从给处理器加电开始,直到断电为止,程序计数器假设一个值的序列:
$$a_0, a_1, \cdots, a_{n-1}$$
其中,每个 $a_k$ 是某个相应的指令 $I_k$ 的地址。每次从 $a_k$ 到 $a_k+1$ 的过渡称为控制转移(control transfer)。这样的控制转移序列叫做处理器的控制流(flow of control or control flow)。
最简单的一种控制流是一个平滑的序列,其中每个 $I_k$ 和 $I_{k+1}$ 在内存中都是相邻的。这种平滑流的突变通常是由跳转、调用和返回这样一些熟悉的程序指令造成的。
现代系统通过使控制流发生突变来做出反应。一般而言,我们把这些突变称为异常控制流(Exceptional Control Flow,ECF)。异常控制流发生在计算机系统的各个层次。比如:
硬件层:硬件检测到的事件会触发控制突然转移到异常处理程序。操作系统层:内核通过上下文切换将控制从一个用户进程转移到另一个用户进程。应用层:一个进程可以发送信号到另一个进程,而接收者会将控制突然转移到它的一个信号处理程序。
作为程序员,理解 ECF 很重要,因为:
- 帮助理解重要的系统概念。ECF 是操作系统用来实现 I/O、进程和虚拟内存的
基本机制。 - 帮助理解应用程序是如何与操作系统交互的。应用程序通过使用一个叫做
陷阱(trap)或者系统调用(system call)的 ECF 形式,向操作系统请求服务。 - 帮助编写有趣的新应用程序。操作系统为应用程序提供了强大的
ECF 机制,用来创建新进程、等待进程终止、通知其他进程系统中的异常事件,以及检测和响应这些事件。 - 帮助你理解并发。ECF 是计算机系统中
实现并发的基本机制。并发的例子有:中断应用程序执行的异常处理程序、在时间上重叠执行的进程和线程,以及中断应用程序执行的信号处理程序。 - 帮助理解软件异常如何工作。像
C++和Java这样的语言通过 try、catch 以及 throw 语句(属于应用级 ECF)来提供软件异常机制。软件异常允许程序进行非本地跳转(即违反通常的调用 / 返回栈规则的跳转)来响应错误情况。
异常
异常是异常控制流的一种形式,它一部分由硬件实现,一部分由操作系统实现。异常是控制流中的突变,用来响应处理器状态中的某些变化。下图体现其基本思想:
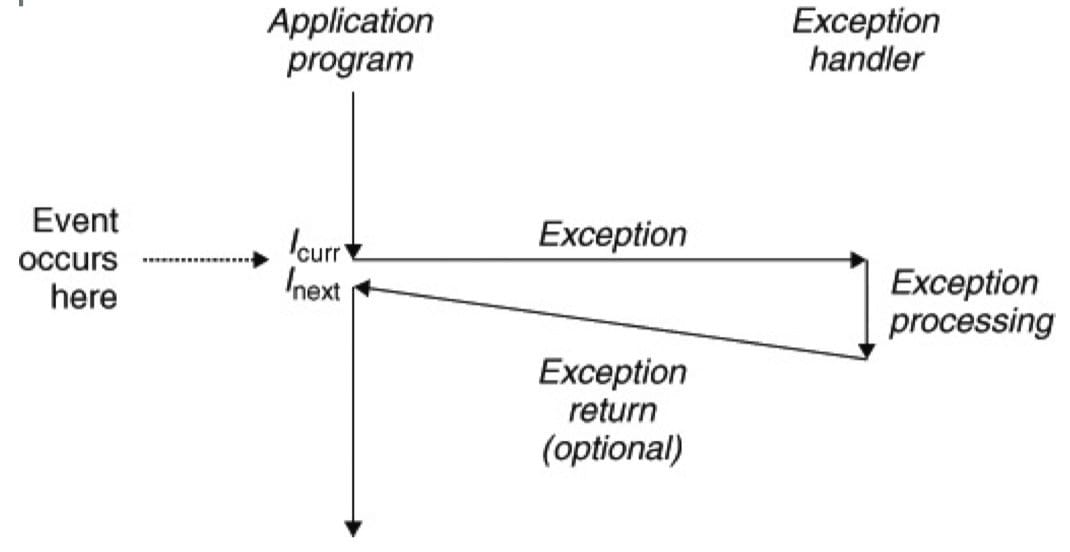
在图中,当处理器状态中发生一个重要的变化时,处理器正在执行某个当前指令 $I_{curr}$。在处理器中,状态被编码为不同的位和信号。状态变化成为事件(event)。事件可能和当前指令相关,比如虚拟内存缺页、算术溢出。事件也可能和当前指令无关,如一个系统定时器产生信号或者一个 I/O 请求完成。
在任何情况下,当处理器检测到有事件发生时,它会通过一张叫做异常表(exception table、interrupt vectors 中断向量表)的跳转表,进行一个间接过程调用(异常),到一个专门设计用来处理这类事件的操作系统子程序(异常处理程序,exception handler)。当异常处理程序完成处理后,根据引起异常的事件的类型,会发生以下三种情况之一:
- 处理程序将控制返回给当前指令 $I_{curr}$
- 处理程序将控制返回给下一调指令 $I_{next}$
- 处理程序终止被中断的程序
异常处理
系统中可能的每种类型的异常都分配了一个唯一的非负整数的异常号(exception number)。其中一些号码是由处理器的设计者分配的(零除、缺页、内存访问违例、算术溢出),其他号码是由操作系统内核的设计者分配的(系统调用)。
在系统启动后,操作系统分配和初始化一张称为异常表的跳转表,使得表目 k包含异常 k的处理程序的地址。
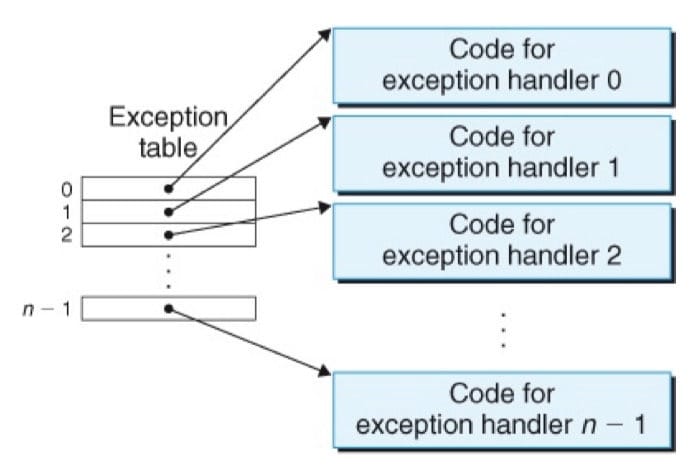
异常表的起始地址放在一个叫做异常表基址寄存器(exception table base register)的特殊 CPU 寄存器里。
异常和过程调用的区别:
- 异常处理程序的返回地址要么是当前指令,要么是下一条指令;而过程调用在跳转前将返回地址压入栈中。
- 异常处理中处理器也把一些额外的处理器状态压到栈中。
- 如果控制从用户程序转移到内核,所有这些项目都被压到
内核栈中,而不是压到用户栈中。 - 异常处理程序运行在内核模式下,意味着它们对所有的系统资源都有
完全的访问权限。
异常的类别
| 类别 | 原因 | 异步/同步 | 返回行为 |
|---|---|---|---|
| 中断(interrupt) | 来自 I/O 设备的信号 | 异步 | 总是返回到下一条指令 |
| 陷阱(trap) | 有意的异常 | 同步 | 总是返回到下一条指令 |
| 故障(fault) | 潜在可恢复的错误 | 同步 | 可能返回到当前指令 |
| 终止(abort) | 不可恢复的错误 | 同步 | 不会返回 |
中断
中断是异步发生的(generated externally),是来自处理器外部的 I/O 设备的信号的结果。硬件中断不是由任何一条专门的指令造成的,从这个意义上来说它是异步的。硬件中断的异常处理程序常常称为中断处理程序(interrupt handler)。

剩下的异常类型是同步发生的(generated internally),是执行当前指令的结果。我们把这类指令叫做故障指令(faulting instruction)

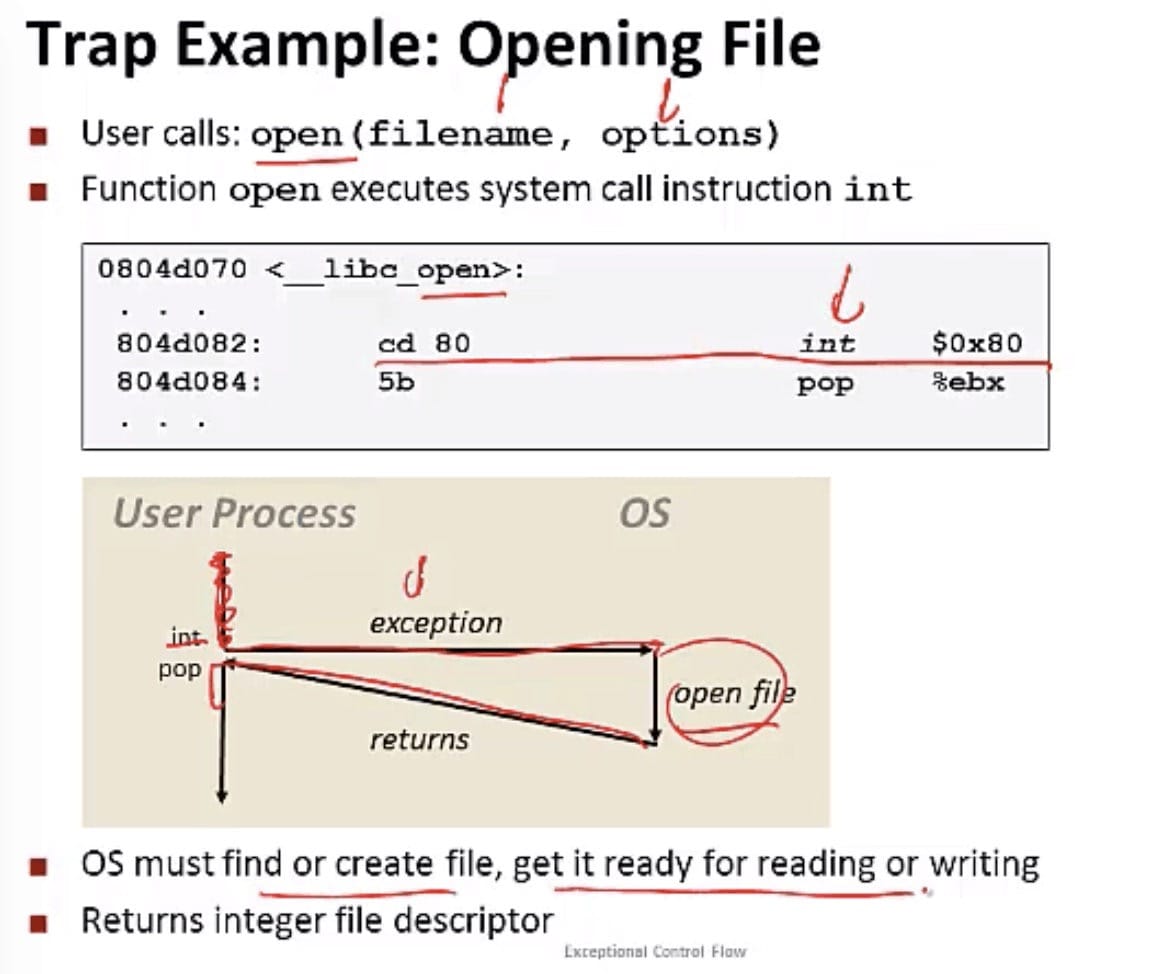
陷阱和系统调用
陷阱是有意的异常,是执行一条指令的结果。陷阱最重要的用途是在用户程序和内核之间提供一个像过程一样的接口,叫做系统调用。
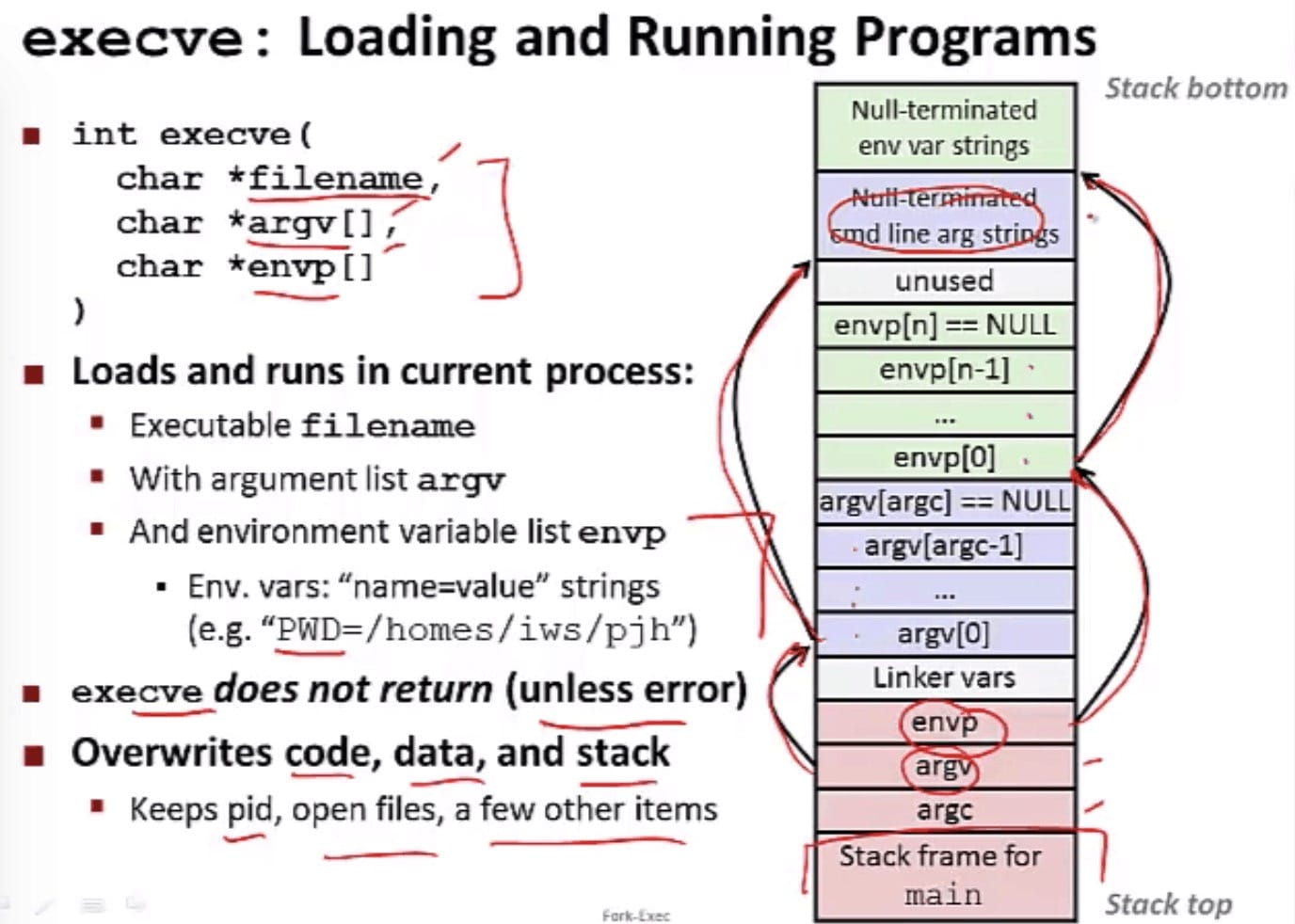
用户程序经常需要向内核请求服务,比如读一个文件、创建一个新的进程(fork)、加载一个新的程序(execve),或者终止当前进程(exit)。为了允许对这些内核服务的受控得到访问,处理器提供了一条特殊的syscall n的指令,当用户程序想要请求服务 n 时,可以执行这条指令,执行后会导致一个到异常处理程序的陷阱,这个处理程序解析参数,并调用适当的内核程序。
从程序员的角度来看,系统调用和普通的函数调用是一样的。然而,它们实现非常不同。
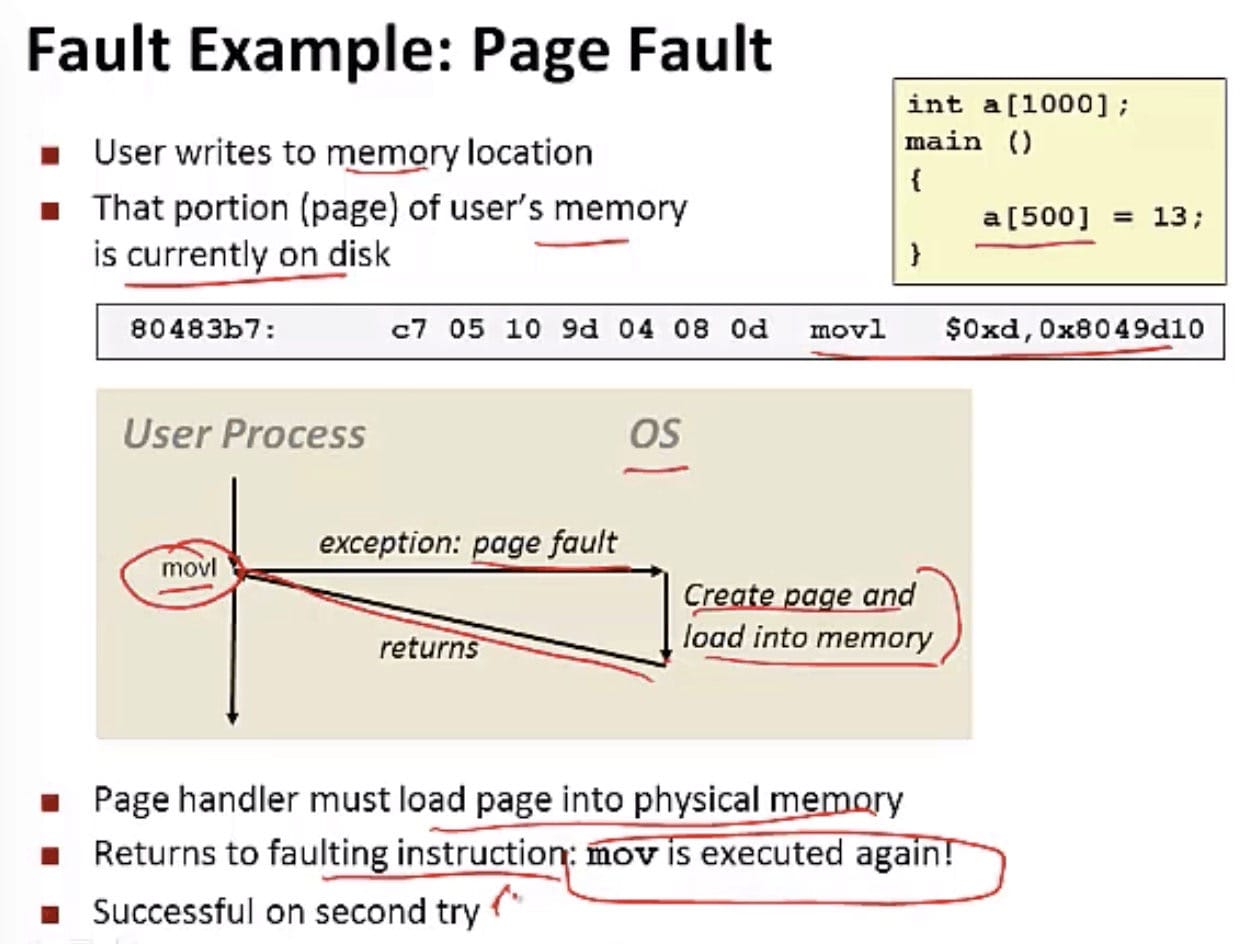
故障
故障是由错误情况引起,它可能能够被故障处理程序修正,如缺页异常。
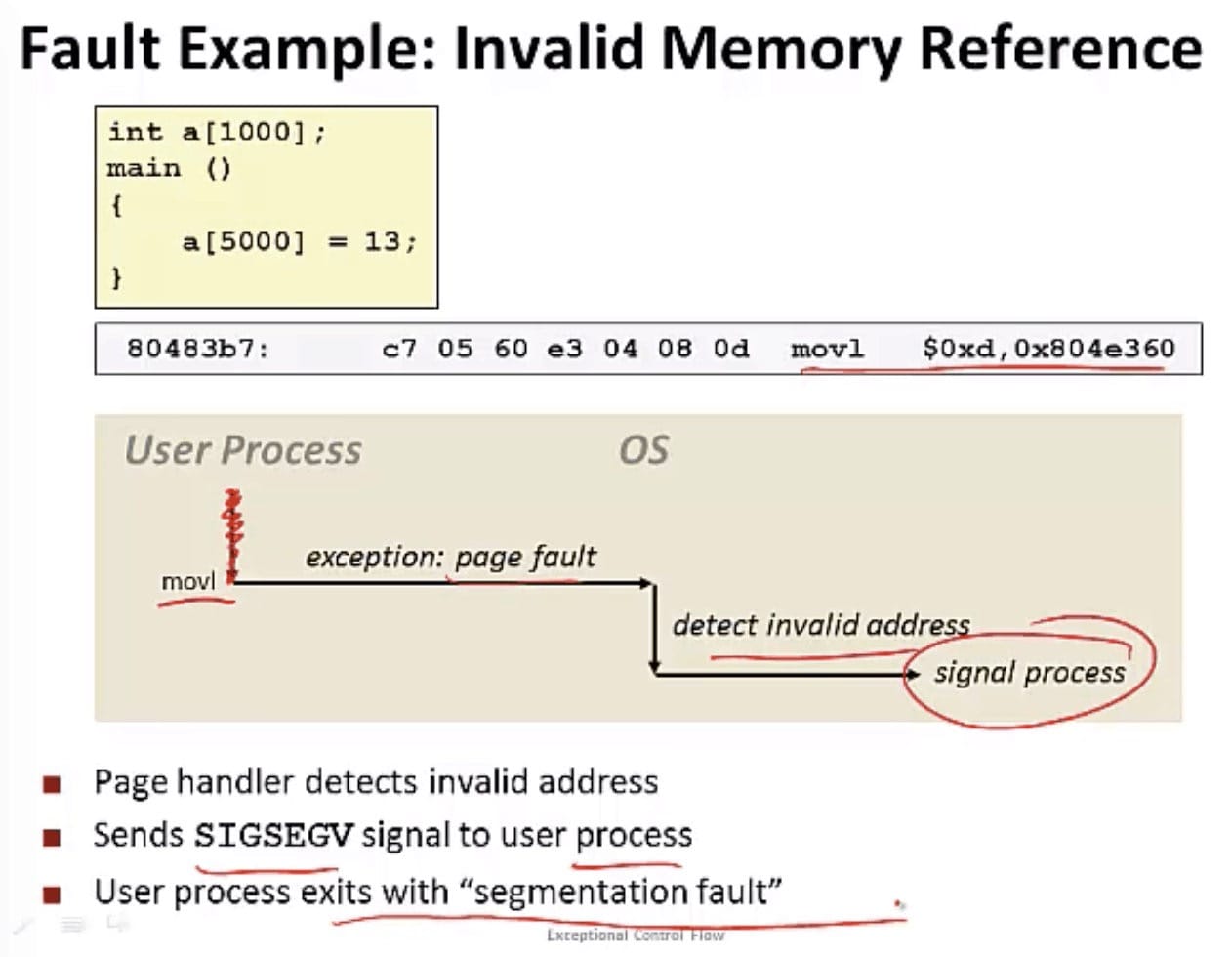
终止
终止是不可恢复的致命错误造成的结果。通常是一些硬件错误,比如 DRAM 或者 SRAM 位被损坏时发生的奇偶错误。处理程序将控制返回给一个 abort 例程,该例程会终止这个应用程序。
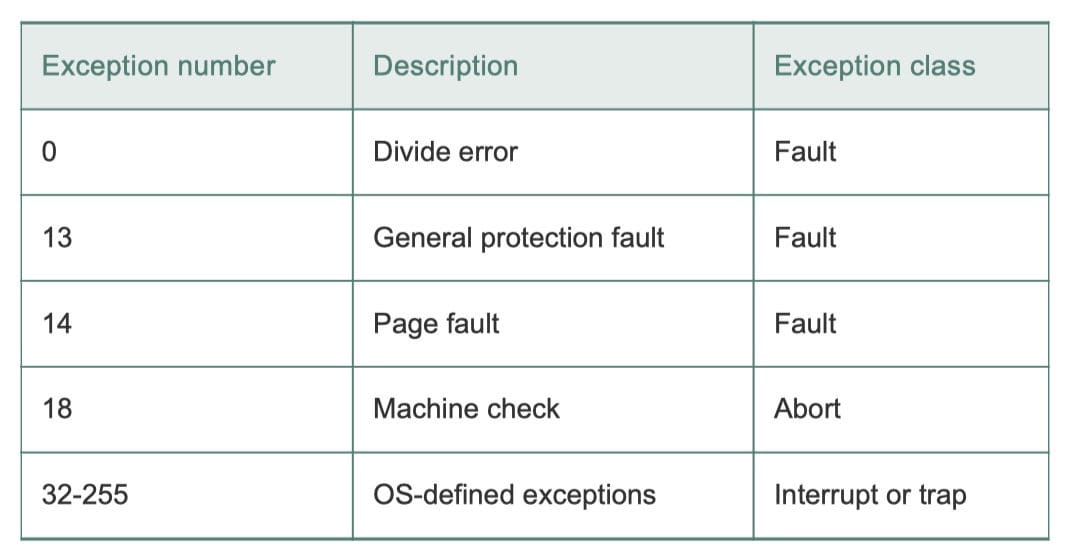
Linux/x86-64 系统中的异常
0~31的号码对应的是由 Intel 架构师定义的异常,因此对任何 x86-64 系统都是一样的。32~255的号码对应的是操作系统定义的中断和陷阱。
一般保护故障:许多原因都会导致不为人知的一般保护故障(general protection fault),通常是因为一个程序引用了一个未定义的虚拟内存区域,或者是因为程序试图写一个只读的文本段。Linux 不会尝试恢复这类故障。Linux shell 通常会把这个一般保护故障报告为段故障(segmentation fault)。机器检查:是在导致故障的指令执行中检测到致命的硬件错误时发生的。机器检查处理程序不返回控制给应用程序。
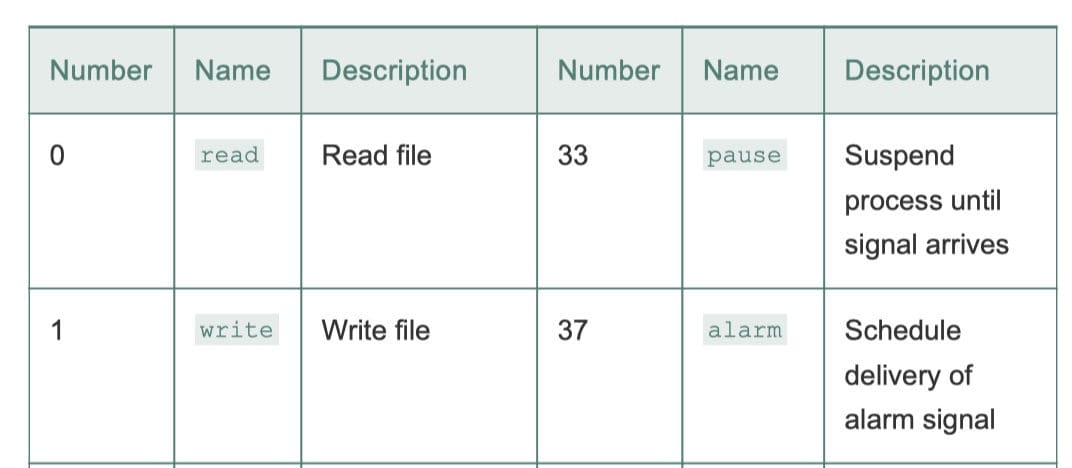
Linux/x86-64 系统调用
Linux 提供几百种系统调用,当应用程序想要请求内核服务时可以使用,包括读文件、写文件或是创建一个新进程。每个系统调用都有一w唯一的整数号,对应于一个到内核中跳转表的偏移量。(不是异常表)
C 程序用syscall函数可以直接调用任何系统调用。然而,实际j几乎没必要这么做。对于大多数系统调用,标准 C 库提供了一组方便的包装函数。这些包装函数将参数打包在一起,以适当的系统调用指令陷入内核,然后将系统调用的返回状态传递回调用程序。在本书中,系统调用与这些包装函数统称为系统级函数。
1 | int main() { |
write 函数的第一个参数发送到 stdout,第二个参数是要写的字节序列,第三个要写的是字节数。其汇编版本如下:
1 | main: |
注意:处理器 ISA 规范通常会区分异步中断和同步异常,但是并没有提供描述这些非常相似的概念的概括性术语。本书使用异常作为通用的术语,而且只有在必要时才区分异步异常(中断)和同步异常(陷阱、故障和终止)。
进程
异常是允许操作系统内核提供进程(process)概念的基本构造块,进程是计算机科学中最深刻、最成功的概念之一。在现代系统上运行一个程序时,我们会得到一个假象,就好像我们的程序时系统中当前运行的唯一的程序一样。我们的程序好像是独占地使用处理器和内存。进程给应用程序提供的关键抽象:
- 一个独立的
逻辑控制流(logical control flow):独占地使用处理器。 - 一个
私有的地址空间(private virtual address space):独占地使用内存系统,由虚拟内存机制管理。
Why are these illusions important?
- Simplify programming a lot
进程的经典定义是一个执行中的程序的实例(instance of a running program)。系统中的每个程序都运行在某个进程的上下文(context)中。上下文是由程序正确运行所需的状态组成的。这个状态包括存放在内存中的代码和数据,它的栈、通用目的寄存器的内容、程序计数器、环境变量以及打开文件描述符的集合。
每次用户通过向 shell 输入一个可执行目标文件的名字时,运行程序时,shell 就会创建一个新的进程,然后在这个新进程的上下文中运行这个可执行目标文件。当然,应用程序本身也可以创建新的进程。
What do processes have to do with exceptional control flow?
- Exceptional control flow is the mechanism that the OS uses to enable multiple processes to run on the same system.
逻辑控制流
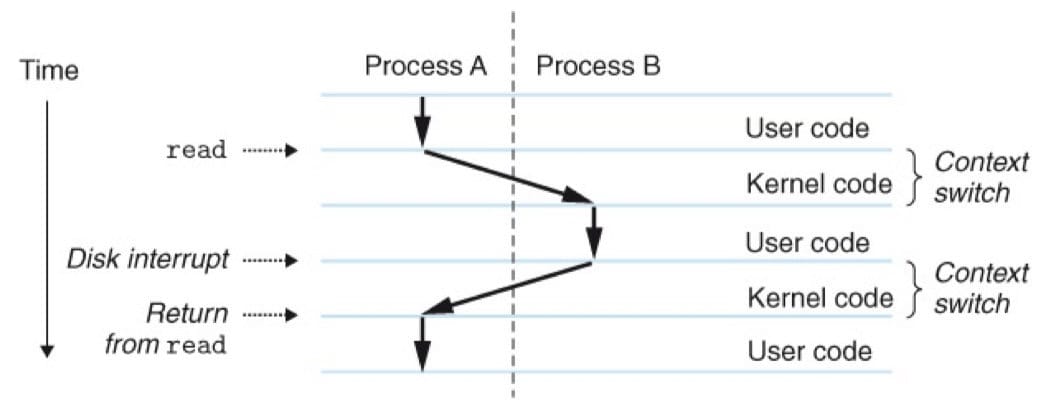
如果想用调试器单步执行程序,我们会看到一系列的程序计数器(PC)的值。这个值的序列叫做逻辑控制流(logical control flow),或者简称逻辑流。考虑一个运行着三个进程的系统,处理器的一个物理控制流被分成了三个逻辑流,每个进程一个。三个逻辑流的执行是交错的,每个进程执行它的流的一部分,然后被抢占(preempted,暂时挂起)。
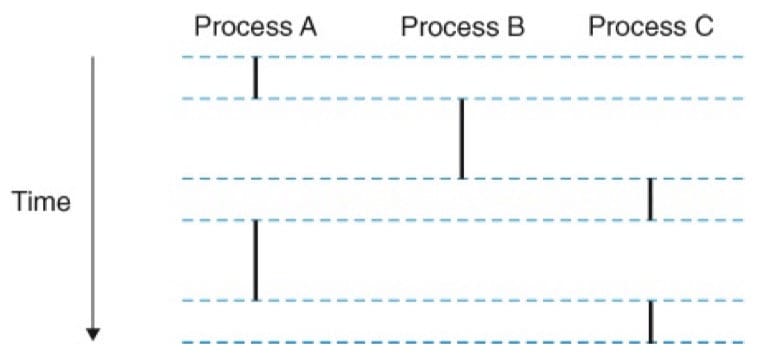
并发流
计算机系统中逻辑流有许多不同的形式。异常处理程序、进程、信号处理程序、线程和 Java 进程都是逻辑流的例子。一个逻辑流的执行在时间上与另一个流重叠,称为并发流(concurrent flow),这两个流被称为并发地运行。
多个流并发地执行的一般现象被称为并发(concurrency)。一个进程和其他进程轮流运行的概念称为多任务(multitasking)。一个进程执行它的控制流的一部分的每一时间段叫做时间片(time slice)。因此,多任务也被叫做时间分片(time slicing)。
注意,并发流的思想与流运行的处理器核数或计算机数无关。并行流是并发流的一个真子集。如果两个流并发地运行在不同的处理器核或者计算机上,那么我们称它们为并行流(parallel flow),它们并行地运行(running in parallel),且并行地执行(parallel execution)。
用户模式和内核模式
为了使操作系统内核提供一个无懈可击的进程抽象,处理器必须提供一种机制,限制一个应用可以执行的指令以及它可以访问的地址空间范围。处理器通常是用某个控制寄存器中的一个模式位(mode bit)来提供这种功能的,该寄存器描述了进程当前享有的特权。当设置了模式位,进程就运行在内核模式中。没有设置模式位时,进程就运行在用户模式中。用户程序必须通过系统调用接口间接地访问内核代码和数据(访问受限)。因此,进程从用户模式变为内核模式的唯一方法是通过诸如中断、故障或者陷入系统调用这样的异常。
Linux 提供了一种聪明的机制,叫做/proc文件系统,它允许用户模式进程访问内核数据结构的内容,比如 CPU 类型(/proc/cpuinfo),或者某个特殊的进程使用的内存段(/proc/<process-id>/maps)。2.6 版本的 Linux 内核还引入了/sys文件系统,它输出关于系统总线和设备的额外的低层信息。
上下文切换
Important: the kernel is not a separate process, but rather runs as part of a user process (but with special privileges).
操作系统内核使用一种称为上下文切换(context switch)的较高层形式的异常控制流来实现多任务。内核为每个进程维持一个上下文(context),就是一个内核重新启动一个被抢占的进程所需的状态。
在进程执行的某些时刻,内核可以决定抢占当前进程,并重新开始一个先前被抢占了的进程。这种决策就叫做调度(scheduling),是由内核中称为调度器(scheduler)的代码处理的。当内核调度了一个新的进程运行后,它就抢占当前进程,并使用一种上下文切换的机制将控制转移到新的进程,上下文切换:
保存当前进程的上下文(即状态)恢复某个先前被抢占的进程被保存的上下文- 将控制
传递给这个新恢复的进程
系统调用错误处理
当 Unix 系统级函数遇到错误时,它们通常会返回-1,并设置全局整数变量errno来表示什么出错了。程序员应该总是检查错误。
进程控制(fork-exec model)
fork() and execve() are system calls
Note: process creation in Windows is slightly different from Linux’s fork-exec model
other calls for process management:
getpid(), exit(), wait() / waitpid()
Unix 提供了大量从 C 程序中操作进程的系统调用。
新创建的子进程几乎但不完全与父进程相同。子进程得到与父进程用户级虚拟地址空间相同的(但是独立的)一份副本,包括代码和数据段、堆、共享库以及用户栈。子进程还获得与父进程任何打开文件描述符相同的副本,这就意味着当父进程调用 fork 时,子进程可以读写父进程中打开的任何文件。父进程和新创建的子进程之间最大的区别在于它们有不同的 PID。
- 调用一次,返回两次
- 并发执行
- 相同但是独立的地址空间
- 共享文件
- 父进程和子进程都把它们的输出显示在屏幕上。原因是子进程继承了父进程所有的打开文件。当父进程调用 fork 时,stdout 文件是打开的,并指向屏幕。自己成也继承了这个文件,因此它的输出也是指向屏幕的。
fork 函数是有趣的(也常常令人迷惑),因为它只被调用一次,却会返回两次(called once, but returns twice):一次是在调用进程(父进程)中,一次是在新创建的子进程中。在父进程中,fork 返回子进程的 PID。在子进程中,fork 返回 0。
1 | int main() { |
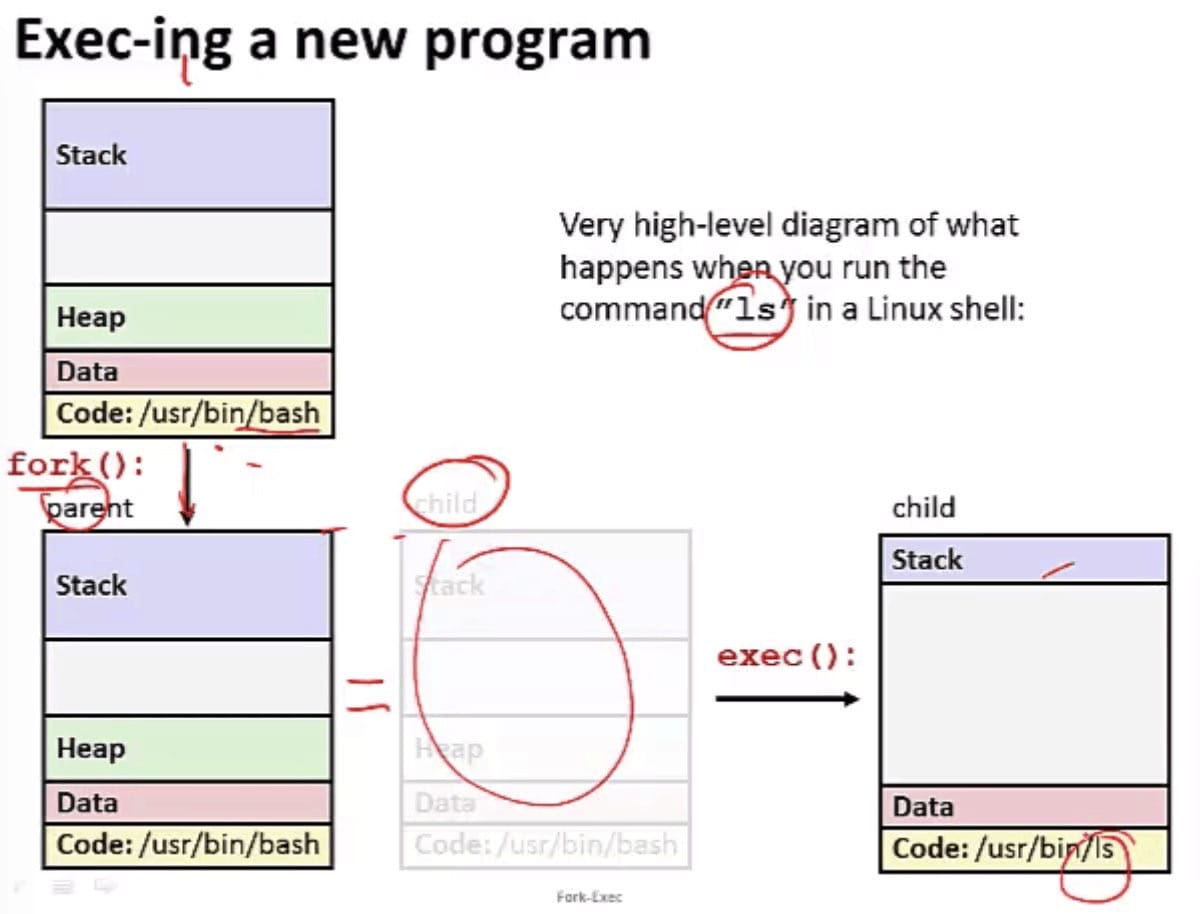
What happens when you run the command “ls” in a Linux shell?

但是在 exit 函数运行之后,进程占用的资源并没有被完全释放,需要进一步的进程回收。
回收子进程
Zombies:
- Reaping(回收)
- Performed by parent on terminated child
- Parent is given exit status information
- Kernel discards process
一个终止了但还未被回收的进程被称为僵死进程(zombie)。如果一个父进程终止了,内核会安排init进程称为它的孤儿进程的养父。init 进程的 PID 为 1,是在系统启动时由内核创建的,它不会终止,是所有进程的祖先。如果父进程没有回收它的僵死子进程就终止了,那么内核会安排 init 进程去回收它们。不过,长时间运行的程序,比如 shell 或者服务器,总是应该回收它们的僵死子进程。
注意,程序不会按照特定的顺序回收子进程。子进程回收的顺序是特定计算机系统的属性。
或者,使用wait与子进程同步。
If parent process has multiple children, wait() will return when any of the children terminates. waitpid() can be used to wait on a specific child process.
1 | $ ps -ef # 列出所有进程 |
确认什么是程序(代码和数据)与进程(实例、上下文环境):
程序:是一堆代码和数据;程序时可以作为目标文件存在于磁盘上,或者作为段存在于地址空间中。进程:是执行中程序的一个具体的实例;程序总是运行在某个进程的上下文中。如果你想要理解 fork 和 execve 函数,理解这个差异是很重要的。- fork 函数在新的子进程中
运行相同的程序(数据独立),新的子进程是父进程的一个复制品。 - execve 函数在当前进程的上下文加载并运行一个新的程序。它会
覆盖当前进程的地址空间,并继承已打开的所有文件描述符,但并没有创建一个新的进程。
- fork 函数在新的子进程中
像 Unix shell 和 Web 服务器这样的程序大量地使用了 fork 和 execve 函数。shell 是一个交互型的应用级程序,它代表用户运行其他程序。最早的 shell 是sh程序,后面出现了一些变种,如 csh、tcsh、ksh 和 bash。shell 执行一些列的读/求值(read/evaluate)步骤,然后终止。读步骤读取来自用户的一个命令行,求值步骤解析命令行,并代表用户运行程序。
信号
内容有点多,了解一下概念就好了。参考 p526
Linux 信号,是一种更高层的软件形式的异常,它允许进程和内核中断其它进程。一个信号就是一条小消息,它通知进程系统中发生了一个某种类型的事件。每种信号类型都对应于某种系统事件。低层的硬件异常是由内核异常处理程序处理的,正常情况下,对用户进程而言是不可见的。信号提供了一种机制,通知用户进程发生了这些异常。比如,如果一个进程试图除以 0,那么内核发送给它一个 SIGFPE 信号(号码为 8)。
信号处理的语义是微妙的,并且随系统不同而不同。然而,在与 POXIS 兼容的系统上存在着一些机制,允许程序清楚地指定期望的信号处理语义。
传送一个信号到目的进程是由两个不同步骤组成的:
发送信号:内核通过更新目的进程的上下文中的某个状态,发送(传递)一个信号给目的进程。发送信号可以有如下两种原因:- 内核检测到一个系统事件,比如除零错误或者子进程终止。
- 一个进程调用了
kill函数,显式地要求内核发送一个信号给目的进程。一个进程可以发送信号给它自己。
接收信号:当目的进程被内核强迫以某种方式对信号的发送做出反应时,它就接收了信号。进程可以忽略这个信号,终止或者通过执行一个称为信号处理程序(signal handler)的用户层函数捕获这个信号。一个发出而没有被接收的信号叫做待处理信号(pending signal)。
发送信号
Unix 系统提供了大量向进程发送信号的机制。所有这些机制都是基于进程组(process group)这个概念的。
每个进程都只属于一个进程组,进程组是由一个正整数进程组 ID来标识的。默认地,一z子进程和它的父进程同属于一个进程组。
用/bin/kill程序可以向另外的进程发送任意的信号。比如,命令:
1 | /bin/kill -9 15213 # 发送信号 9(SIGKILL)给进程组 15213 中的每个进程 |
一个为负的 PID 会导致信号被发送到进程组 PID 中的每个进程。比如,命令:
1 | /bin/kill -9 -15213 # 给进程组 15213 中的每个进程发送 SIGKILL 信号 |
非本地跳转
C 语言提供了一种用户级异常控制流形式,称为非本地跳转(nonlocal jump),它将控制直接从一个函数转移到另一个当前正在执行的函数,而不需要经过正常的调用-返回栈规则。非本地跳转是通过setjump和longjump函数来提供的。