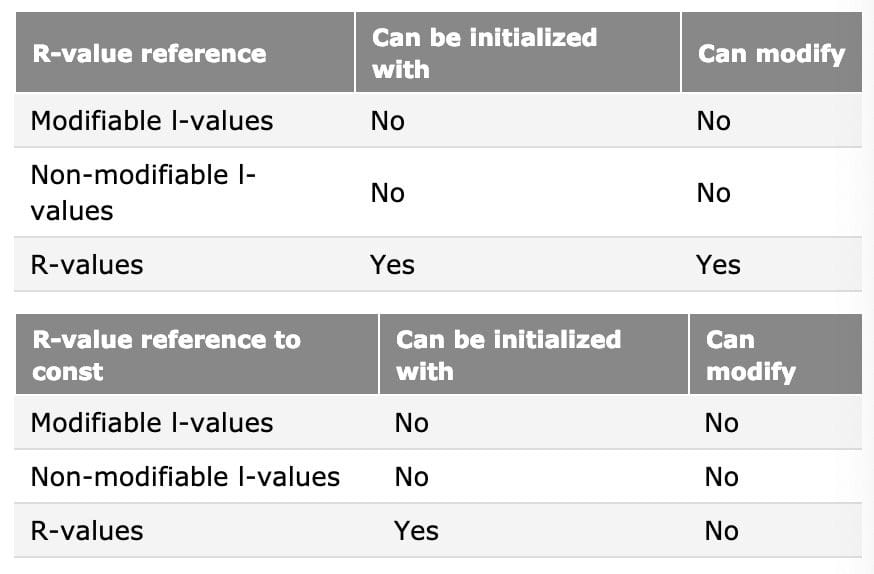
R-value references have two properties that are useful:
- First, r-value references
extend the lifespanof the object they are initialized with to the lifespan of the r-value reference (l-value references to const objects can do this too). - Second, non-const r-value references allow you to modify the r-value!
While it may seem weird to initialize an r-value reference with a literal value and then be able to change that value, when initializing an r-value with a literal, a temporary is constructed from the literal so that the reference is referencing a temporary object, not a literal value.
R-value references are not very often used in either of the manners illustrated above.
R-value references as function parameters
R-value references are more often used as function parameters. This is most useful for function overloads when you want to have different behavior for l-value and r-value arguments.
1 | void fun(const int &lref) { // l-value arguments will select this function |
This is considered a better match than a l-value reference to const, since the 1st one can also match literals.
One interesting note:
1 | int &&ref = 5; |
actually calls the l-value version of the function! Although variable ref has type r-value reference to an integer, it is actually an l-value itself (as are all named variables). The confusion stems from the use of the term r-value in two different contexts. Think of it this way: Named-objects are l-values. Anonymous objects are r-values.
The type of the named object or anonymous object is independent from whether it’s an l-value or r-value. Or, put another way, if r-value reference had been called anything else, this confusion wouldn’t exist.
I don’t understand this part. I just understand that
refin this case should be treated as a named object because it has a name!
Returning an r-value reference
You should almost never return an r-value reference, for the same reason you should almost never return an l-value reference. In most cases, you’ll end up returning a hanging reference when the referenced object goes out of scope at the end of the function.
Just like a pointer referring to a local variable?
Move constructors and move assignment
Copy constructors and copy assignment (recap)
Copy constructors are used to initialize a new class by making a copy of an object of the same class. Copy assignment is used to copy one class to another existing class.
By default, C++ will provide a copy constructor and copy assignment operator if one is not explicitly provided. These compiler-provided functions do shallow copies, which may cause problems for classes that allocate dynamic memory. So classes that deal with dynamic memory should override these functions to do deep copies.
Returning back to our Auto_ptr smart pointer class example from the first lesson in this chapter, let’s look at a version that implements a copy constructor and copy assignment operator that do deep copies, and a sample program that exercises them:
1 | template <class T> |
That’s a lot of resource creation and destruction going on for such a simple program! What’s going on here?
So, in short, because we call the copy constructor once to copy construct res to a temporary, and copy assignment once to copy the temporary into mainres, we end up allocating and destroying 3 separate objects in total. Inefficient, but at least it doesn’t crash!
However, with move semantics, we can do better.
Move constructors and move assignment
C++11 defines two new functions in service of move semantics: a move constructor, and a move assignment operator. Whereas the goal of the copy constructor and copy assignment is to make a copy of one object to another, the goal of the move constructor and move assignment is to move ownership of the resources from one object to another (which is much less expensive than making a copy).
Defining a move constructor and move assignment work analogously to their copy counterparts. However, whereas the copy flavors of these functions take a const l-value reference parameter, the move flavors of these functions use non-const r-value reference parameters.
Here’s the same Auto_ptr3 class as above, with a move constructor and move assignment operator added. We’ve left in the deep-copying copy constructor and copy assignment operator for comparison purposes.
1 | // Copy constructor |
The move constructor and move assignment operator are simple. Instead of deep copying the source object (a) into the implicit object, we simply move (steal) the source object’s resources. This involves shallow copying the source pointer into the implicit object, then setting the source pointer to null.
- Inside generateResource(), local variable res is created and initialized with a dynamically allocated Resource, which causes the first “Resource acquired”.
- Res is returned back to main() by value. Res is
move constructedinto atemporary object, transferring the dynamically created object stored in res to the temporary object. We’ll talk about why this happens below. Res goes out of scope(but its data has been transferred already). Because res no longer manages a pointer (it was moved to the temporary), nothing interesting happens here.The temporary objectismove assignedto mainres. This transfers the dynamically created object stored in the temporary to mainres.- The assignment expression ends, and
the temporary object goes out of expression scopeand is destroyed. However, because the temporary no longer manages a pointer (it was moved to mainres), nothing interesting happens here either. - At the end of main(), mainres goes out of scope, and our final “Resource destroyed” is displayed.
So instead of copying our Resource twice (once for the copy constructor and once for the copy assignment), we transfer it twice. This is more efficient, as Resource is only constructed and destroyed once instead of three times.
1 | Auto_ptr4<Resource> res(new Resource); // copy constructor called |
When are the move constructor and move assignment called?
The move constructor and move assignment are called when those functions have been defined, and the argument for construction or assignment is an r-value. Most typically, this r-value will be a literal or temporary value.
In most cases, a move constructor and move assignment operator will not be provided by default, unless the class does not have any defined copy constructors, copy assignment, move assignment, or destructors. However, the default move constructor and move assignment do the same thing as the default copy constructor and copy assignment (make copies, not do moves).
Rule: If you want a move constructor and move assignment that do moves, you’ll need to write them yourself.
The key insight behind move semantics
You now have enough context to understand the key insight behind move semantics.
If we construct an object or do an assignment where the argument is an l-value, the only thing we can reasonably do is copy the l-value. We can't assume it's safe to alter the l-value, because it may be used again later in the program. If we have an expression “a = b”, we wouldn’t reasonably expect b to be changed in any way.
However, if we construct an object or do an assignment where the argument is an r-value, then we know that r-value is just a temporary object of some kind. Instead of copying it (which can be expensive), we can simply transfer its resources (which is cheap) to the object we’re constructing or assigning. This is safe to do because the temporary will be destroyed at the end of the expression anyway, so we know it will never be used again!
C++11, through r-value references, gives us the ability to provide different behaviors when the argument is an r-value vs an l-value, enabling us to make smarter and more efficient decisions about how our objects should behave.
Move functions should always leave both objects in a well-defined state
In the above examples, both the move constructor and move assignment functions set a.m_ptr to nullptr. This may seem extraneous – after all, if “a” is a temporary r-value, why bother doing “cleanup” if parameter “a” is going to be destroyed anyway?
The answer is simple: When “a” goes out of scope, a’s destructor will be called, and a.m_ptr will be deleted. If at that point, a.m_ptr is still pointing to the same object as m_ptr, then m_ptr will be left as a dangling pointer. When the object containing m_ptr eventually gets used (or destroyed), we’ll get undefined behavior.
Additionally, in the next lesson we’ll see cases where “a” can be an l-value. In such a case, “a” wouldn’t be destroyed immediately, and could be queried further before its lifetime ends.
Automatic l-values returned by value may be moved instead of copied
In the generateResource() function of the Auto_ptr4 example above, when variable res is returned by value, it is moved instead of copied, even though res is an l-value. The C++ specification has a special rule that says automatic objects returned from a function by value can be moved even if they are l-values. This makes sense, since res was going to be destroyed at the end of the function anyway! We might as well steal its resources instead of making an expensive and unnecessary copy.
一个局部变量对象在返回的时候会被当做 r-value 处理。
Although the compiler can move l-value return values, in some cases it may be able to do even better by simply eliding the copy altogether (which avoids the need to make a copy or do a move at all). In such a case, neither the copy constructor nor move constructor would be called.
Disabling copying
In the Auto_ptr4 class above, we left in the copy constructor and assignment operator for comparison purposes. But in move-enabled classes, it is sometimes desirable to delete the copy constructor and copy assignment functions to ensure copies aren't made. In the case of our Auto_ptr class, we don’t want to copy our templated object T – both because it’s expensive, and whatever class T is may not even support copying!
1 | Auto_ptr5(const Auto_ptr5& a) = delete; |
If you were to try to pass an Auto_ptr5 l-value to a function by value, the compiler would complain that the copy constructor required to initialize the copy constructor argument has been deleted. This is good, because we should probably be passing Auto_ptr5 by const l-value reference anyway!
Auto_ptr5 is (finally) a good smart pointer class. And, in fact the standard library contains a class very much like this one (that you should use instead), named std::unique_ptr. We’ll talk more about std::unique_ptr later in this chapter.
Another example:
1 | // Copy constructor |
Compare Copy & Move versions:
On the same machine, this program executed in 0.0056 seconds.
Comparing the runtime of the two programs, 0.0056 / 0.00825559 = 67.8%. The move version was almost 33% faster!
std::move
Once you start using move semantics more regularly, you’ll start to find cases where you want to invoke move semantics, but the objects you have to work with are l-values, not r-values. Consider the following swap function as an example:
1 | template<class T> |
As we showed last lesson, making copies can be inefficient. And this version of swap makes 3 copies. That leads to a lot of excessive string creation and destruction, which is slow.
However, doing copies isn’t necessary here. All we’re really trying to do is swap the values of a and b, which can be accomplished just as well using 3 moves instead! So if we switch from copy semantics to move semantics, we can make our code more performant.
But how? The problem here is that parameters a and b are l-value references, not r-value references, so we don’t have a way to invoke the move constructor and move assignment operator instead of copy constructor and copy assignment. By default, we get the copy constructor and copy assignment behaviors. What are we to do?
std::move
In C++11, std::move is a standard library function that serves a single purpose – to convert its argument into an r-value. We can pass an l-value to std::move, and it will return an r-value reference. std::move is defined in the utility header.
Here’s the same program as above, but with a swap() function that uses std::move to convert our l-values into r-values so we can invoke move semantics:
1 | template<class T> |
Another example
We can also use std::move when filling elements of a container, such as std::vector, with l-values.
In the following program, we first add an element to a vector using copy semantics. Then we add an element to the vector using move semantics.
1 | int main() { |
move 方法默认是 copy,可能只是多了一个将原来的对象销毁或者成员设置为 nullptr?
In the first case, we passed push_back() an l-value, so it used copy semantics to add an element to the vector. For this reason, the value in str is left alone.
In the second case, we passed push_back() an r-value (actually an l-value converted via std::move), so it used move semantics to add an element to the vector. This is more efficient, as the vector element can steal the string's value rather than having to copy it. In this case, str is left empty.
At this point, it’s worth reiterating that std::move() gives a hint to the compiler that the programmer doesn't need this object any more (at least, not in its current state). Consequently, you should not use std::move() on any persistent object you don’t want to modify, and you should not expect the state of any objects that have had std::move() applied to be the same after they are moved!
In the above example, string str is set to the empty string after being moved (which is what std::string always does after a successful move). This allows us to reuse variable str if we wish (or we can ignore it, if we no longer have a use for it).
Where else is std::move useful?
std::move can also be useful when sorting an array of elements. Many sorting algorithms (such as selection sort and bubble sort) work by swapping pairs of elements. In previous lessons, we’ve had to resort to copy-semantics to do the swapping. Now we can use move semantics, which is more efficient.
It can also be useful if we want to move the contents managed by one smart pointer to another.
Conclusion
std::move can be used whenever we want to treat an l-value like an r-value for the purpose of invoking move semantics instead of copy semantics.
std::unique_ptr
At the beginning of the chapter, we discussed how use of pointers can lead to bugs and memory leaks in some situations. For example, this can happen when a function early returns, or throws an exception, and the pointer is not properly deleted.
Smart pointers should never be dynamically allocated themselves (otherwise, there is the risk that the smart pointer may not be properly deallocated, which means the object it owns would not be deallocated, causing a memory leak). By always allocating smart pointers statically (as local variables or composition members of a class), we’re guaranteed that the smart pointer will properly go out of scope when the function or object it is contained within ends, ensuring the object the smart pointer owns is properly deallocated.
C++11 standard library ships with 4 smart pointer classes: std::auto_ptr (which you shouldn’t use – it’s being removed in C++17), std::unique_ptr, std::shared_ptr, and std::weak_ptr. std::unique_ptr is by far the most used smart pointer class, so we’ll cover that one first. In the next lesson, we’ll cover std::shared_ptr and std::weak_ptr.
std::unique_ptr
std::unique_ptr is the C++11 replacement for std::auto_ptr. It should be used to manage any dynamically allocated object that is not shared by multiple objects. That is, std::unique_ptr should completely own the object it manages, not share that ownership with other classes. std::unique_ptr lives in the
1 |
|
Unlike std::auto_ptr, std::unique_ptr properly implements move semantics.
1 | std::unique_ptr<Resource> res1(new Resource); // Resource created here |
Accessing the managed object
std::unique_ptr has an overloaded operator* and operator-> that can be used to return the resource being managed.
- Operator* returns a reference to the managed resource.
- Operator-> returns a pointer.
Remember that std::unique_ptr may not always be managing an object – either because it was created empty (using the default constructor or passing in a nullptr as the parameter), or because the resource it was managing got moved to another std::unique_ptr. So before we use either of these operators, we should check whether the std::unique_ptr actually has a resource. Fortunately, this is easy: std::unique_ptr has a cast to bool that returns true if the std::unique_ptr is managing a resource.
1 | // overload operator<< |
std::unique_ptr and arrays
Unlike std::auto_ptr, std::unique_ptr is smart enough to know whether to use scalar delete or array delete, so std::unique_ptr is okay to use with both scalar objects and arrays.
However, std::array or std::vector (or std::string) are almost always better choices than using std::unique_ptr with a fixed array, dynamic array, or C-style string.
Rule: Favor std::array, std::vector, or std::string over a smart pointer managing a fixed array, dynamic array, or C-style string
std::make_unique
C++14 comes with an additional function named std::make_unique(). This templated function constructs an object of the template type and initializes it with the arguments passed into the function.
1 | // Fraction class |
Use of std::make_unique() is optional, but is recommended over creating std::unique_ptr yourself. This is because code using std::make_unique is simpler, and it also requires less typing (when used with automatic type deduction). Furthermore it resolves an exception safety issue that can result from C++ leaving the order of evaluation for function arguments unspecified.
Rule: use std::make_unique() instead of creating std::unique_ptr and using new yourself.
The exception safety issue in more detail
For those wondering what the “exception safety issue” mentioned above is, here’s a description of the issue.
Consider an expression like this one:
1 | some_function(std::unique_ptr<T>(new T), function_that_can_throw_exception()); |
The compiler is given a lot of flexibility in terms of how it handles this call. It could create a new T, then call function_that_can_throw_exception(), then create the std::unique_ptr that manages the dynamically allocated T. If function_that_can_throw_exception() throws an exception, then the T that was allocated will not be deallocated, because the smart pointer to do the deallocation hasn't been created yet. This leads to T being leaked.
std::make_unique() doesn’t suffer from this problem because the creation of the object T and the creation of the std::unique_ptr happen inside the std::make_unique() function, where there’s no ambiguity about order of execution.
Returning std::unique_ptr from a function
std::unique_ptr can be safely returned from a function by value:
1 | std::unique_ptr<Resource> createResource() { |
In the above code, createResource() returns a std::unique_ptr by value. If this value is not assigned to anything, the temporary return value will go out of scope and the Resource will be cleaned up. If it is assigned (as shown in main()), move semantics will be employed to transfer the Resource from the return value to the object assigned to (in the above example, ptr). This makes returning a resource by std::unique_ptr much safer than returning raw pointers!
In general, you should not return std::unique_ptr by pointer (ever) or reference (unless you have a specific compelling reason to).
Passing std::unique_ptr to a function
If you want the function to take ownership of the contents of the pointer, pass the std::unique_ptr by value. Note that because copy semantics have been disabled, you’ll need to use std::move to actually pass the variable in.
1 | void takeOwnership(std::unique_ptr<Resource> res) { |
However, most of the time, you won’t want the function to take ownership of the resource. Although you can pass a std::unique_ptr by reference (which will allow the function to use the object without assuming ownership), you should only do so when the caller might alter or change the object being managed.
Instead, it's better to just pass the resource itself (by pointer or reference, depending on whether null is a valid argument). This allows the function to remain agnostic of how the caller is managing its resources. To get a raw resource pointer from a std::unique_ptr, you can use the get() member function:
1 | // non-taking-ownership version |
Misusing std::unique_ptr
There are two easy ways to misuse std::unique_ptrs, both of which are easily avoided.
First, don’t let multiple classes manage the same resource. For example:
1
2
3Resource *res = new Resource;
std::unique_ptr<Resource> res1(res);
std::unique_ptr<Resource> res2(res);While this is legal syntactically, the end result will be that both res1 and res2 will try to delete the Resource, which will lead to
undefined behavior.Second, don’t manually delete the resource out from underneath the std::unique_ptr.
1
2
3Resource *res = new Resource;
std::unique_ptr<Resource> res1(res);
delete res;If you do, the std::unique_ptr will try to delete an already deleted resource, again leading to
undefined behavior.
Note that std::make_unique() prevents both of the above cases from happening inadvertently.
std::shared_ptr
Unlike std::unique_ptr, which is designed to singly own and manage a resource, std::shared_ptr is meant to solve the case where you need multiple smart pointers co-owning a resource.
This means that it is fine to have multiple std::shared_ptr pointing to the same resource. Internally, std::shared_ptr keeps track of how many std::shared_ptr are sharing the resource. As long as at least one std::shared_ptr is pointing to the resource, the resource will not be deallocated, even if individual std::shared_ptr are destroyed. As soon as the last std::shared_ptr managing the resource goes out of scope (or is reassigned to point at something else), the resource will be deallocated.
1 | int main() { |
Note that we created a second shared pointer from the first shared pointer (using copy initialization). This is important. Consider the following similar program:
1 | int main() { |
and then crashes (at least on the author’s machine).
The difference here is that we created two std::shared_ptr independently from each other. As a consequence, even though they’re both pointing to the same Resource, they aren't aware of each other. When ptr2 goes out of scope, it thinks it’s the only owner of the Resource, and deallocates it. When ptr1 later goes out of the scope, it thinks the same thing, and tries to delete the Resource again. Then bad things happen.
Fortunately, this is easily avoided by using copy assignment or copy initialization when you need multiple shared pointers pointing to the same Resource.
Rule: Always make a copy of an existing std::shared_ptr if you need more than one std::shared_ptr pointing to the same resource.
std::make_shared
Much like std::make_unique() can be used to create a std::unique_ptr in C++14, std::make_shared() can (and should) be used to make a std::shared_ptr. std::make_shared() is available in C++11.
Here’s our original example, using std::make_shared():
1 | int main() { |
std::make_shared() is simpler and safer (there's no way to directly create two std::shared_ptr pointing to the same resource using this method). However, std::make_shared() is also more performant than not using it. The reasons for this lie in the way that std::shared_ptr keeps track of how many pointers are pointing at a given resource.
Digging into std::shared_ptr
Unlike std::unique_ptr, which uses a single pointer internally, std::shared_ptr uses two pointers internally. One pointer points at the resource being managed. The other points at a "control block", which is a dynamically allocated object that tracks of a bunch of stuff, including how many std::shared_ptr are pointing at the resource. When a std::shared_ptr is created via a std::shared_ptr constructor, the memory for the managed object (which is usually passed in) and control block (which the constructor creates) are allocated separately. However, when using std::make_shared(), this can be optimized into a single memory allocation, which leads to better performance.
This also explains why independently creating two std::shared_ptr pointed to the same resource gets us into trouble. Each std::shared_ptr will have one pointer pointing at the resource. However, each std::shared_ptr will independently allocate its own control block, which will indicate that it is the only pointer owning that resource. Thus, when that std::shared_ptr goes out of scope, it will deallocate the resource, not realizing there are other std::shared_ptr also trying to manage that resource.
However, when a std::shared_ptr is cloned using copy assignment, the data in the control block can be appropriately updated to indicate that there are now additional std::shared_ptr co-managing the resource.
Shared pointers can be created from unique pointers
A std::unique_ptr can be converted into a std::shared_ptr via a special std::shared_ptr constructor that accepts a std::unique_ptr r-value. The contents of the std::unique_ptr will be moved to the std::shared_ptr.
However, std::shared_ptr can not be safely converted to a std::unique_ptr. This means that if you’re creating a function that is going to return a smart pointer, you're better off returning a std::unique_ptr and assigning it to a std::shared_ptr if and when that's appropriate.
The perils of std::shared_ptr
std::shared_ptr has some of the same challenges as std::unique_ptr – if the std::shared_ptr is not properly disposed of (either because it was dynamically allocated and never deleted, or it was part of an object that was dynamically allocated and never deleted) then the resource it is managing won’t be deallocated either. With std::unique_ptr, you only have to worry about one smart pointer being properly disposed of. With std::shared_ptr, you have to worry about them all. If any of the std::shared_ptr managing a resource are not properly destroyed, the resource will not be deallocated properly.
std::shared_ptr and arrays
In C++14 and earlier, std::shared_ptr does not have proper support for managing arrays, and should not be used to manage a C-style array. As of C++17, std::shared_ptr does have support for arrays. However, as of C++17, std::make_shared is still lacking proper support for arrays, and should not be used to create shared arrays. This will likely be addressed in C++20.
Circular dependency issues with std::shared_ptr, and std::weak_ptr
1 | class Person { |
And that’s it. No deallocations took place. Uh. oh. What happened?
It turns out that this can happen any time shared pointers form a circular reference.
Circular references
A Circular reference (also called a cyclical reference or a cycle) is a series of references where each object references the next, and the last object references back to the first, causing a referential loop. The references do not need to be actual C++ references – they can be pointers, unique IDs, or any other means of identifying specific objects.
In the context of shared pointers, the references will be pointers.
A reductive case
It turns out, this cyclical reference issue can even happen with a single std::shared_ptr – a std::shared_ptr referencing the object that contains it is still a cycle (just a reductive one). Although it’s fairly unlikely that this would ever happen in practice, we’ll show you for additional comprehension:
1 | class Resource { |
So what is std::weak_ptr for anyway?
std::weak_ptr was designed to solve the “cyclical ownership” problem described above. A std::weak_ptr is an observer – it can observe and access the same object as a std::shared_ptr (or other std::weak_ptrs) but it is not considered an owner. Remember, when a std::shared pointer goes out of scope, it only considers whether other std::shared_ptr are co-owning the object. std::weak_ptr does not count!
1 | class Person { |
Using std::weak_ptr
The downside of std::weak_ptr is that std::weak_ptr are not directly usable (they have no operator->). To use a std::weak_ptr, you must first convert it into a std::shared_ptr. Then you can use the std::shared_ptr. To convert a std::weak_ptr into a std::shared_ptr, you can use the lock() member function. Here’s the above example, updated to show this off:
1 | const std::shared_ptr<Person> getPartner() const { |
We don’t have to worry about circular dependencies with std::shared_ptr variable “partner” since it's just a local variable inside the function. It will eventually go out of scope at the end of the function and the reference count will be decremented by 1.