Reference: LeetCode
Difficulty: Medium
My Post: [Java] Summary of Usages of “split()”
Problem
Design an algorithm to encode
a list of stringstoa string. The encoded string is then sent over the network and is decoded back to the original list of strings.
Note:
- The string may contain any possible characters out of
256 valid ascii characters. Your algorithm should be generalized enough to work on any possible characters. - Do not use class member/global/static variables to store states. Your encode and decode algorithms should be stateless.
- Do not rely on any library method such as
evalorserializemethods. You should implement your own encode/decode algorithm.
Analysis
Reference: Java - String split() Method, zero and negative limit
In Java, The limit parameter controls the number of times the pattern is applied and therefore affects the length of the resulting array. We have 3 possible values for this limit:
- If the limit is
n > 0then the pattern will be applied at mostn - 1times, which means the number of pieces will be no greater thann, and the array’s last entry will contain all input beyond the last matched delimiter (""will be kept). For example,"..".split(".", 2)->["", "."]. - If the limit is
n < 0then the pattern will be applied as many times as possible and the array can have any length. Besides, it will keep empty strings. For example,"..".split(".", -1)->["", "", ""]. - If the limit is
n == 0(default) then the pattern will be applied as many times as possible and the array can have any length. Besides, it will delete empty strings. For example,"..".split(".", 0)->[].
1 | // In default, limit = 0 |
Methods:
Reference: Solution Post
Non-ASCII Delimiter
- Since the string may contain every possible 256 valid ASCII characters, we should choose an appropriate delimiter. For example, we can use non-ASCII unichar character like
ā(Character.toString((char) 257)). - It’s convenient to use two different non-ASCII characters, to distinguish between situations of
empty arrayand ofarray of empty strings. So we use one more unichar characterCharacter.toString((char) 258).Time: $O(N)$1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25// Encodes a list of strings to a single string.
public String encode(List<String> strs) {
if (strs == null || strs.size() == 0) { // strs list is null or empty
return Character.toString((char) 258);
}
String del = Character.toString((char) 257);
StringBuilder sb = new StringBuilder();
for (String s : strs) {
sb.append(s + del);
}
sb.setLength(sb.length() - 1);
return sb.toString();
}
// Decodes a single string to a list of strings.
public List<String> decode(String s) {
String d = Character.toString((char) 258);
if (s.equals(d)) {
return new ArrayList<>();
}
String del = Character.toString((char) 257);
String[] dataArray = s.split(del, -1);
List<String> strings = new ArrayList<>(Arrays.asList(dataArray));
return strings;
}
Space: $O(1)$ for encode; $O(N)$ for decode.
- Since the string may contain every possible 256 valid ASCII characters, we should choose an appropriate delimiter. For example, we can use non-ASCII unichar character like
Chunked Transfer Encoding
- This approach is based on the
encoding used in HTTP v1.1. It doesn’t depend on the set of input characters, and hence is more versatile and effective. - Data stream is divided into chunks. Each chunk is preceded by its
size in bytes. - Encode:
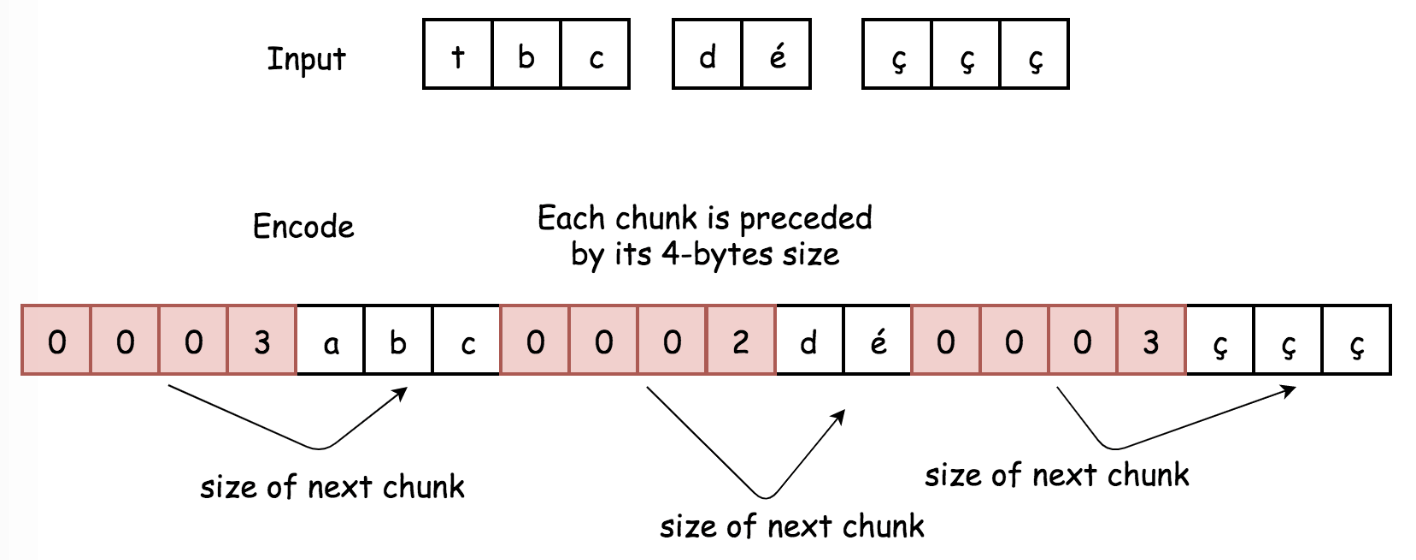
- For each chunk compute its length, and convert that length into 4-byte string.
- Append to encoded string:
- 4-byte string with information about chunk size in bytes.
- Chunk itself.
- Return encoded string.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17public String encode(List<String> strs) {
StringBuilder sb = new StringBuilder();
for (String s : strs) {
sb.append(intToString(s));
sb.append(s);
}
return sb.toString();
}
public String intToString(String s) {
int x = s.length();
char[] byteChars = new char[4]; // 4 bytes - 32 bits
for (int i = 3; i >= 0; --i) {
byteChars[3 - i] = (char) ((x >>> (i * 8)) & 0xff); // mask the low 8 bits
}
return new String(byteChars);
}
- Decode:
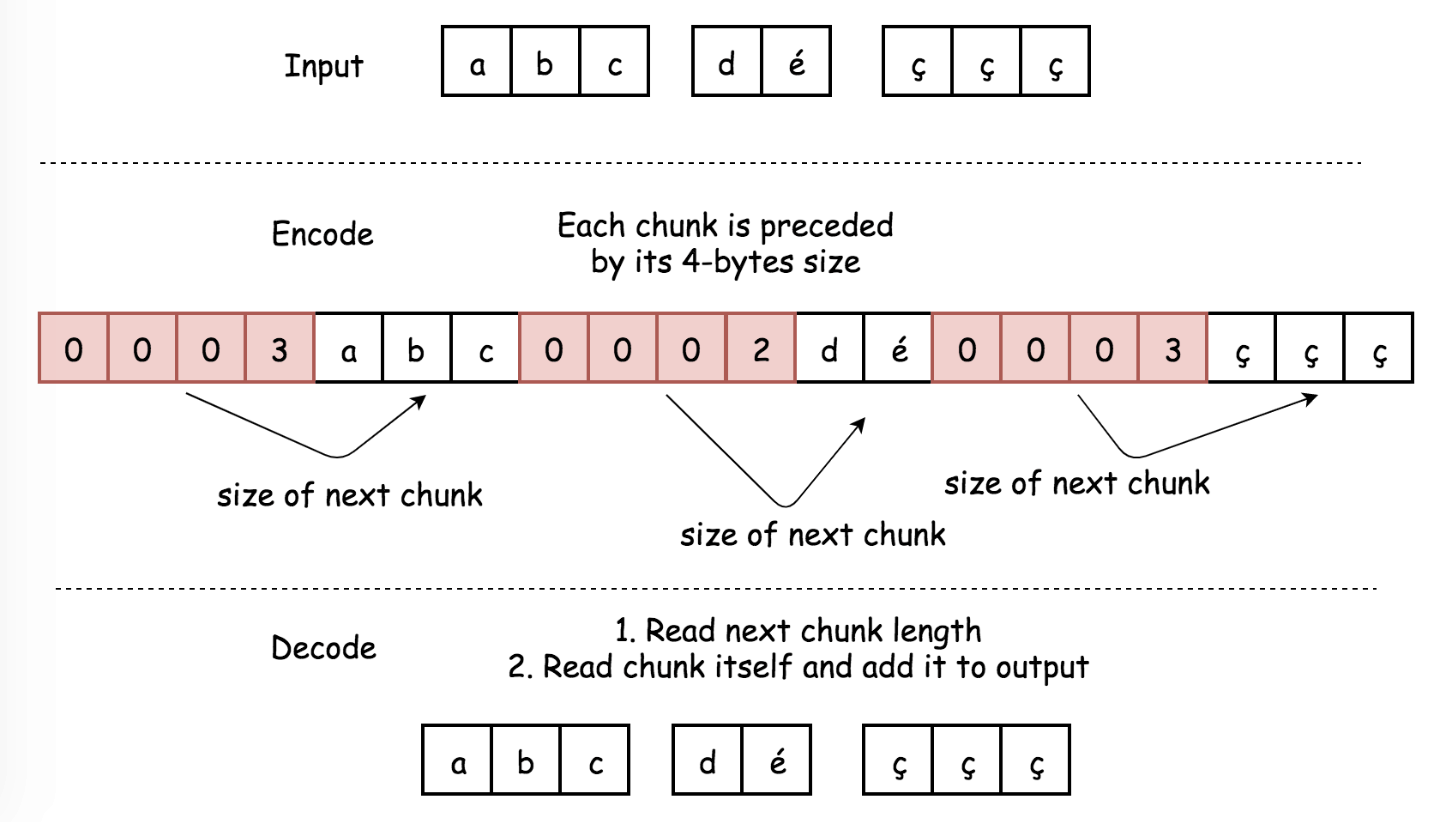
- Iterate over the encoded string with a pointer
i:- Read 4 bytes
s[i: i + 4]. This chunk should be converted into integerlength. - Move the pointer by 4 bytes
i += 4. - Append to the decoded array string
s[i: i + length]. - Move the pointer by
lengthbytesi += length.
- Read 4 bytes
- Return decoded array of strings.Time: $O(N)$
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19public List<String> decode(String s) {
int i = 0, n = s.length();
List<String> output = new ArrayList<>();
while (i < n) {
int length = stringToInt(s.substring(i, i + 4));
i += 4;
output.add(s.substring(i, i + length));
i += length;
}
return output;
}
public int stringToInt(String s) {
int result = 0;
for (char b : s.toCharArray()) { // 4 chars in total
result = (result << 8) + (int) b;
}
return result;
}
Space: $O(1)$ for encode to keep the output; $O(N)$ for decode to keep the output.
- Iterate over the encoded string with a pointer
- This approach is based on the