首先我们要知道这两种模式都是 CPU 的工作模式,实模式是早期 CPU 运行的工作模式,而保护模式则是现代 CPU 运行的工作模式。
实模式(Real Mode)
起源
实模式出现于早期 8086 CPU 时期,8086 也是第一款支持内存分段模型的处理器。当时,8086 只有一种工作模式,即实模式,但当时还没有这个说法。由于 CPU 的性能有限,一共只有 20 位地址线(地址空间只有 1M),以及 8 个 16 位的通用寄存器,以及 4 个 16 位的段寄存器。16 位的物理地址只能访问 64KB 的内存。所以,为了能够通过这些 16 位的寄存器去构成 20 位的主存地址,访问 1 MB 的内存,必须采取一种特殊的方式。
原理
第一个字段是由段寄存器提供的,是一个 16 位的段基址。第二字段是段内偏移量,它的值是由通用寄存器(如 EIP)来提供,所以也是 16 位。那么问题来了,两个 16 位的值如何组合成一个 20 位的地址呢?这里采用的方式是:把段寄存器所提供的段基址先向左移 4 位(或乘以 16),这样就变成了一个 20 位的值,然后再与 16 位的段偏移量相加。如下所示:
$$物理地址 = 段基址 << 4 + 段内偏移$$
所以,假设段基址的值是 0xFF00,段内偏移的值是 0x0110。则物理地址可表示为:
$$0xFF00 << 4 + 0x0110 = 0xFF000 + 0x0110 = 0xFF110$$
应用
在现代计算机上,实模式存在的时间非常短,所以一般我们是感觉不到它的存在。CPU 复位(reset)或加电(power on)的时候就是以实模式启动,在这个时候处理器以实模式工作,不能实现权限分级,也不能访问 20 位以上的地址线,也就只能访问 1M 内存。之后,加载操作系统模块,进入保护模式。
此外,在这种模式下,系统在计算实际地址的时候是按照对 1M 求模的方式进行的,这种技术被称为 wrap-around。也就是说,当程序员给出超过 1M(100000H ~ 10FFEFH)的地址时,为了保持逻辑上正常,系统并不认为其访问越界而产生异常,而是自动从 0 开始计算。
然而,在实模式中整个物理内存被看成分段的区域,程序代码和数据位于不同区域,系统程序和用户程序没有区别对待,而且每一个指针都是指向「实在」的物理地址。这样一来,用户程序的一个指针如果指向了系统程序区域或其他用户程序区域,并改变了值,容易造成软件甚至系统崩溃。
保护模式(Protected Mode)
起源
最开始的程序寻址是直接的 段基址 : 段内偏移 模式,这样的好处是所见即所得,程序员指定的地址就是物理地址,物理地址对程序员是可见的。但这就带来一些问题:
- 无法支持多任务
- 程序的安全性无法得到保证
随着 CPU 的发展,CPU 的地址线的个数也从原来的 20 根变为现在的 32 根,所以可以访问的内存空间也从 1 MB 变为现在 4 GB,寄存器的位数也变为 32 位。因此,实模式下的内存地址计算方式就已经不再适用了,需要引入新的模式,即保护模式,实现更大空间的、更灵活的内存访问。
在保护模式下,全部 32 条地址线有效,可寻址高达 4 GB 的物理地址空间。扩充的存储器 段式管理机制 和可选的 页式管理机制,不仅为存储器共享和保护提供了硬件支持,而且为实现 虚拟存储器 提供了硬件支持,支持多任务,能够快速地进行任务切换和保护任务环境。四个特权级和完善的特权检查机制,既能实现资源共享又能保证代码和数据的安全及任务的隔离。
总的来说,保护模式出现的原因名副其实:保护进程地址空间。
原理
在保护模式下,地址的表示方式与实模式是一样的,都是 段基址 : 段内偏移。不过,保护模式下 段 的概念发生了根本性的改变。实模式下的段值可以看作是地址的一部分,可直接参与转换计算。而保护模式下的段值(尽管仍然由原来的段寄存器表示)变成了一个索引(准确来说是 16 位的段选择子/段标识符 Selector,前 13 位为索引信息,后 3 位是硬件信息),指向了一个数据结构的一个表项(段表项),表项中详细定义了 段基址、界限、属性(权限)等内容。这个数据结构是 全局描述符(GDT,Global Descriptor Table),也有可能是 本地描述符(LDT,Local Descriptor Table)。它们存放关于某个运行在内存中的程序的分段信息的,比如某个程序的代码段是从哪里开始,有多大;数据段又是从哪里开始,有多大。
GDT 的作用是用来提供段式存储机制,这种机制是段寄存器和 GDT 中的描述符(段表项)共同支持的。每个描述符在 GDT 中占 8 字节,也就是 2 个双字(一个字等于两个字节,双字等于四个字节),或者说是 64 位。描述符的构成如下图所示:
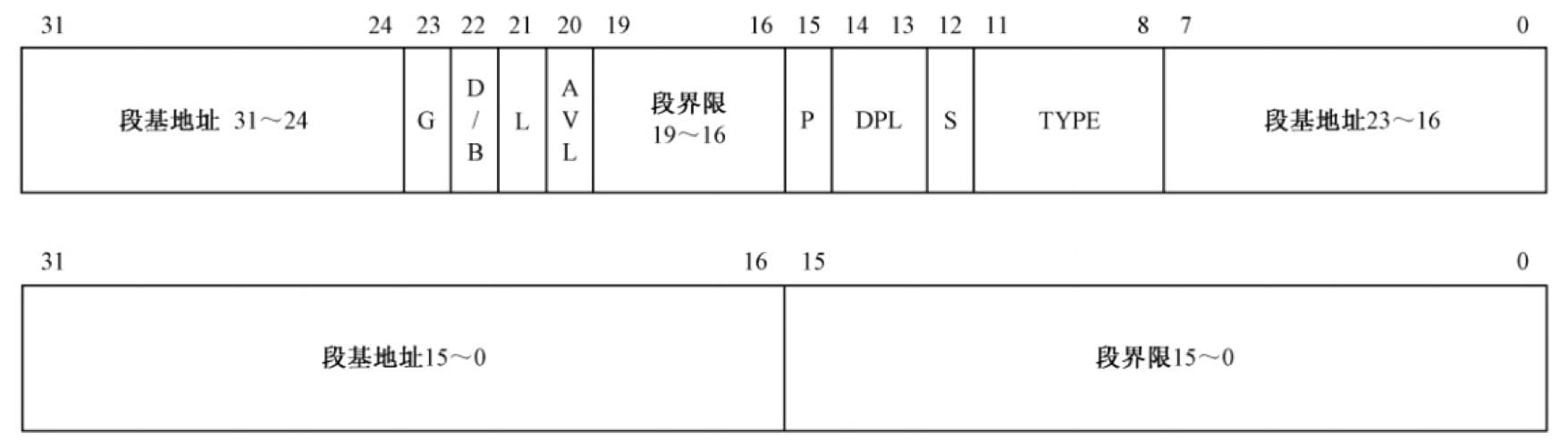
其中:
- G 位是
粒度位(Granularity),用于解释段界限的含义; - D/B 位是
默认的操作数大小(Default Operation Size),主要是为了能够在 32 位处理器上兼容运行 16 位保护模式的程序; - L 位,是
64 位代码段标志,保留此位给 64 位处理器使用; - AVL 位,是
可以使用的位(Available),通常由操作系统来用,处理器并不使用它; - P 位是
段存在位(Segment Present),表示对应的段是否存在; - DPL 表示描述符的
特权级(Descriptor Privilege Level),0 ~ 3,0 表示最高特权级别,这里再次点明了为何叫保护模式; - S 位是
描述符的类型位(Descriptor Type),0 为系统段,1 为代码段或数据段; - TYPE 字段共 4 位,用于指示描述符的类型(X 执行、W 读写、R 读出、A 已访问)。
很明显,描述符中指定了 32 位的 段基址,以及 20 位的 段界限。在实模式下,段基址并非是真实的物理地址,在计算物理地址时,还要左移 4 位(乘以 16)。和实模式不同,在 32 位保护模式下,段基址是 32 位的,若加上段内偏移即为 线性地址。如果未开启分页功能,该线性地址就是 物理地址。
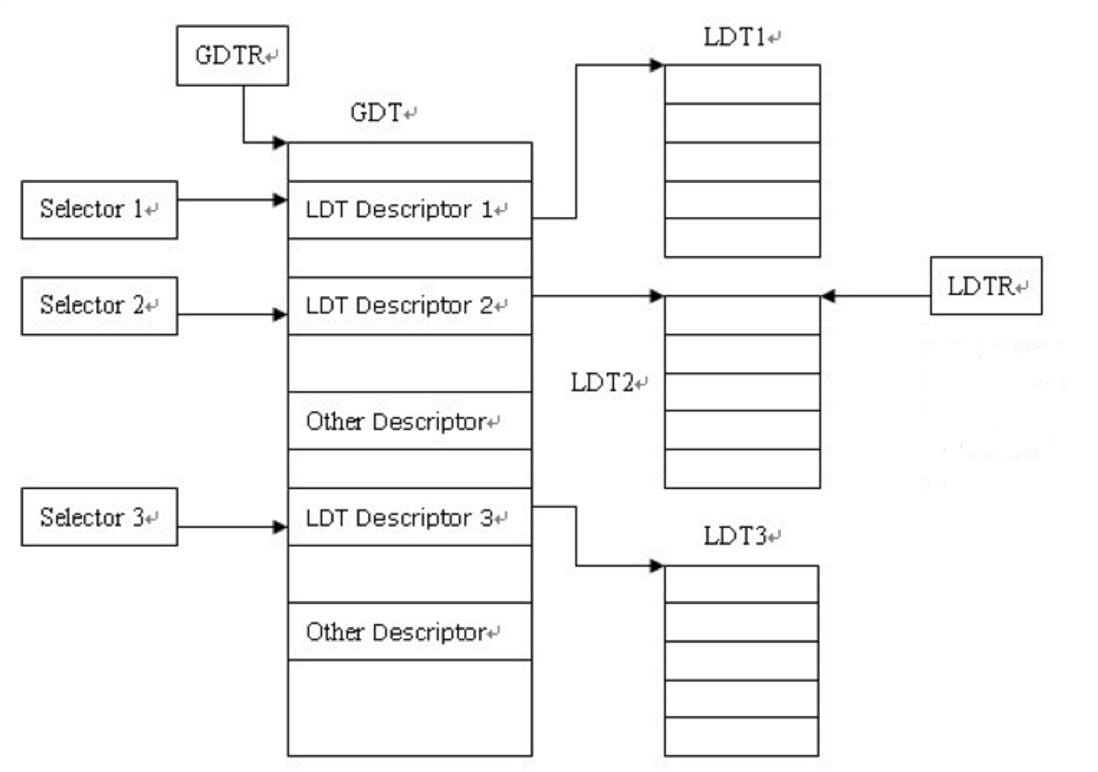
GDT 和 LDT 的区别在于:
- 全局可见(global)和局部可见(local);
- LDT 表存放在 LDT 类型的段之中,此时 GDT 必须含有 LDT 的段描述符;
- LDT 本身是一个段,而 GDT 不是。
访问流程:
- 查找 GDT 在线性地址中的段基址(表本身的位置),需要借助 GDTR 寄存器;
- 通过该段基址和
逻辑地址中的段标识符(selector),可以找到 LDT 段描述符; - 通过 GDT 中的这个 LDT 段描述符可以找到 LDT 相应的基地址;
- 访问 LDT 需要使用 LDT 基地址和 LDT 段选择符(或叫段标识符),为了减少访问 LDT 时的段转换次数,LDT 段基址、LDT 段选择符、LDT 段限长都存放在 LDTR 寄存器中。
注意:这里和 关于操作系统内存管理的总结 中关于段式内存管理的描述有点出入。这里多了 LDT,因此从 GDT 中获得的是 LDT 段描述符,而不再是段基址。
对于操作系统来说,每个系统必须定义一个 GDT,用于系统中的所有任务和程序。系统可选择性定义若干个 LDT。GDT 本身不是一个段,而是线性地址空间的一个数据结构;而 LDT 本身是一个段。
想知道更多可以参考第三篇文章,整理得很好。