概要
C 语言是「古怪的、有缺陷的,但同时也是一个巨大的成功」。Why?
- 与 Unix 操作系统关系密切。
- C 语言小而简单。
- C 语言是为实践目的设计的。
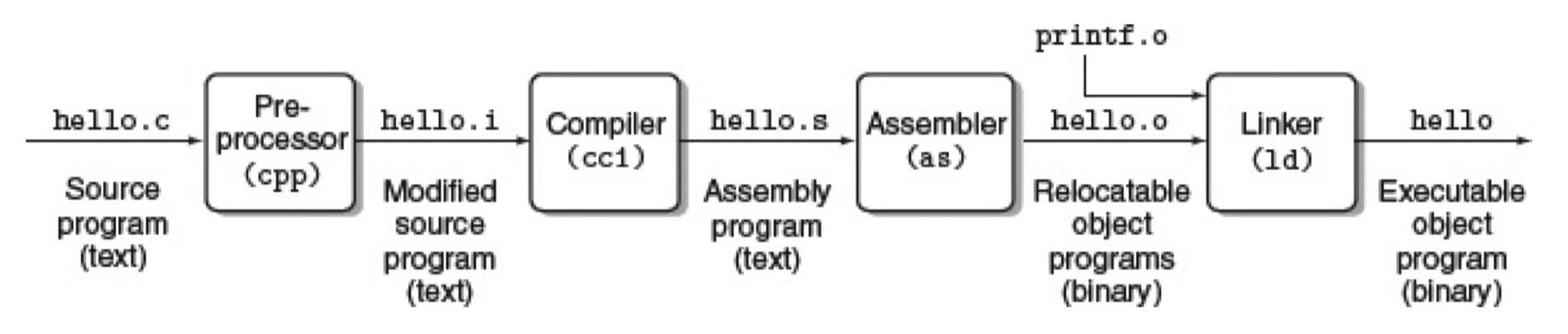
编译系统的流程
系统的硬件组成
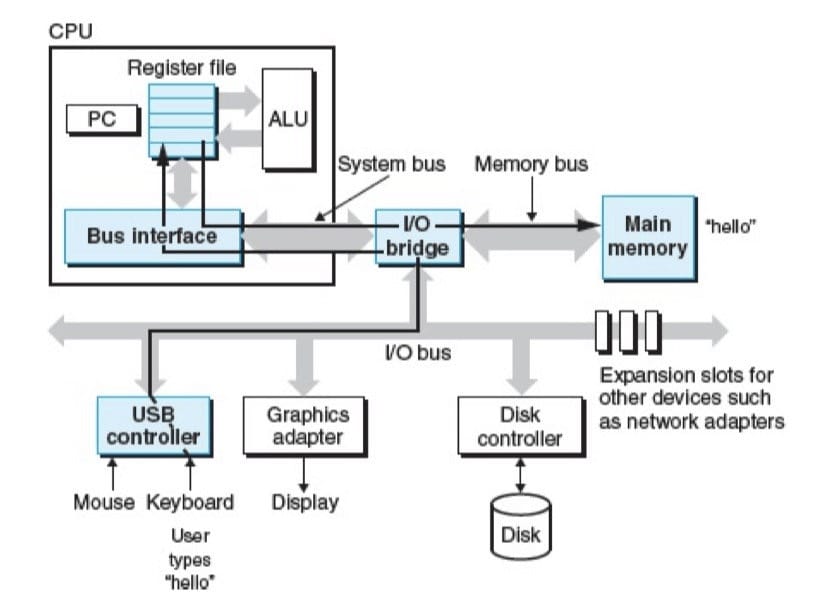
总线
贯穿整个系统的是一组电子管道,称作总线,它携带信息字节并负责在各个部件间传递。通常总线被设计成传送定长的字节块,也就是字(word)。字中的字长数是一个基本的系统参数,各个系统不同。现在的大多数机器字长要么是 4 个字节(32位),要么是 8 个字节(64位)。
I/O 设备
每个 I/O 设备都通过一个控制器或适配器与 I/O 总线相连。控制器与适配器之间的区别主要是它们不同的封装方式。控制器是 I/O 设备本身或者系统的主印刷电路板(主板)上的芯片组;而适配器则是一块插在主板插槽上的卡。但是,它们的功能都是在 I/O 总线和 I/O 设备之间传递信息。
主存
主存是由一组动态随机存取存储器(DRAM)芯片组成的硬件。
处理器
处理器是解释(或执行)存储在主存中指令的引擎。处理器的核心是一个大小为一个字的存储设备(或寄存器),称为程序计数器(PC)。在任何时刻,PC 都指向主存中的某条机器语言指令(即含有该条指令的地址)。
从系统通电开始,直到系统断电,处理器一直在不断地执行程序计数器指向的指令,再更新程序计数器,使其指向下一条指令。处理器看上去是按照一个非常简单的指令执行模型来操作的,这个模型是由指令集架构决定的。(下一条指令不一定和内存中刚刚执行的指令相邻)
CPU 在指令的要求下可能会执行这些操作:
加载:从主存复制一个字节或者一个字到寄存器。存储:从寄存器复制一个字节或者一个字到主存的某个位置。操作:把两个寄存器的内容复制到 ALU,ALU 对这两个字做算术运算,并把结果存放到一个寄存器中,以覆盖该寄存器中原来的内容。跳转:从指令本身中抽取一个字,并将这个字复制到 PC 中,以覆盖 PC 中原来的值。
操作系统管理硬件
操作系统是应用程序和硬件之间插入的一层软件,所有应用程序对硬件的操作尝试都必须通过操作系统。

操作系统有两个基本功能:
防止硬件被失控的应用程序滥用- 向应用程序提供
简单一致的机制(接口)来控制复杂而又通常不大相同的低级硬件设备
操作系统通过几个基本的抽象概念(进程、虚拟内存和文件)来实现这两个功能。
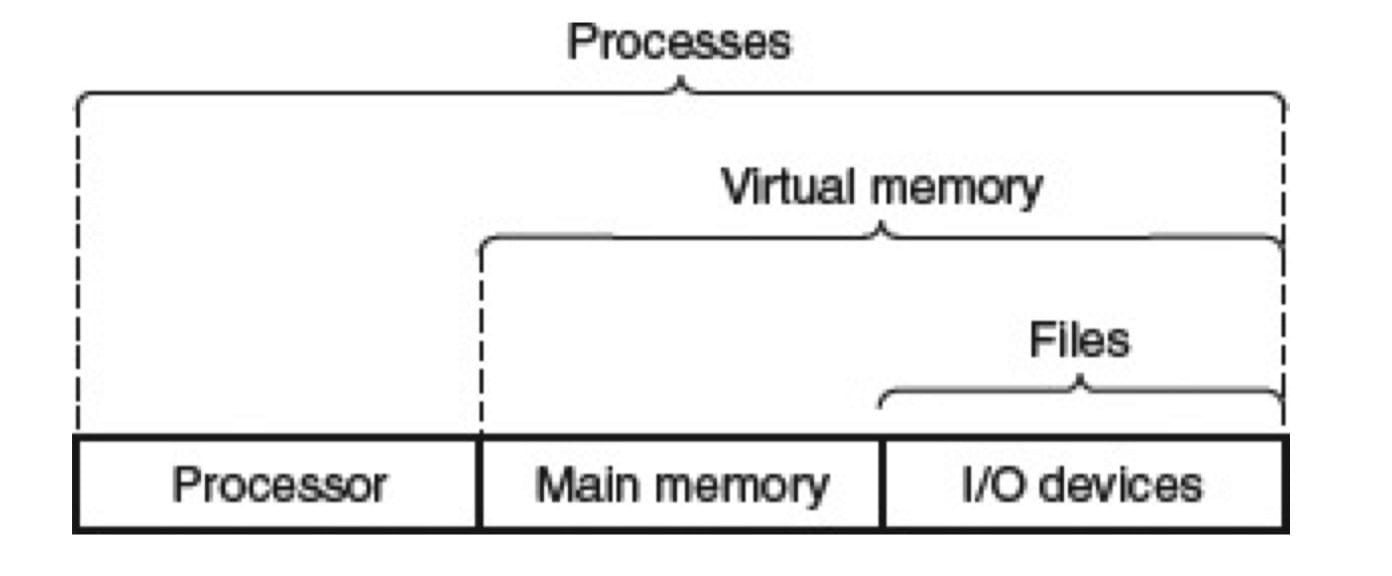
进程
进程(Process)是操作系统对一个正在运行的程序的一种抽象。在一个系统上可以同时运行多个进程,而每个进程都好像在独占地使用硬件。并发运行,是说一个进程的指令和另一个进程的指令是交错执行的。操作系统实现这种交错执行的机制称为上下文切换(context switch)。
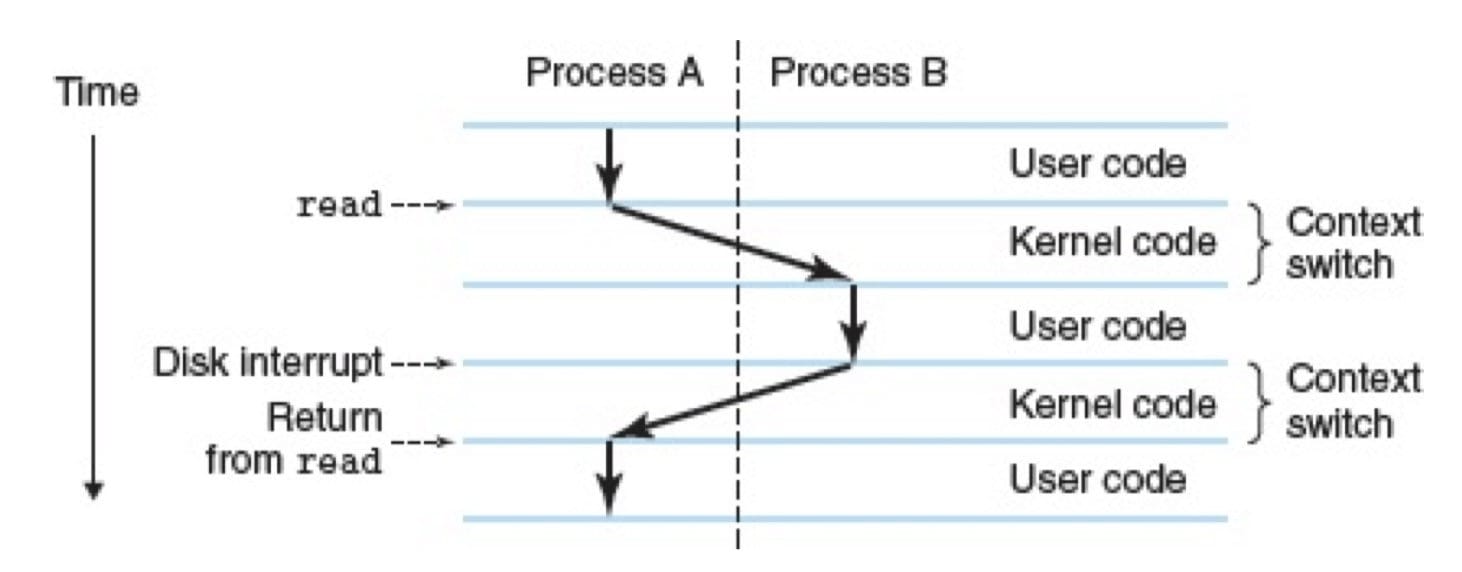
操作系统保持跟踪进程运行所需的所有状态信息,这种状态,也就是上下文,比如包括 PC 和寄存器文件的当前值,以及主存的内容。从一个进程到另一个进程是由操作系统内核管理的。
虚拟内存
每个进程看到的内存都是一致的,称为虚拟地址空间 (virtual memory space)。
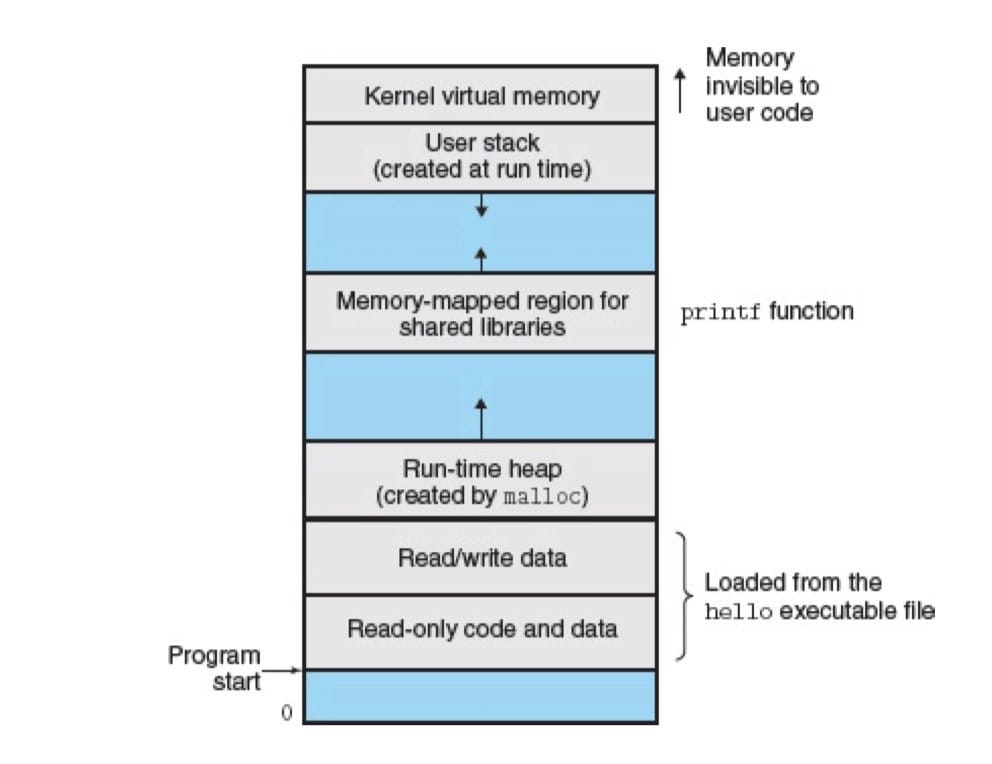
虚拟内存的运作需要硬件和操作系统软件之间精密复杂的交互,包括对处理器生成每个地址的硬件翻译。基本思想是把一个进程虚拟内存的内容存储在磁盘上,然后用主存作为磁盘的高速缓存。
文件
文件就是字节序列,仅此而已。设备可以看作是文件。
重要主题
Amdahl 定律
主要思想:当我们对系统的某个部分加速时,其对系统整体性能的影响取决于该部分的重要性 $\alpha$ 和加速程度 $k$。
主要观点:想要显著加速整个系统,必须提升全系统中相当大的部分的速度。
原来的执行时间:
$$T_{old} = (1-\alpha)T_{old} + \alpha{T_{old}}$$
总的执行时间 $T_{new}$:
$$T_{new} = (1-\alpha) T_{old} + \frac{\alpha T_{old}}{k} = T_{old}[(1-\alpha) + \frac{\alpha}{k}]$$
加速比 $S$:
$$S = \frac{T_{old}}{T_{new}} = \frac{1}{(1 - \alpha) + \frac{\alpha}{k}}$$
并发与并行
并发(concurrency)是一个通用的概念,指一个同时具有多个活动的系统(各个进程的指令交错执行)。并行(parallelism)指的是用并发来使一个系统运行得更快。并行可以在计算机系统的多个抽象层次上运用。一般有三个层次:线程级并发、指令级并行、单指令多数据并行。
指令级并行是指现代处理器可以同时执行多条指令的属性。
超线程,有时称为同时多线程(simultaneous multi-threading)是一项允许一个 CPU 执行多个控制流的技术。它涉及 CPU 某些硬件有多个备份,比如程序计数器和寄存器文件,而其它的硬件部分只有一份,比如浮点算术运算单元。
三个周期的关系:
指令周期:读取并执行一条指令的时间。CPU 周期(机器周期):从内存读取一条指令字的最短时间。T 周期(时钟周期):是处理操作的基本单位,其倒数是 CPU 主频。
计算机系统中抽象的重要性
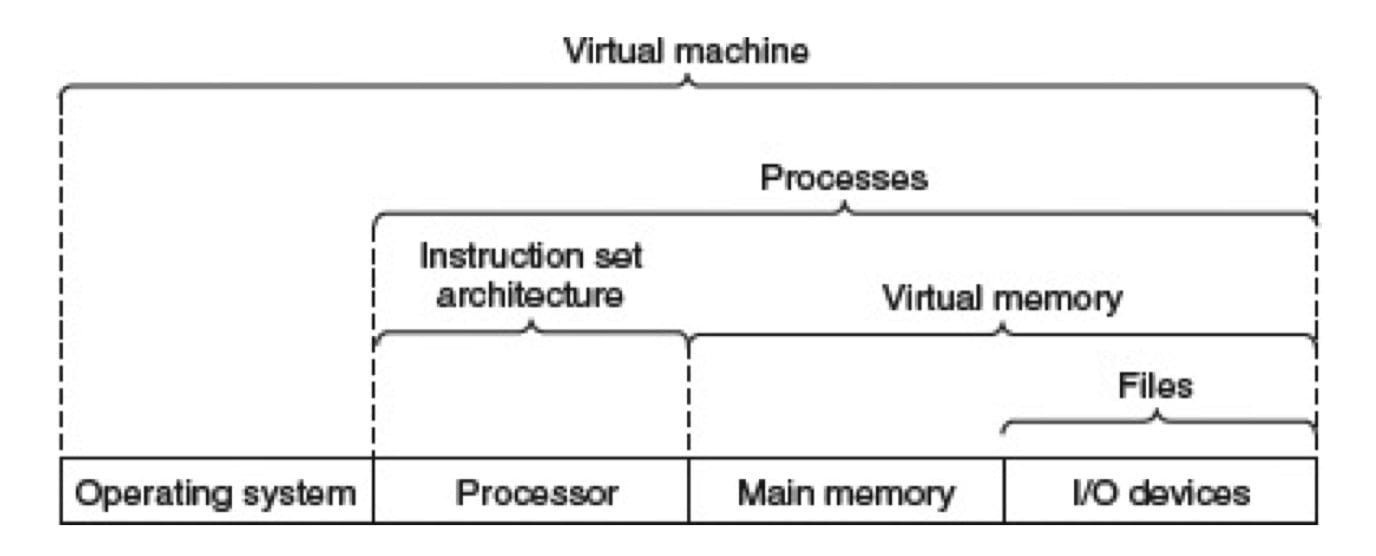
虚拟机:通过软件模拟具有完整硬件系统功能的操作系统。
信息的表示和处理
概念
Possible encoding methods of 52 cards:
- “one-hot” encoding: 52 bits
- “two-hot” encoding: 4 bits for suits, 13 bits for values
- binary encoding: 6 bits
- better binary encoding: 2 bits for suits, 4 bits for values
1 | SUIT_MASK = 0x0030 // 0011 0000 get suit |
最高有效位 MSB (most significant bit),即对数值影响最大的一位,对应 LSB。
三种最重要的数字表示(number representation):
无符号(unsigned)编码:基于传统二进制表示法表示大于或者等于零的数字。补码(two’s-complement)编码:表示有符号整数的最常见的方式。浮点数(floating-point)编码:表示实数的科学记数法以 2 为基数的版本。
其它术语:反码(Ones’ Complement)、原码(Sign-Magnitude,用于浮点数表示中)。
C++ 编程语言建立在 C 语言基础之上,它们使用完全相同的数字表示和运算。另一方面,Java 语言创造了一套新的数字表示和运算标准。C 标准中的设计允许多种实现方式,而 Java 标准在数据的格式和编码上是非常精确具体的。
在 Java 中,它要求采用补码表示,单字节数据类型称为byte,而不是char。这些非常具体的要求都是为了保证无论在什么机器上运行,Java 程序都能表现地完全一样。
尽管 C 编译器维护着类型信息,但是它生成的实际机器级程序并不包含关于数据类型的信息(都是偏移量)。理解指针的重要性之一是机器级上的表示以及实现是基于指针的方式(地址 + 偏移量)。
向前兼容(forward / upward compatibility):
- Windows 3.1 要能运行为 Windows 10 开发的程序
向后兼容(backward / downward compatibility):
- Windows 10 要能运行为 Windows 3.1 开发的程序
- 大多数 64 位机器可以运行 32 位机器编译的程序
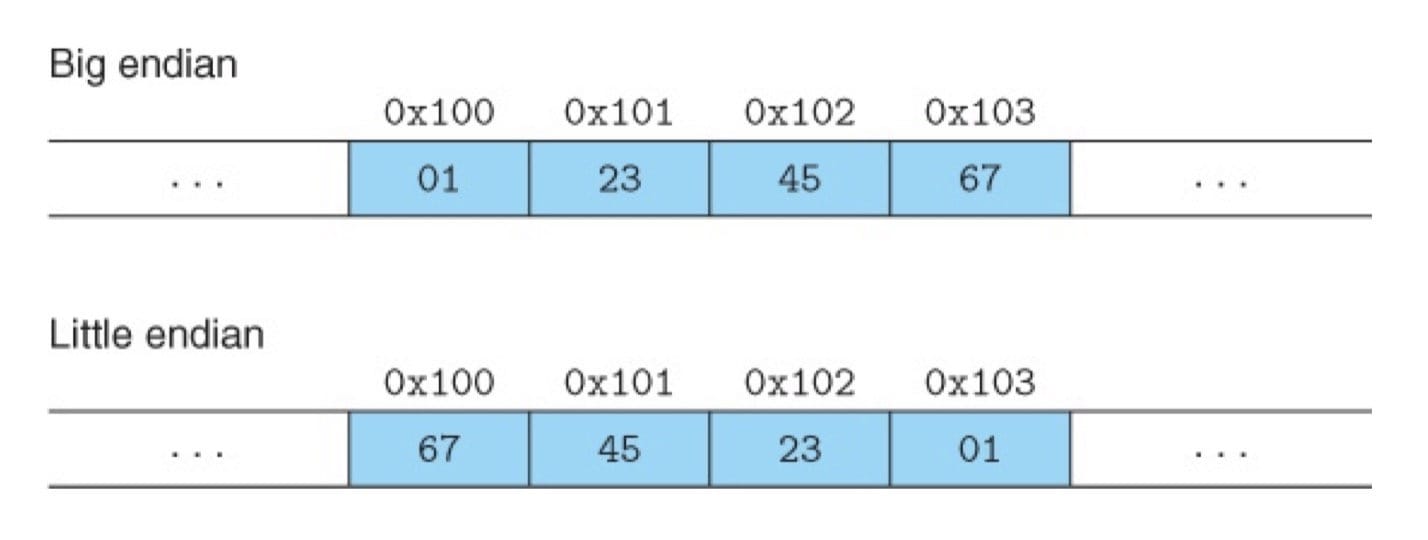
小端法(little endian):最低有效字节在最前面(低地址)的方式。
大端法(big endian):最高有效字节在最前面的方式。
- 大多数 Intel 兼容机都只用小端模式。
- IBM 和 Oracle 的大多数机器则是按照大端模式操作(除了使用 Intel 处理器的机器)。
- 许多比较新的微处理器是
双端法(big-endian),一旦选择特定的操作系统就可以确定下来,如 Android 和 iOS 运行于小端模式。
该术语出自 Jonathan Swift 的《格利弗游记》(Gulliver’s Travels),其中交战的两个派别无法就应该从哪一端打开一个半熟的鸡蛋达成一致。
C 语言的强制类型转换不会改变真实的指针,而只是告诉编译器以新的数据类型来看待被指向的数据。
二进制代码很少能在不同机器和操作系统组合之间移植,所以要抽象。
C 语言标准并没有要求用补码形式来表示有符号整数,但是几乎所有的机器都是这么做的。
在 C 头文件 limits.h 中,使用了这样的写法:
1 |
补码表示的不对称性和 C 语言的转换规则之间奇怪的交互,迫使我们使用这种不寻常的方式来写。这是一个好的习惯。
乘法 / 除法运算:
以往,在大多数机器上,整数乘法指令相当慢,需要 10 个或者更多的时钟周期,然而其他整数运算(例如加法、减法、位级运算和移位)只需要 1 个时钟周期。即使在 Intel Core i7 Haswell 上,其整数乘法也需要 3 个时钟周期。因此,编译器使用了一项重要的优化,试着用移位和加法运算的组合来代替乘以常熟因子的乘法。
由于整数乘法比移位和加法的代价要大得多,许多 C 语言编译器试图以移位、加法和减法的组合来消除很多整数乘以常数的情况。例如,x * 14会变成(x<<3) + (x<<2) + (x<<1)。
在大多数机器上,整数除法比整数乘法更慢——需要 30 个或者更多的时钟周期。除以 2 的幂也可以用移位运算来实现,只不过我们用的是右移,而不是左移。无符号和补码数分别使用逻辑移位和算术移位来达到目的。
浮点数
二进制小数
一个图说明二进制小数表示法($b_m b_{m-1}\cdots b_1 b_0\ .\ b_{-1} b_{-2} \cdots b_{-n-1} b_{-n}$):
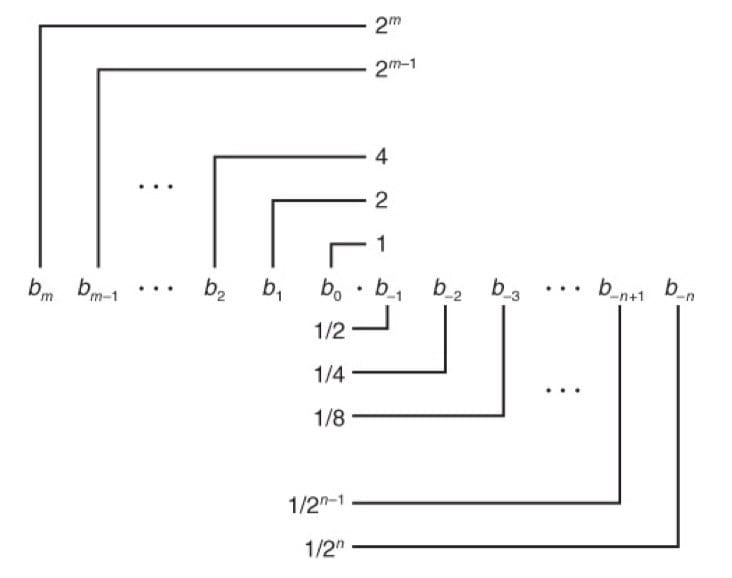
注意,形如 $0.11\cdots 1_2$ 的数表示的是刚好小于 1 的数。例如,$0.111111_2$ 表示 $\frac{63}{64}$。小数的二进制表示只能表示够被写成 $x \times 2^y$ 的数,如数 $\frac{1}{5}$ 不可以被精确表示。
IEEE 浮点数表示
IEEE 浮点标准用 $V = (-1)^s \times M \times 2^E$ 的形式来表示一个数:
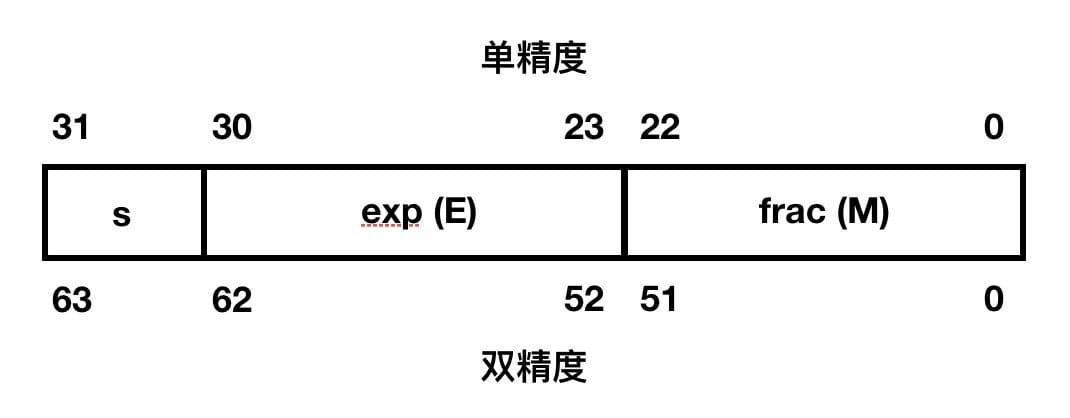
符号(sign):决定这个数的符号,而对于数值为 0 的符号位将会通过特殊情况处理。尾数(significand):M 是一个二进制小数,它的范围是 $1 \sim 2-\epsilon$,或者是 $0 \sim 1-\epsilon$。阶码(exponent):E 的作用是对浮点数加权,这个权重是 2 的 E 次幂(可能是负数)。
将浮点数的位表示划分为三个字段,分别对这些值进行编码:
- 一个单独的符号位 s 直接编码符号 s。
- k 位的阶码字段 $exp = e_{k-1}\cdots e_1 e_0$ 编码阶码 E。
- n 位小数字段 $frac = f_{n-1} \cdots f_1 f_0$ 编码尾数 M,但是编码出来的值也依赖于阶码字段的值是否等于 0。
给定位表示,根据exp的值,被编码的值可以分成三种不同的情况(最后一种情况有两个变种):
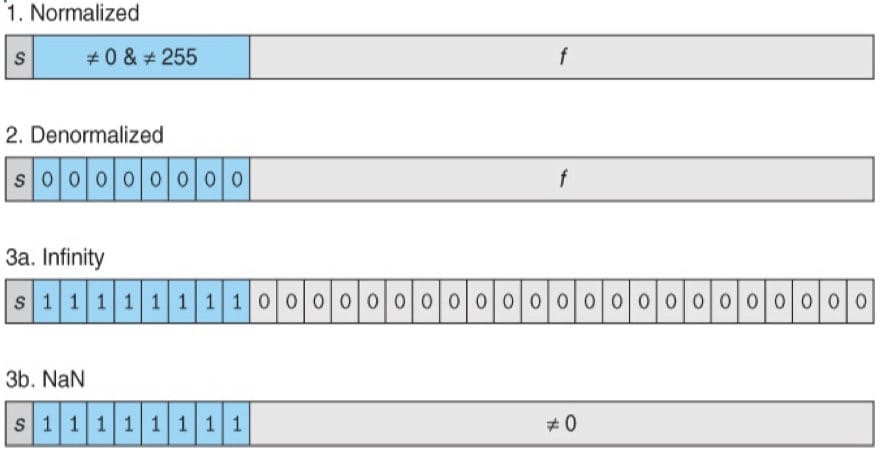
情况 1:规格化的值(Normalized)
在这种情况下,阶码字段被解释为以偏置(biased)形式表示的有符号整数。也就是说,阶码的值是 $E=e-Bias$,其中 e 是无符号整数,对应具体的位表示,而 Bias 是一个等于 $2^{k-1} - 1$(单精度是 127,双精度是 1023)的偏置值,由此分别产生范围是-126 ~ +127和-1022 ~ +1023的整数。
小数字段 frac 被解释为描述小数值 $f$,其中 $0 \leq f < 1$,而实际的尾数定义为 $M = 1+f$。有时,这种方式也叫做隐含的以 1 开头的表示(implied leading 1),以表示 $1.f_{n-1}f_{n-2}\cdots f_0$ 的数字,其范围在原来的基础上加 1。
情况 2:非规格化的值(Denormalized)
阶码位全为 0。在这种情况下,阶码值是 $E=1-Bias$(使用 1 是因为可以提供一种从非规格化值平滑转换到规格化值的方法,可以补偿非规格化数的尾数没有隐含的开头的 1),而尾数的值是 $M=f$,也就是小数字段的值,不好隐含的 1。
非规格化有两个用途:
- 首先,它们提供了一种表示数值 0 的方法,但存在
+0.0和-0.0两种情况,其在某些方面被认为是不同的。 - 其次,它还可以表示那些非常接近于 0.0 的数。它们提供了一种属性,称为
逐渐溢出(gradual underflow),其中,可能的数值分布均匀地接近于 0.0。
情况 3:特殊值
阶码位全为 1。当小数域全为 0 时,得到的值表示无穷,当 s = 0 时是正无穷,s = 1 时是负无穷。当我们把两个非常大的数相乘,或者除以 0 时,无穷能够表示溢出的结果。当小数域为非 0 时,结果值被称为NaN,即不是一个数的英文缩写,如计算 $\sqrt{-1}$、$\infty-\infty$。在某些应用中,表示未初始化的数据时,它们也很有用处。
1 | 12345 (10) = 11000000111001 (2) |
舍入(Rounding)
一个关键的问题是如何在两个可能值的中间确定舍入方向。IEEE 浮点格式定义了四种不同的舍入方式。默认的方法是找到最接近的匹配,而其他三种方法可用于计算上界和下界。
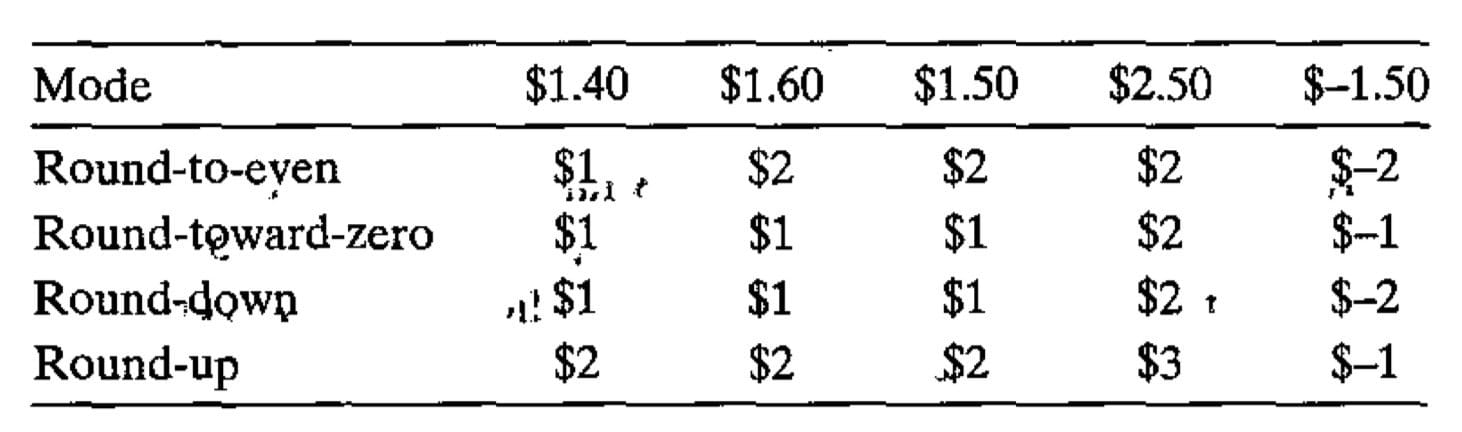
向偶舍入(也被称为向最接近的值舍入,round-to-nearest):将数字向上或者向下舍入,使得结果的最低有效数字是偶数,如 1.5 和 2.5 都舍入成 2。向零舍入:把正数向下舍入,把负数向上舍入。
始终向一个方向舍入会在计算这些值的平均数中引入统计偏差,最后得到的平均值可能会比本身的平均值略高或者略低一些。向偶舍入在大多数现实情况中避免了这种统计偏差。
浮点运算
IEEE 标准中指定浮点运算行为方法的一个优势在于,它可以独立于任何具体的硬件或者软件实现,因此,我们只需要检查它的抽象数学属性是否正确即可。
浮点加法不具有结合性,这是缺少的最重要的群属性。
1 | x = a + b + c; |
编译器可能试图通过产生下列代码来省去一个浮点加法:
1 | t = b + c; |
然而,对于 x 来说,这个计算可能会产生与原始值不同的值,因为它使用了加法运算的不同的结合方式。不幸的是,编译器无法知道在效率和忠实于原始程序的确切行为之间,使用者愿意做出什么样的选择。结果是,编译器倾向于保守,避免任何对功能产生影响的优化,即使是很轻微的影响。
此外,浮点运算还缺少分配性。
1 | (3.14 + 1e10) - 1e10 != 3.14 + (1e10 - 1e10); |
C 语言标准不要求机器使用 IEEE 浮点,所以没有标准的方法来改变舍入方式或者得到诸如 -0、正无穷、负无穷 或者 NaN 之类的特殊值。