Source: LearnCpp.com by Alex
The Standard Template Library
The Standard Library
Technically ‘STL’ is incorrect. What you’re calling the ‘STL’ is actually the C++ standard library.
The STL was a different library that merely influenced the C++ standard library
The term “STL” or “Standard Template Library” does not show up anywhere in the ISO 14882 C++ standard. So referring to the C++ standard library as STL is wrong. The term “C++ Standard Library” or “standard library” is what’s officially used by ISO 14882:
STL is a library originally designed by Alexander Stepanov, independent of the C++ standard. However, some components of the C++ standard library include STL components like vector, list and algorithms like copy and swap.
STL containers overview
Generally speaking, the container classes fall into three basic categories:
Sequence ContainersAssociative ContainersContainer Adapters
Sequence Containers
As of C++11, the STL contains 6 sequence containers:
- std::vector
- std::deque
- std::array
- std::list
- std::forward_list
- std::basic_string
Specifically,
- The
dequeclass (pronounced “deck”) is adouble-ended queueclass, implemented as a dynamic array that can grow from both ends. - A
listis a special type of sequence container called adoubly linked listwhere each element in the container contains pointers that point at the next and previous elements in the list. Lists only provide access to the start and end of the list. - Although the STL
string(and wstring) class aren’t generally included as a type of sequence container, they essentially are, as they can be thought of as a vector with data elements of type char (or wchar).
Associative Containers
Associative containers are containers that automatically sort their inputs when those inputs are inserted into the container. By default, associative containers compare elements using operator<.
- A
setis a container that stores unique elements, with duplicate elements disallowed. The elements are sorted according to their values. - A
multisetis a set whereduplicateelements are allowed. - A
map(also called anassociative array) is a set where each element is a pair, called a key/value pair. The key is used for sorting and indexing the data, and must be unique. The value is the actual data. - A
multimap(also called adictionary) is a map that allowsduplicate keys. Real-life dictionaries are multimaps: the key is the word, and the value is the meaning of the word. All the keys are sorted in ascending order, and you can look up the value by key. Some words can have multiple meanings, which is why the dictionary is a multimap rather than a map.
Container Adapters
Container adapters are special predefined containers that are adapted to specific uses. The interesting part about container adapters is that you can choose which sequence container you want them to use.
- A
stackis a container where elements operate in a LIFO (Last In, First Out) context, where elements are inserted (pushed) and removed (popped) from the end of the container. Stacks default to using deque as their default sequence container (which seems odd, since vector seems like a more natural fit), but can use vector or list as well. - A
queueis a container where elements operate in a FIFO (First In, First Out) context, where elements are inserted (pushed) to the back of the container and removed (popped) from the front. Queues default to using deque, but can also use list. - A
priority queueis a type of queue where the elements are kept sorted (via operator<). When elements are pushed, the element is sorted in the queue. Removing an element from the front returns the highest priority item in the priority queue.
STL iterators overview
An Iterator is an object that can traverse (iterate over) a container class without the user having to know how the container is implemented. With many classes (particularly lists and the associative classes), iterators are the primary way elements of these classes are accessed.
An iterator is best visualized as a pointer to a given element in the container, with a set of overloaded operators to provide a set of well-defined functions:
Operator*– Dereferencing the iterator returns the element that the iterator is currently pointing at.Operator++– Moves the iterator to the next element in the container. Most iterators also provideOperator--to move to the previous element.Operator==andOperator!=– Basic comparison operators to determine if two iterators point to the same element. To compare the values that two iterators are pointing at, dereference the iterators first, and then use a comparison operator.Operator=– Assign the iterator to a new position (typically the start or end of the container’s elements). To assign the value of the element the iterator is point at, dereference the iterator first, then use the assign operator.
Each container includes four basic member functions for use with Operator=:
begin()returns an iterator representing the beginning of the elements in the container.end()returns an iterator representing the element just past the end of the elements.cbegin()returns aconst(read-only) iterator representing the beginning of the elements in the container.cend()returns aconst(read-only) iterator representing the element just past the end of the elements.
It might seem weird that end() doesn’t point to the last element in the list, but this is done primarily to make looping easy: iterating over the elements can continue until the iterator reaches end(), and then you know you’re done.
Finally, all containers provide (at least) two types of iterators:
container::iteratorprovides a read/write iteratorcontainer::const_iteratorprovides a read-only iterator
1 |
|
1 |
|
One point worth noting: Iterators must be implemented on a per-class basis, because the iterator does need to know how a class is implemented. Thus iterators are always tied to specific container classes.
STL algorithms overview
In addition to container classes and iterators, STL also provides a number of generic algorithms for working with the elements of the container classes. These allow you to do things like search, sort, insert, reorder, remove, and copy elements of the container class.
Note that algorithms are implemented as global functions that operate using iterators. This means that each algorithm only needs to be implemented once, and it will generally automatically work for all containers that provides a set of iterators (including your custom container classes). While this is very powerful and can lead to the ability to write complex code very quickly, it’s also got a dark side: some combination of algorithms and container types may not work, may cause infinite loops, or may work but be extremely poor performing. So use these at your risk.
min_element and max_element
1 | std::list<int>::const_iterator it; // declare an iterator |
find (and list::insert)
1 | it = find(li.begin(), li.end(), 3); // find the value 3 in the list |
sort and reverse
1 | std::sort(vect.begin(), vect.end()); // sort the list |
Note that sort() doesn’t work on list container classes – the list class provides its own sort() member function, which is much more efficient than the generic version would be.
std::string
std::string and std::wstring
The standard library contains many useful classes – but perhaps the most useful is std::string.
Note: C-style strings will be referred to as “C-style strings”, whereas std::string (and std::wstring) will be referred to simply as “strings”.
Motivation for a string class
In a previous lesson, we covered C-style strings, which uses char arrays to store a string of characters. If you’ve tried to do anything with C-style strings, you’ll very quickly come to the conclusion that they are a pain to work with, easy to mess up, and hard to debug.
1 | char *strHello = new char[7]; |
Fortunately, C++ and the standard library provide a much better way to deal with strings: the std::string and std::wstring classes. By making use of C++ concepts such as constructors, destructors, and operator overloading, std::string allows you to create and manipulate strings in an intuitive and safe manner! No more memory management, no more weird function names, and a much reduced potential for disaster.
There are actually 3 different string classes in the string header. The first is a templated base class named basic_string<>:
1 | namespace std { |
You won’t be working with this class directly, so don’t worry about what traits or an Allocator is for the time being. The default values will suffice in almost every imaginable case.
There are two flavors of basic_string<> provided by the standard library:
1 | namespace std { |
These are the two classes that you will actually use. std::string is used for standard ascii (utf-8) strings. std::wstring is used for wide-character/unicode (utf-16) strings. There is no built-in class for utf-32 strings (though you should be able to extend your own from basic_string<> if you need one).

c_str: Returns the contents of the string as a NULL-terminated C-style stringcopy(): Copies contents (not NULL-terminated) to a character arraydata(): Returns the contents of the string as a non-NULL-terminated character array
std::string construction and destruction
Note: string::size_type resolves to size_t, which is the same unsigned integral type that is returned by the sizeof operator. Its actual size varies depending on environment. For purposes of this tutorial, envision it as an unsigned int.
string()- This is the default constructor. It creates an empty string.
1
std::string sSource;
- This is the default constructor. It creates an empty string.
string(const string& strSource)- This is the copy constructor. This constructor creates a new string as a copy of
strSource.1
2string sSource("old string");
string sOutput(sSource);
- This is the copy constructor. This constructor creates a new string as a copy of
string::string(const string& strSource, size_type unIndex)
string::string(const string& strSource, size_type unIndex, size_type unLength)1
2
3
4
5string sSource("old string");
string sOutput(sSource, 3);
cout << sOutput<< endl;
string sOutput2(sSource, 3, 4);
cout << sOutput2 << endl;string::string(const char *szCString)- This constructor creates a new string from the
C-style string szCString, up to but not including the NULL terminator. - If the resulting size exceeds the maximum string length, the length_error exception will be thrown.
- Warning:
szCStringmust not be NULL.1
2
3const char *szSource("my string");
string sOutput(szSource);
cout << sOutput << endl;
- This constructor creates a new string from the
- more …
Constructing strings from numbers
1 | string sFour(4); |
The easiest way to convert numbers into strings is to involve the std::ostringstream class. std::ostringstream is already set up to accept input from a variety of sources, including characters, numbers, strings, etc. It is also capable of outputting strings (either via the extraction operator>>, or via the str() function).
1 |
|
Note that this solution omits any error checking. It is possible that inserting tX into oStream could fail. An appropriate response would be to throw an exception if the conversion fails.
Converting strings to numbers
1 | template <typename T> |
Too many APIs! Just look them up when I need.
Input and output (I/O)
Input and output (I/O) streams
The iostream library
When you include the iostream header, you gain access to a whole hierarchy of classes responsible for providing I/O functionality (including one class that is actually named iostream). The class hierarchy for the non-file I/O classes looks like this:
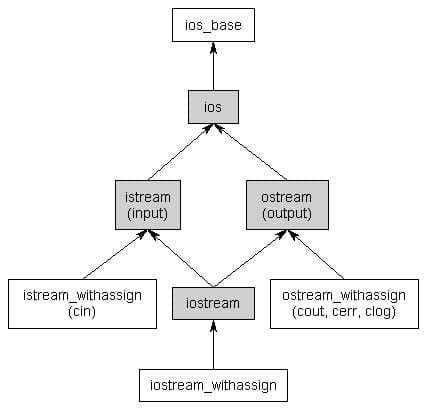
The first thing you may notice about this hierarchy is that it uses multiple inheritance (that thing we told you to avoid if at all possible). However, the iostream library has been designed and extensively tested in order to avoid any of the typical multiple inheritance problems, so you can use it freely without worrying.
Streams
The second thing you may notice is that the word stream is used an awful lot. At its most basic, I/O in C++ is implemented with streams. Abstractly, a stream is just a sequence of characters that can be accessed sequentially. Over time, a stream may produce or consume potentially unlimited amounts of data.
Typically we deal with two different types of streams. Input streams are used to hold input from a data producer, such as a keyboard, a file, or a network.
Conversely, output streams are used to hold output for a particular data consumer, such as a monitor, a file, or a printer. When writing data to an output device, the device may not be ready to accept that data yet.
The nice thing about streams is the programmer only has to learn how to interact with the streams in order to read and write data to many different kinds of devices. (Abstract)
The istream class is the primary class used when dealing with input streams. With input streams, the extraction operator (>>) is used to remove values from the stream. This makes sense: when the user presses a key on the keyboard, the key code is placed in an input stream. Your program then extracts the value from the stream so it can be used.
The ostream class is the primary class used when dealing with output streams. With output streams, the insertion operator (<<) is used to put values in the stream. This also makes sense: you insert your values into the stream, and the data consumer (eg. monitor) uses them.
Standard streams in C++
A standard stream is a pre-connected stream provided to a computer program by its environment. C++ comes with four predefined standard stream objects that have already been set up for your use. The first three, you have seen before:
cin– an istream_withassign class tied to the standard input (typically the keyboard)cout– an ostream_withassign class tied to the standard output (typically the monitor)cerr– an ostream_withassign class tied to the standard error (typically the monitor), providing unbuffered outputclog– an ostream_withassign class tied to the standard error (typically the monitor), providing buffered output
Unbuffered output is typically handled immediately, whereas buffered output is typically stored and written out as a block. Because clog isn’t used very often, it is often omitted from the list of standard streams.
Input with istream
When reading strings, one common problem with the extraction operator is how to keep the input from overflowing your buffer. Given the following example:
1 | char buf[10]; |
what happens if the user enters 18 characters? The buffer overflows, and bad stuff happens. Generally speaking, it’s a bad idea to make any assumption about how many characters your user will enter.
One way to handle this problem is through use of manipulators. A manipulator is an object that is used to modify a stream when applied with the extraction (>>) or insertion (<<) operators. One manipulator you have already worked with extensively is endl, which both prints a newline character and flushes any buffered output. C++ provides a manipulator known as setw (in the iomanip.h header) that can be used to limit the number of characters read in from a stream. To use setw(), simply provide the maximum number of characters to read as a parameter, and insert it into your input statement like such:
1 |
|
This program will now only read the first 9 characters out of the stream (leaving room for a terminator). Any remaining characters will be left in the stream until the next extraction.
Extraction and whitespace
The one thing that we have omitted to mention so far is that the extraction operator works with “formatted” data – that is, it skips whitespace (blanks, tabs, and newlines).
1 | char ch; |
When the user inputs the following:
1 | Hello my name is Alex |
The extraction operator skips the spaces and the newline. Consequently, the output is:
1 | HellomynameisAlex |
Oftentimes, you’ll want to get user input but not discard whitespace. To do this, the istream class provides many functions that can be used for this purpose.
One of the most useful is the get() function, which simply gets a character from the input stream. Here’s the same program as above using get():
1 | char ch; |
One important thing to note about get() is that it does not read in a newline character! This can cause some unexpected results:
1 | char strBuf[11]; |
Why didn’t it ask for 10 more characters? The answer is because the first get() read up to the newline and then stopped. The second get() saw there was still input in the cin stream and tried to read it. But the first character was the newline, so it stopped immediately.
Consequently, there is another function called getline() that works exactly like get() but reads the newline as well.
1 | char strBuf[11]; |
If you need to know how many character were extracted by the last call of getline(), use gcount():
1 | char strBuf[100]; |
Version for std::string
1 | std::string strBuf; |
A few more useful istream functions
There are a few more useful input functions that you might want to make use of:
ignore()discards the first character in the stream.
ignore(int nCount) discards the first nCount characters.peek()allows you to read a character from the stream without removing it from the stream.unget()returns the last character read back into the stream so it can be read again by the next call.putback(char ch)allows you to put a character of your choiceback into the streamto be read by the next call.
Output with ostream and ios
The insertion operator
The insertion operator (<<) is used to put information into an output stream. C++ has predefined insertion operations for all of the built-in data types, and you’ve already seen how you can overload the insertion operator for your own classes.
Formatting
There are two ways to change the formatting options: flags, and manipulators. You can think of flags as boolean variables that can be turned on and off. Manipulators are objects placed in a stream that affect the way things are input and output.
To switch a flag on, use the setf() function, with the appropriate flag as a parameter. For example, by default, C++ does not print a + sign in front of positive numbers. However, by using the std::showpos flag, we can change this behavior:
1 | std::cout.setf(std::showpos); |
There’s one other bit of trickiness when using setf() that needs to be mentioned. Many flags belong to groups, called format groups. A format group is a group of flags that perform similar (sometimes mutually exclusive) formatting options. For example, a format group named “basefield” contains the flags “oct”, “dec”, and “hex”, which controls the base of integral values. By default, the “dec” flag is set. Consequently, if we do this:
1 | std::cout.setf(std::hex); // try to turn on hex output |
It didn’t work! The reason why is because setf() only turns flags on – it isn’t smart enough to turn mutually exclusive flags off. Consequently, when we turned std::hex on, std::dec was still on, and std::dec apparently takes precedence. There are two ways to get around this problem.
1 | std::cout.unsetf(std::dec); // turn off decimal output |
The second way is to use a different form of setf() that takes two parameters: the first parameter is the flag to set, and the second is the formatting group it belongs to. When using this form of setf(), all of the flags belonging to the group are turned off, and only the flag passed in is turned on. For example:
1 | // Turn on std::hex as the only std::basefield flag |
Using setf() and unsetf() tends to be awkward, so C++ provides a second way to change the formatting options: manipulators. The nice thing about manipulators is that they are smart enough to turn on and off the appropriate flags. Here is an example of using some manipulators to change the base:
1 | std::cout << std::hex << 27 << '\n'; // print 27 in hex |
Other useful formatters:
1 | std::cout << true << " " << false << '\n'; |
Precision, notation, and decimal points
1 | // fixed - demical notaiton |
If neither fixed nor scientific are being used, precision determines how many significant digits should be displayed. Again, if the precision is less than the number of significant digits, the number will be rounded.
Width, fill characters, and justification
1 | std::cout << -12345 << '\n'; // print default value with no field width |
One thing to note is that setw() and width() only affect the next output statement. They are not persistent like some other flags/manipulators.
Stream classes for strings
So far, all of the I/O examples you have seen have been writing to cout or reading from cin. However, there is another set of classes called the stream classes for strings that allow you to use the familiar insertions (<<) and extraction (>>) operators to work with strings. Like istream and ostream, the string streams provide a buffer to hold data. However, unlike cin and cout, these streams are not connected to an I/O channel (such as a keyboard, monitor, etc…). One of the primary uses of string streams is to buffer output for display at a later time, or to process input line-by-line.
There are six stream classes for strings:
istringstream(derived from istream)ostringstream(derived from ostream)stringstream(derived from iostream) are used for reading and writing normal characters width strings.wistringstream,wostringstream, andwstringstreamare used for reading and writing wide character strings. To use the stringstreams, you need to #include thesstreamheader.
There are two ways to get data into a stringstream:
It Can be used in conversion.
Use the insertion (<<) operator:
1 | stringstream os; |
Use the str(string) function to set the value of the buffer:
1 | stringstream os; |
There are similarly two ways to get data out of a stringstream:
Use the str() function to retrieve the results of the buffer:
1 | stringstream os; |
Use the extraction (>>) operator.
Conversion between strings and numbers
1 | stringstream os; |
Clearing a stringstream for reuse
1 | os.str(""); // erase the buffer |
Stream states and input validation
Stream states
The ios_base class contains several state flags that are used to signal various conditions that may occur when using streams:

Although these flags live in ios_base, because ios is derived from ios_base and ios takes less typing than ios_base, they are generally accessed through ios (eg. as std::ios::failbit).
ios also provides a number of member functions in order to conveniently access these states:
- good()
- bad()
- eof()
- fail()
- clear(): clear all flags and restore the stream to goodbit state
The most commonly dealt with bit is the failbit, which is set when the user enters invalid input. For example, consider the following program:
1 | cout << "Enter your age: "; |
Note that this program is expecting the user to enter an integer. However, if the user enters non-numeric data, such as “Alex”, cin will be unable to extract anything to nAge, and the failbit will be set.
If an error occurs and a stream is set to anything other than goodbit, further stream operations on that stream will be ignored. This condition can be cleared by calling the clear() function.
Input validation
Input validation is the process of checking whether the user input meets some set of criteria. Input validation can generally be broken down into two types: string and numeric.
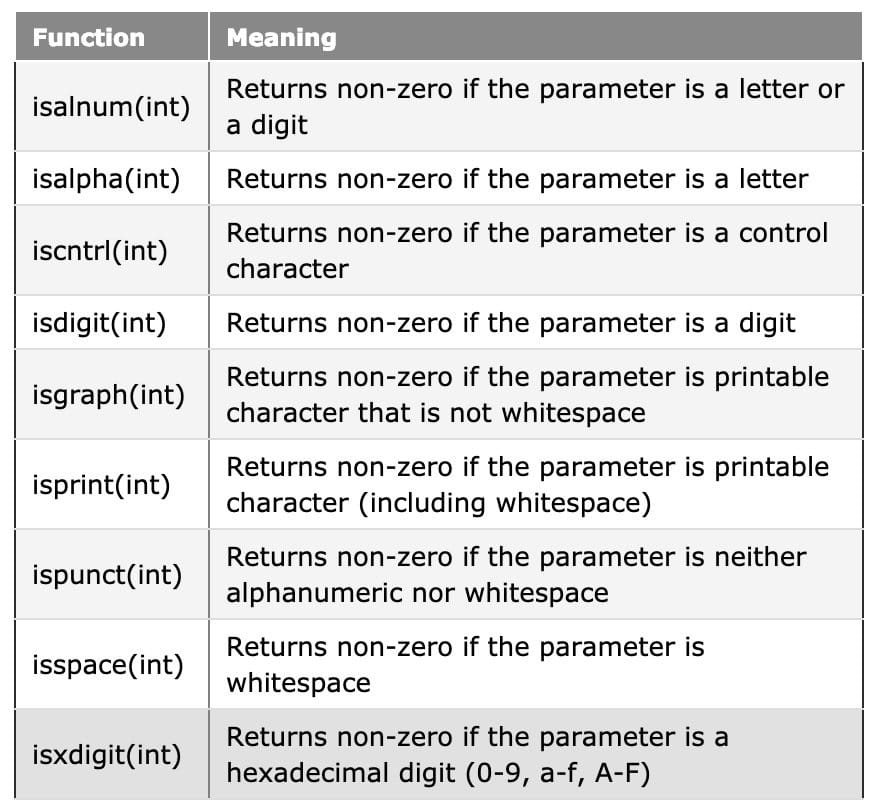
Numeric validation
1 | int nAge |
Numeric validation as a string
1 | int nAge; |