由于太久没碰 Java,而且以前也没有进行系统的学习,最近想通过一些网课先过一遍基础语法和常用 API。我先看了 Udemy 的 Java Programming Masterclass for Software Developers,但看到一半就弃坑了,因为这个课是给零基础的人设计的,讲得太啰嗦了,而且教的内容也太浅了(不过我倒是学了很多 IntelliJ IDEA 的使用技巧)。
之后无意中看到了廖雪峰的 Java SE 课程,个人感觉非常棒,很适合有其他 OOP 基础的人学习(16 小时、讲解深度适中、干货多)。本文笔记基于这个课程。在学习的过程中,我还阅读很多关于泛型、内存模型等知识的博客文章,毕竟课程的讲解深度有限,这些内容还是挺难理解的(我的两本 Java 经典书籍刚到货,估计之后可以学到更多高级和底层的内容)。
基础
快速介绍 Java 的历史,讲解 Java 基本语法、数据类型,掌握如何使用 Eclipse IDE 并快速编写简单的 Java 程序。
简介
Sun 公司James Gosling为手持设备开发的嵌入式编程语言。Java 原名为 Oak,1995 年改名为 Java 正式推出。
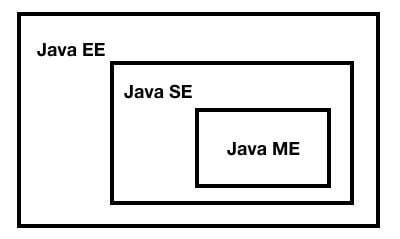
三个版本:
- Java SE:Standard Edition
- Java EE:Enterprise Edition
- Java ME:Micro Edition
Java 版本演进:
| 时间 | 版本 | 时间 | 版本 |
|---|---|---|---|
| 1995 年 | 1.0 | 2004 年 | 1.5 / 5.0 |
| 1998 年 | 1.2 | 2006 年 | 1.6 / 6.0 |
| 2000 年 | 1.3 | 2011 年 | 1.7 / 7.0 |
| 2002 年 | 1.4 | 2014 年 | 1.8 / 8.0 |
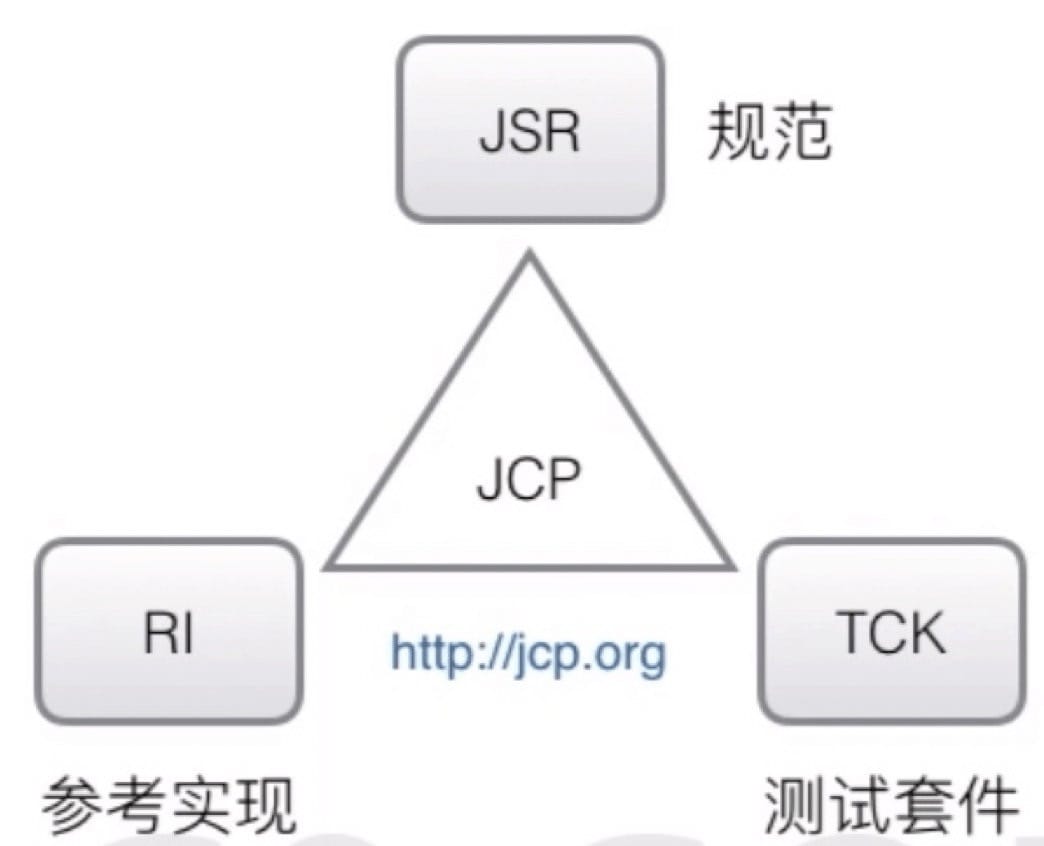
Java 规范
- JSR 规范:Java Specification Request
- JCP 组织:Java Community Process
- 确保 Java 跨平台特性
Java 平台

JDK:Java Development Kit
JRE:Java Runtime Environment
基本类型
Java 的两种变量类型:基本类型、引用类型。
int x = n / 0; 运行时才会报错。
Java 中,计算结果溢出不报错。
1 | long n = 999; |
四舍五入技巧:
1 | int n = (int) (12.7 + 0.5); // 加 0.5 再强制转换 |
&& 和 || 被称为短路运算符:
false && (5 / 0)不会报错,因为后面不会被执行。即前面部分 false (&&) 或者 true (||),后面就不执行了。
三元运算符b ? x : y中 x 和 y 的类型一定要相同。
Java 使用 Unicode 表示字符
1 | char c1 = 'A'; // char c1 = '\u0041'; |
如果将 char 变量赋值给 int 变量,可以得到该字符的 Unicode 表示。
引用类型
字符串
字符串类型是引用类型。
字符串不可变!
1 | String s = "hello"; |
数组
数组是同一数据类型的集合,类型是:类型名[]。元素初始化为默认值,数组创建后大小不可改变。
1 | int[] ns1 = new int[]{ 1, 2, 3 }; |
多维数组
1 | int[][] b = { {1, 2, 3}, {1, 2}, {1} }; // 因为 java 存数组的本质是 multi-level arrays,相当于 C 语言里的 int *b[] |
格式化输出
1 | System.out.printf("haha"); // 原来也可以用这个。 |
条件判断
对浮点数进行==运算不靠谱。
1 | double x = 1 - 9.0 / 10; |
引用类型对象的判断方法:
==判断是否为同一对象(判断 id,即地址)equals()方法判断对象的内容是否相等,如果对象是 null 会报错(NullPointerException)。
有两种好的方法:
1 | // 非 null 的对象放前面 |
BTW:Java 里不推荐省略花括号{}(代码风格)。
循环
for each 遍历数组
1 | for (int n : ns) { |
还可以遍历可迭代数据类型,包括 List、Map 等。但是,for each 循环无法指定遍历顺序;也无法获取数组索引。
使用Arrays.toString()可以快速打印数组内容:
1 | int[] a = {1, 2, 3, 4}; |
Arrays.sort() 来进行排序。
命令行参数
1 | public static void main(String[] args) { |
面向对象编程
介绍 Java 面向对象编程的概念,掌握数据封装、继承和多态,掌握 Java 的包、作用域及常用核心类。
一些概念
直接把 field 用 public 暴露给外部可能破坏了封装,应该定义 public 方法可以间接访问 field(更加安全)。
参数绑定:基本类型、引用类型。
字符串(String)作为参数传递,是值传递,表现出非对象的特性!(虽然它是引用类型)因为是包装类?
原因:
是因为 new 的问题吗?不对。实际上,字符串直接赋值和用 new 出的对象赋值的区别仅仅在于存储方式不同。
也许你注意到了 String 类里的 char[],这说明对 String 的存储实际上通过 char[] 来实现的。怎么样?其实就是一层窗户纸。不知道大家还记不记得在 Java API 中定义的那些基本类型的
包装类。比如 Integer 是 int 包装类、Float 是 float 的包装类等等。对这些包装类的值操作实际上都是通过对其对应的基本类型操作而实现的。是不是有所感悟了?对,String 就相当于是 char[] 的包装类。包装类的特质之一就是在对其值进行操作时会体现出其对应的基本类型的性质。在参数传递时,包装类就是如此体现的。所以,对于String在这种情况下的展现结果的解释就自然而然得出了。
同样的,Integer、Float 等这些包装类和 String 在这种情况下的表现是相同的,具体的分析在这里就省略了,有兴趣的朋友可以自己做做试验。
这也就是为什么当对字符串的操作在通过不同方法来实现的时候,推荐大家使用 StringBuffer 的真正原因了。至于 StringBuffer 为什么不会表现出 String 这种现象,大家再看看的 StringBuffer 的实现就会明白了,在此也不再赘述了。
构造方法
如果自定义了构造方法,编译器就不再自动创建默认构造方法,此时只有自定义的构造方法。
类中初始化的顺序:
- 先初始化
字段- 没有赋值的字段初始化为默认值:
- 基本类型 = 0
- 引用类型 = null
- 没有赋值的字段初始化为默认值:
- 再执行构造方法的代码
设计思想:将代码逻辑集中在参数最复杂的构造方法中,从而实现代码复用。(利用重载实现)
重载
目的:相同功能的方法使用同一个名字;方便调用;代码复用。
- 多个方法的方法名相同
- 但各自的参数不同(个数、类型、位置【但不应该去交换顺序】)
- 方法返回值类型通常都是相同的
- 注意:这不是强制的,但这是应该遵守的规范!
继承
继承,是代码复用的一种方式。
规定:
- 构造方法的第一行语句必须是 super();如果没有,编译器会
自动生成super()。- (父类有默认的构造方法)
- 如果父类没有默认的构造方法,子类必须显式调用 super(…) 方法。
- 比如父类自己写了带参数的构造方法,Java 编译器就不会自动为它添加默认的构造方法,因此子类也不会被自动添加默认的构造方法。
1 | public class Person { |
可以对实例变量进行向上转型(Upcasting),把一个子类型安全地变为更加抽象的类型。
可以对实例变量进行向下转型(Downcasting),把抽象的类型变成一个具体的子类型。向下转型很可能报错:ClassCastException。
1 | Person p = new Person(); |
多态
注意搞清楚这几个词的关系:覆盖、覆写、重写(Override)。
加上@Overrite可以让编译器帮助检查是否进行了正确的覆写,但不是必需的。
Java 的实例方法调用是基于运行时实际类型的动态调用(多态)。覆盖的时候可以调用父类的方法,用 super()。
final 关键字:
- 用 final 修饰的方法,不能被覆盖。
- 用 final 修饰的类,不能被继承。
- 用 final 修饰的字段在初始化后不能被修改。
抽象类
抽象方法定义了子类必须实现的接口规范,定义了抽象方法的类就是抽象类。从抽象继承的子类必须实现抽象方法;如果不实现抽象方法,则该子类仍是一个抽象类。
1 | public class Person { |
我们可以通过子类去继承并实现这些抽象方法,从而实现多态。
所以,面向抽象编程的本质:
- 上层代码只
定义规范(abstract class pattern)。 - 不需要子类就可以实现
业务逻辑(可以正常编译)。 - 具体的业务逻辑由不同的
子类实现,调用者并不关心。
接口
如果一个抽象类没有字段,所有方法全部是抽象方法,就可以把该抽象类改写为接口(Interface)。因为 Java 编译器默认 Interface 是public、abstract,所以我们不用再写这两个修饰符。
注意区分一下接口:
- Java 的接口特指 interface 定义的接口,只定义方法签名。
编程接口泛指接口规范,如方法签名,数据格式,网络协议等。
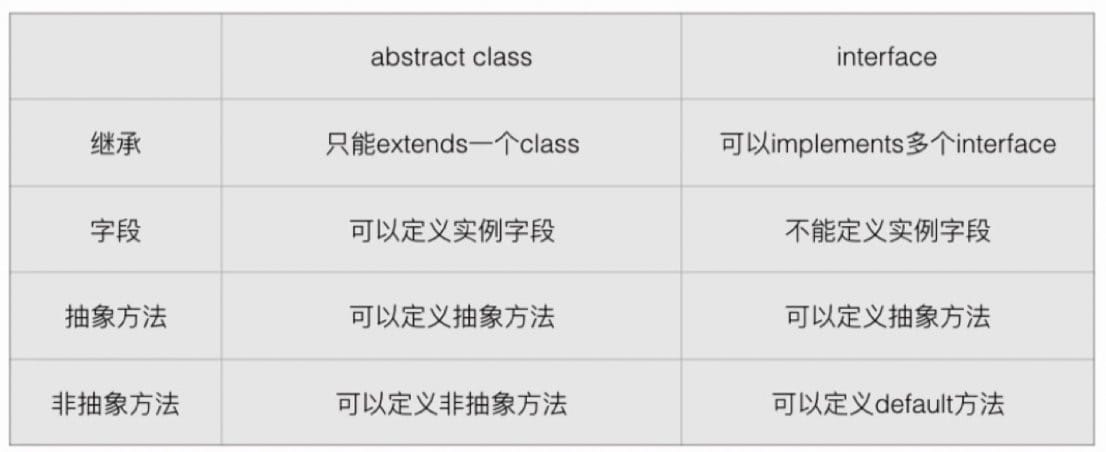
default 方法在>jdk 1.8引入。
1 | public interface Shape { |
interface 也可以继承另一个 interface:
1 | public interface Student extends Person { |

静态字段和方法
可以将静态字段理解为描述 class 本身的字段。不推荐用实例变量访问静态字段,而推荐用类名访问静态字段。
静态方法类似其他编程语言的函数。静态方法不能访问 this 变量,不能访问实例字段,可以访问静态字段。
- 静态方法经常用于
工具类- Arrays.sort()
- Math.random()
- 静态方法经常用于
辅助方法 - Java 程序的入口 main() 也是
静态方法
包
这是 Java 定义的一种名字空间,包名 + 类名 = 完整类名。
1 | package xiaoming; |
包可以是多层结构,但包没有父子关系。java.util 和 java.util.zip 是不同的包,两者没有任何关系。
JVM 加载 class 并执行时,总是使用 class 的完整类名(编译后也是)。如:java.util.Arrays、Hello(没有定义 package,不推荐)。
包作用域:位于同一个包的类,可以访问包作用域的字段和方法。这是缺省修饰符,即不用 public、protected、private 修饰的字段和方法就是包作用域。
引用其他类的方法:
- 使用完整类名
- 先 import,再使用类名
- import xiaoming;
- 使用:xiaoming.Person
- 可以使用
*(不推荐,有点类型 C++ 的 using namespace)import java.util.*;
作用域
Java 的类、接口、字段和方法都可以设置访问权限。
- 访问权限是指一个类的内部,能否引用另一个类以及访问它的字段和方法。
- 访问权限有 public、protected、private、package(缺省)四种。
注意:private 方法,推荐写在类定义的后面。
- 定义为 private 的 class 无法被其他类访问。
- 访问 private class 被限定在外层 class 的内部。
- 定义在一个 class 内部的 class 被称为
内部类(inner class)。 - 在一个 Java 文件中只能定义
一个 public 类,但可以定义多个非 public 的类。
1 | package com.test.sample |
最佳实践:
- 如果不确定是否需要 public,就不声明为 public,尽可能少地暴露对外的方法。
- 尽可能把局部变量的作用域缩小。
- 尽可能延后声明局部变量。
classpath 和 jar
classpath
- classpath 是一个环境变量
- classpath 指示 JVM 如何搜索 class
- classpath 设置的搜索路径与操作系统有关:
- win:
C:\work\project1\bin;C:\shared;"D:\My Document\project2\bin" - mac:
/usr/shared:/usr/local/bin:/home/chuck/bin
- win:
win 用分号;mac 用冒号。
假设 classpath 是:.;C:\work\project1\bin;C:\shared,JVM 在加载 com.chuck.Hello 这个类时,依次查找:
- <当前目录> \com\chuck\Hello.class
- C:\work\project1\bin\com\chuck\Hello.class
- C:\shared\com\chuck\Hello.class
注意:在某个路径找到了,就不再继续搜索了。如果没找到就报错。
classpath 的设置方法:
- 直接在系统环境中设置 classpath 环境变量(不推荐)
- 在启动 JVM 时设置 classpath 变量(推荐):
- java -classpath C:\work\bin;C:\shared com.chuck.hello
- java -cp 同上
- 没有设置环境变量,也没有设置 -cp 参数,默认的 classpath 为当前目录。
- 在 Eclipse 中运行 Java 程序,Eclipse 自动传入的 -cp 参数是当前工程的 bin 目录和引入的 jar。
jar 包
- jar 包是 zip 格式的压缩文件,包含若干 .class 文件(可以直接改 zip 文件的扩展名)
- jar 包相当于目录
- classpath 可以包含 jar 文件:C:\work\bin\all.jar
- 查找 com.chuck.Hello 类将在 C:\work\bin\all.jar 文件中搜索 com/chuck/Hello.class
- 使用 jar 包可以避免大量的目录和 .class 文件(起打包作用)
如何创建 jar 包:
- 使用 JDK 自带的 jar 命令
- 使用构建工具如 Maven 等
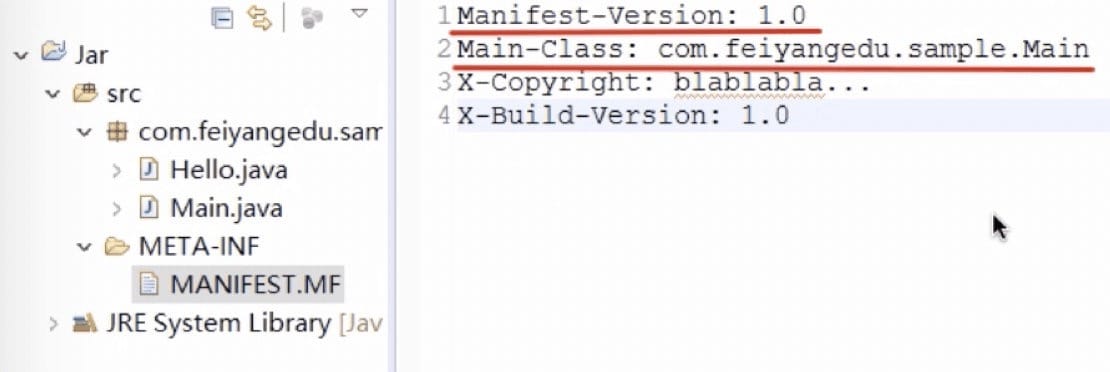
jar 包的其它功能:
- jar 包可以包含一个特殊的 /META-INF/MANIFEST.MF 文件。
- MANIFEST.MF 是纯文本,可以指定 Main-Class 和其它信息。
- jar 包还可以包含其它 jar 包。
JDK 的 class:
JVM 运行时会自动加载 JDK 自带的 class,都被打包在rt.jar文件中,但我们不需要在 classpath 中引用rt.jar。
字符串类
这个类可以直接使用"anyString",且内容是不可变的。
API:
eqauls(Object)
equalsIgnoreCase(String)
boolean contains(CharSequence)
int indexOf(String)
int lastIndexOf(String)
boolean startsWith(String)
boolean endsWith(String)
trim() 移除
首尾空白字符,包括空格、\t、\r、\n。返回的是新的字符串。substring(startInd, endInd)
toUpperCase()、toLowerCase()
replace(char, char)
replace(CharSequence, CharSequence)
replaceAll(String, String) 正则表达式
String[] split(String)
1
2
3String s = "A,,B;C ,D";
String[] ss = s.split("[\\,\\;\\s]+"); // 可以传入正则表达式
// {"A", "B", "C", "D"}static String join()
1
2
3String[] arr = {"A", "B", "C"};
String s = String.join("~~", arr);
// "A~~B~~C"static String String.valueOf(int) // boolean, Object
static int Integer.parseInt(String)
static Integer Integer.valueOf(String)
注意:Integer I2 = Integer.getInteger("123"); I2 不是 123,而是环境变量名为 123 的值。
char[] toCharArray(),String 转为 char[]
new String(char[]),构造方法
1
2
3String s = "hello";
char[] cs = s.toCharArray(); // s 会复制一份新的 char[]
String s2 = new String(cs); // cs 也会被复制一份新的
String 转换为 byte[]:
byte[] getBytes() // 不推荐,使用操作系统默认的编码(Win 下默认是 GBK)
byte[] getBytes(String)
byte[] getBytes(Charset)
1
2
3
4
5
6String s = "hello";
byte[] bs1 = s.getBytes("UTF-8");
byte[] bs2 = s.getBytes(StandardCharsets.UTF_8);
new String(bs1, "UTF-8");
new String(bs2, StandardCharsets.UTF_8);
字符串构建类
String 可以用+拼接:
1 | String s = ""; |
- 每次循环都会创建新的字符串对象
- 绝大部分都是临时对象,浪费内存
- 影响 GC(Garbage Collection)效率
StringBuilder 可以高效拼接字符串
1 | StringBuilder sb = new StringBuilder(1024); |
- StringBuilder 是可变对象
- StringBuilder 可以预分配缓冲区
StringBuilder 还可以进行链式操作:
1 | String sb = newStringBuilder(1024); |
注意:我们不需要特别改写字符串+操作,编译器在内部自动把多个连续的+操作优化为 StringBuilder 操作。
1 | String s = "Hello, " + name + "!"; |
StringBuilder vs. StringBuffer:
- StringBuilder 和 StringBuffer 接口完全相同
- StringBuffer 是 StringBuilder 的线程安全版本
- 没有必要使用 StringBuffer
实现链式操作的关键在于返回实例本身(函数式编程?)。
编码方式
中文编码:GB2132、GBK、GB18030(本质上是一样的,但后面的字符数更多一些)。一个中文字符占 2 个字节,第一个字节最高位是 1。这个标准是由中国定义的。
其它语言编码: Shift_JIS(日本)、Euc-kr(韩文)。
全球统一编码:Unicode。一个 Unicode 字符通常占用 2 个字节。Java 使用 Unicode 编码。
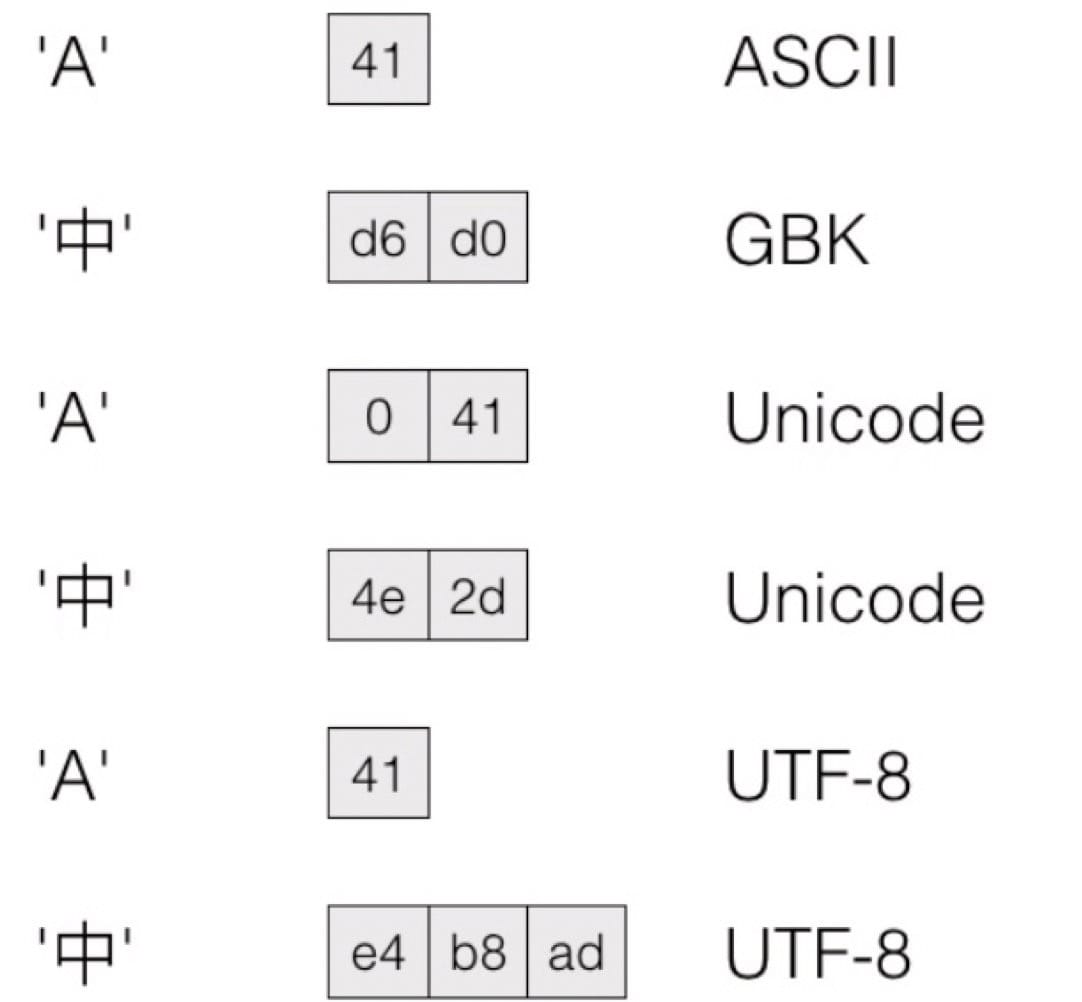
有了 Unicode 为什么还需要 UTF-8?
因为,英文 Unicode 编码和 ASCII 不一致,包含大量英文的文本会浪费空间。而且很多原来不能识别 Unicode 的软件会报错,不能兼容。而 UTF-8 是变长编码,英文 UTF-8 编码和 ASCII 一致。(还要容错能力强?)
始终优先考虑 UTF-8 编码!
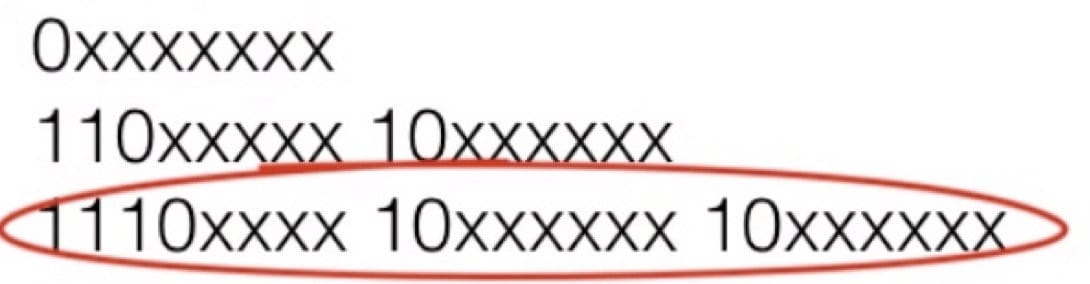
上图中,1110 开头说明占用 3 个字节。
1 | char c1 = 'A'; |
包装类型
JDK 为每种基本类型都创建了对应的包装类型:
| 基本类型 | 对应的引用类型 |
|---|---|
| boolean | Boolean |
| byte | Byte |
| short | Short |
| int | Integer |
| long | Long |
| float | Float |
| double | Double |
| char | Character |
在int、Integer 和 String 的相互转换中,特别注意 Integer.getInteger(String) 是从系统环境变量中读取系统变量。
1 | int i = 100; |
编译器的自动装箱:(JDK >= 1.5)
- 自动装箱和自动拆箱只发生在
编译阶段 - 装箱和拆箱会影响执行效率
- 编译后的 class 代码是严格区分基本类型和引用类型的
- Integer -> int 执行时可能会报错(null)
1 | Integer n = 99; // Integer.valueOf(99) |
包装类还定义了一些静态变量:
1 | Boolean t = Boolean.TRUE; |
JavaBean
维基百科:JavaBeans 是 Java 中一种特殊的类,可以将多个对象封装到一个对象(bean)中。其特点是可序列化,提供无参构造器,提供 getter 方法和 setter 方法访问对象的属性。名称中的 Bean 是 Java 的可重用软件组件的惯用叫法。
属性只是一种通用的叫法,它并不是 Java 的语法规定。
符合命名规范的 class 被称为 JavaBean:
privateType field- public Type getField() // boolean 字段的读方法是:isXXX()
- public void setField(Type value)
- 必须提供
空的构造方法 - 实现 Serializable 接口(可选)
通常把一组对应的 getter 和 setter 方法称为属性(Property)。
属性只需要定义 getter / setter 方法,不一定需要对应的字段,如 child 是只读属性。
1 | public class Person { |
作用:
- 方便 IDE 工具读写属性
- 传递数据
- 枚举属性
- 封装数据(?)
- 可重用的组件(?)
1 | // 体现封装、抽象、代码复用 |
枚举类
1 | public enum Weekday { |
用 enum 定义常量:
- 关键字 enum 定义常量类型
- 常量本身带有类型信息
- 使用 == 比较:
if (day == Weekday.FRI) {...}
实际上编译器编译出的 class 是:
1 | // 但注意的是,直接编写 class 无法通过编译 |
可以用于 foreach:
1 | for (Weekday day : Weekday.values()) { |
可以添加实例字段和方法,且构造方法需要声明为 private。
1 | public enum Weekday { |
常用工具类
Math 提供了数学计算的静态方法:
- abs / min / max
- pow / sqrt / exp / log / log10
- sin / cos / tan / asin/ acos …
常量:
- PI = 3.14159 …
- E = 2.71828 …
Math.random() 生成一个随机数(伪随机):
- 0 <= 随机数 < 1
- 可用于生成某个区间的随机数
1 | // 0 <= R < 1 |
Random 生成伪随机数:
- nextInt / nextLong / nextFloat …
- nextInt(N) 生成不大于 N 的随机数
1 | Random r = new Random(); |
SecureRandom() 可以用来创建安全的随机数,但是比较慢。
大整数:
BigInteger 用任意多个 int[] 来表示非常大的整数。BigDecimal 类似,两者都继承自 Number。
1 | BigInteger big = new BigInteger("21321321312312"); |
异常处理
介绍 Java 的异常体系,掌握如何正确捕获并处理异常,如何自定义异常,如何使用断言和日志。
错误处理
基本异常
Java 使用异常来表示错误:
- 异常是 class,本身带有类型信息
- 异常可以在任何地方抛出
- 异常只需要在上层捕获,和方法调用分离
1 | try { |
Java 的异常也是 class:
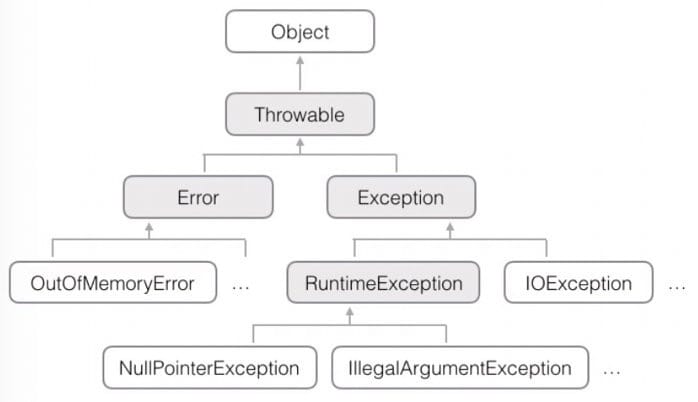
其中,必须捕获的异常:
- Exception 及其子类,但不包括 RuntimeException 及其子类
- 要捕获的异常称为
Checked Exception
Why?
Error是发生了严重错误,程序对此一般无能为力:OutOfMemoryError、NoClassDefFoundError、StackOverflowError 等等。Exception是发生了运行时逻辑错误,应该捕获异常并处理:IOException、NumberFormatException、NullPointerException、IndexOutOfBoundsException。
对可能抛出的Checked Exception的方法调用:
捕获 Exception 并处理(前面的例子)
不捕获但通过 throws 声明,但仍需在上层捕获
1
2
3
4
5
6
7
8
9
10
11
12// throws 在这里相当于延后捕获,但 main() 是最后捕获的机会了!
static byte[] toGBK(String s) throws UnsupportedEncodingException {
return s.getBytes("GBK");
}
public static void main(String[] args) {
try {
byte[] data = toGBK("test");
} catch (UnsupportedEncodingException e) {
System.out.println(e);
}
}
捕获异常(Catch)
catch 的顺序非常重要,子类必须写在前面;且 finally 语句块保证有无错误都会执行,但不是必须的。
Multi-Catch(JDK >= 1.7):如果某些异常的处理逻辑相同,可以写成catch (IOException | NumberFormatException e) {},但在好的设计中它们不能存在继承关系。
抛出异常(Throw)

如何抛出异常:
- 创建某个 Exception 实例
- 用 throw 抛出异常(注意 throw 没
s)
如何转换异常:

但是,写成 IllegalArgumentException(e)可以使新的 Exception 保持原始异常的信息。
但注意:在抛出异常前,finally 语句会保证执行。
1 | public static void main(String[] args) { |
如果保存所有的异常信息?
- 用 origin 变量保存原始异常
- 如果存在原始异常,用 addSuppressed() 添加新异常
- 如果存在原始异常,或者新异常,最后在 finally 抛出
1 | Exception origin = null; |
- 用 getSuppressed() 获取所有 Suppressed Exception(JDK >= 1.7)
1 | try { |
自定义异常
JDK 定义的常用异常:
- RuntimeException
- NullPointerException
- IndexOutOfBoundsException
- SecurityException
- IllegalArgumentException
- NumberFormatException
- IOException
- UnsupportedCharsetException、FileNotFoundException、SocketException 等
- ParseException、GeneralSecurityException、SQLException、TimeoutException 等
自定义异常:
- 从适合的 Exception 派生
- 从 RuntimeException 派生
1 | public class BadFileFormatException extends IOException { |
推荐从 RuntimeException 派生,这样不需要强制捕获自定义的异常。catch (RuntimeException) 能捕获到自己的异常。父类能捕获到子类,而不需要自己写 catch (XxxxxxException)。
通常,我们如下定义新的异常关系树:
- 从适合的 Exception 派生 BaseException
- 其他 Exception 从 BaseException 派生
自定义异常应该提供多个构造方法:
1 | public class BaseException extends RuntimeException { |
断言与日志
断言
断言(Assertion)是一种程序调试的方式。断言很少被使用,更好的方式是编写单元测试。
对可恢复的错误不能使用断言,而应该抛出异常。如不可恢复的错误:
1 | assert x >= 0 // 否则抛出 AssertionError |
可恢复的错误:
1 | if (x == null) { |
JVM 默认关闭断言指令,要用-ea参数打开。
- 可以指定特定的类启用断言
- -ea:com.chuck.helloworld.Main
- 可以指定特定的包启用断言
- -ea:com.chuck
日志
什么是日志(Logging):
- 日志是为了代替
System.out.println() - 可以设置输出样式
- 可以设置输出级别,禁止某些级别输出
- 可以被重定向到文件
- 可以被包名控制日志级别
JDK 内置了 Logging:Java.util.logging:
1 | import java.util.logging.Level; |
JDK Logging 的局限:
- JVM 启动时读取配置文件并完成初始化
- JVM 启动时无法修改配置
- 需要在 JVM 启东时传递参数:-Djava.util.logging.config.file=config-file-name
Common Logging 是 Apache 创建的日志模块:
- 可以挂接不同的日志系统
- 可以通过配置文件指定挂接的日志系统
- 自动搜索并使用 Log4j(一个由 Apache 开发的更强大的日志系统)
- 使用 JDK Logging(JDK >= 1.4)
1 | Log log = LogFactory.getLog(Main.class); |
定义了六个日志级别:FATAL、ERROR、WARNING、INFO、DEBUG、TRACE。
反射与泛型
介绍 Java 的反射、注解和泛型,掌握如何使用反射访问字段、方法、构造方法,如何使用注解,如何使用泛型,Java 泛型的实现原理,extends 和 super 通配符的用法。
反射
Class 类
class / interface 的数据类型是 Class。每加载一个 class,JVM 就为其创建一个 Class 类型的实例,并关联起来。
- 加载 String 类(读取 String.class 文件)
- 为 String 类创建一个 Class 实例
1
Class cls = new Class(String);
️以 String 为例:
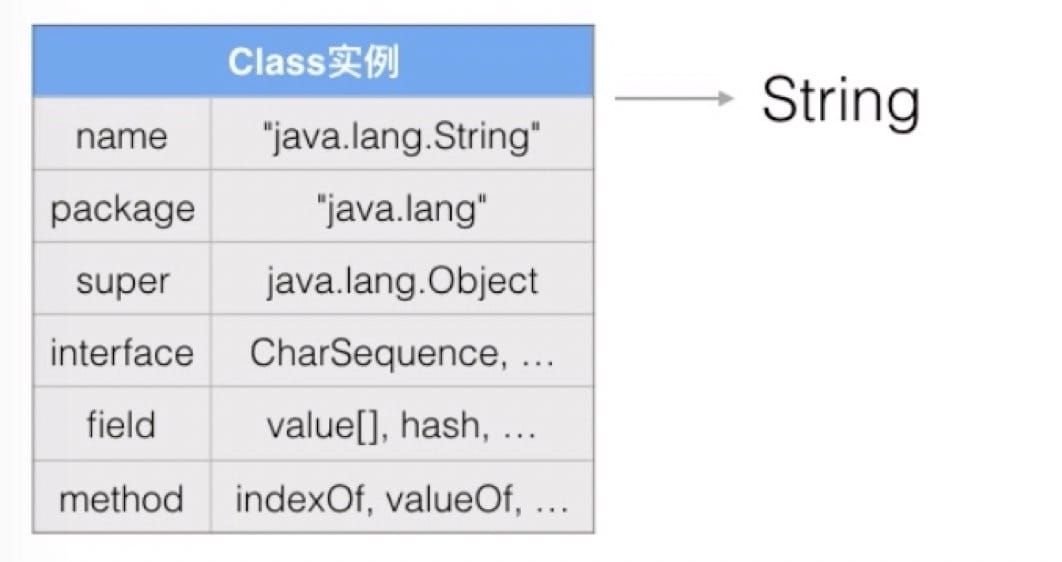
- JVM 为每个加载的 class 创建对应的 Class 实例,并在实例中保存该 class 的所有信息。
- 如果获取了某个 Class 实例,则可以获取到该实例对应的 class 的所有信息。
- 通过 Class 实例获取 class 信息的方法称为
反射(Reflection)。 - Class 实例在 JVM 中是
唯一的。
获取方法:
- Type.class
1
Class cls = String.class;
- getClass()
1
2String s = "Hello";
Class cls = s.getClass(); - Class.forName()
1
Class cls = Class.forName("String");
Class 实例比较和 instanceof 的差别:
1 | Integer n = new Integer(123); |
反射的目的是当获得某个 Object 实例时,我们可以获取该 Object 的 class 信息。
1 | Class cls = String.class; |
还可以从 Class 实例判断 class 类型:
- isInterface()
- isEnum()
- isArray()
- isPrimitive()
注意:int 虽然是基本类型,但 JVM 内部会给它创建 class 实例。
从 Class 实例中初始化新的实例:
1 | Class cls = String.class; // 需要强制转换 |
利用 JVM 动态加载 class 的特性,可以在运行期根据条件加载不同的实现类。即使类不存在,我们也可以在运行期动态地加载 class。
1 | boolean isClassPresent(String name) { |
访问字段
通过 Class 实例获取字段信息:
- getField(name):获取某个 public 的 field(包括父类)
- getDeclaredField(name):获取当前类的某个 field(不包括父类)
- getFields():获取所有 public 的 field(包括父类)
- getDeclaredFields():获取当前类的所有 field(不包括父类)
如果用 getField(name) 获取 private 字段,会得到 NoSuchFieldException。应该用 getDeclaredField(name) 获取当前类的 private 字段。
1 | Integer n = new Integer(123); |
访问静态字段:
1 | Field f = cls.getDeclaredField("number"); |
setAccessible(true)可能会失败:
- 定义了 SecurityManager
- SecurityManager 的规则阻止对该 Field 设置 accessible(规则应用于所有 java 和 javax 开头的 package 的类)
通常自己编写的类或者第三方的类是没有这样的限制的。
调用方法
通过 Class 实例获取方法信息:
- getMethod(name, Class…):获取某个 public 的 method(包括父类)
- getDeclaredMethod(name, Class…):获取当前类的某个 method(不包括父类)
- getMethods():获取所有 public 的 methods(包括父类)
- getDeclaredMethods():获取当前类的所有 methods(不包括父类)
注意:上面有的方法中有个 Class…,这是可变参数,或者可以传递数组。
1 | Integer n = new Integer(123); |
记得,还可以使用 JavaBean 获得方法信息。
以上 API 保证了多态的正确性:
1 | // Person p = new Student(); |
调用构造方法
Class.newInstance() 只能调用 public 无参数的构造方法。
注意:Integer 类不能这样用,因为它没有无参数的构造方法!!!
Constructor 对象包含一个构造方法的所有信息,通过它可以创建一个实例:
- getConstructor(typeClass):获取某个 public 的 Constructor
- getDeclaredConstructor(typeClass):获取某个 Constructor
- getConstructors():获取所有 public 的 Constructor
- getDeclaredConstructors():获取所有 Constructor
注意:Constructor 总是当前类定义的方法,不会获得父类的构造方法。
1 | Class cls = Integer.class; |
获取继承关系
获取父类的 Class:
- Class getSuperClass()
- Object 的父类是 null
- interface 的父类是 null(interface 的父类要用 getInterfaces())
获取当前类直接实现的 interface:
- Class[] getInterfaces()
- 没有 interface 的 class 返回空数组
- interface 返回继承的 interface
- 如果要获取父类的 interface,需要递归调用方法 getInterfaces()
判断向上转型是否成立:
- isAssignmentFrom(Class)
1 | if (People.class.isAssignableFrom(Student.class)) { |
注解
使用注解
对代码逻辑没有任何影响,但是如何使用注解是工具决定的。
- @Override:让编译器检查该方法是否正确地实现了覆写
- @Deprecated:告诉编译器该方法已经被标记为「作废」,在其他地方引用将会出现编译警告
- @SuppressWarnings
注解可以定义配置参数:
- 配置参数由注解类型定义
- 配置参数可以包括:
- 所有基本类型
- String
- 枚举类型
- 数组
- 配置参数必须是常量
1 | public class Hello { |
- 缺少某个配置参数将使用默认值
- 如果只写常量,相当于省略了 value 参数
- 如果只写注解,相当于全部使用默认值
1 | public class Hello { |
定义注解
使用 @interface 定义注解(Annotation):
- 注解的参数类似无参数方法
- 可以设定一个默认值(推荐)
- 把最常用的参数命名为 value(推荐)
1 | public Report { |
使用 @Target 定义 Annotation 可以被应用于源码的哪些位置:
- 类或接口:ElementType.TYPE
- 字段:ElementType.FIELD
- 方法:ElementType.METHOD
- 构造方法:ElementType.CONSTRUCTOR
- 方法参数:ElementType.PARAMETER
1 |
|
如果要用到多个地方:
1 |
|
生命周期:
使用 @Retention 定义 Annotation 的生命周期:
仅编译器:RetentionPolicy.SOURCE- 编译器在编译时直接丢弃,如 @Override
仅 class 文件:RetentionPolicy.CLASS- 仅存储在 class 文件中
运行期:RetentionPolicy.RUNTIME- 在运行期可以读取 Annotation
如果 @Retention 不存在,则该 Annotation 默认为 CLASS。通常自定义的 Annotation 都是 RUNTIME。
1 |
|
使用 @Inherited 定义子类是否可以继承父类定义的 Annotation:
- 仅针对 @Target 为 TYPE 类型(即类、接口)的 Annotation
- 仅针对 class 的继承
- 对 interfade 的继承无效
1 |
|
总结定义 Annotation 的步骤:
- 用 @interface 定义注解
- 用
元注解(meta annotation)配置注解@Target:必须设置@Retention:一般设置为 RUNTIME,默认是 CLASS- 通常不必写 @Inherited、@Repeatable 等等
- 定义注解参数和默认值
1 | // NotNull |
处理注解
如何使用注解完全由工具决定的,这里只针对 RUNTIME 类型的注解。
如何读取 RUNTIME 类型的注解?
- Annotation 也是 class
- 所有 Annotation 继承自 java.lang.annotation.Annotation
- 使用反射 API
判断 Annotation 是否存在:
- Class.isAnnotationPresent(Class)
- Field.isAnnotationPresent(Class)
- Method.isAnnotationPresent(Class)
- Constructor.isAnnotationPresent(Class)
1 | Class cls = Person.class; |
获取 Annotation:
- Class.getAnnotation(Class)
- Field.getAnnotation(Class)
- Method.getAnnotation(Class)
- Constructor.getAnnotation(Class)
1 | Class cls = Person.class; |
继续之前的例子:
1 | static void checkPerson(Person p) throws Exception { |
此外:
- 对 JavaBean 的属性值可以按规则进行检查
- JUnit 会自动运行 @Test 注解的测试方法
泛型
概念
如果没有泛型,需要强制转型来引用里面的对象,如:
1 | // ArrayList 里面没有用到泛型,一律用 Object |
必须把 ArrayList 变成一种模板 ArrayList
1 | public class ArrayList<T> { |
注意泛型的继承关系:
不能把ArrayList<Integer>向上转型为ArrayList<Number>或List<Number>,因为ArrayList<Number>和ArrayList<Integer>两者没有继承关系。
使用泛型
在不使用泛型的时候,Java 总是会自动为泛型类型提供一个相应的原始类型。所谓原始类型就是指泛型的第一个限定类型(从左向右,比如下面的 Comparable),无限定类型泛型的原始类型默认为 Object。
1 | List list = new ArrayList(); |
1 | public class Rectangle<T> {} |
调整extends Serializable & Comparable顺序后,K 的原始类型为 Serializable ,V 的原始类型为 Object。
注意:extends后可以继承多个类、多个接口,原始类型为从左向右排序的第一个类或者接口。为了提高效率,应该将标签接口(即没有方法的接口)放在边界限定列表的末尾。清楚了原始类型之后,我们接下来讲解类型擦除。
可以省略部分声明,编译器能自动推断出的类型:
1 | List<Number> list = new ArrayList<Number>(); |
编写泛型
- 编写泛型类比普通类复杂
- 泛型类一般用在集合类,如:ArrayList
- 很少需要编写泛型类
泛型类型<T>不能用于静态方法:
- 编译错误:编译器无法在静态字段或静态方法中使用泛型类型
。
1 | public static Pair<T> create(T first, T last) { |
但是,在 static 后面加了个<T>就不会报错:
1 | public static <T> Pair<T> create(T first, T last) { |
实际上,这个和上面定义的<T>没什么关系,是方法的泛型类型(这里是泛型静态方法),一般应该改写为其它字母,如 K。
泛型方法
擦拭法(Type Erasure)
擦拭法是 Java 泛型的实现方式。在泛型代码编译的时候,编译器其实把所有类型的泛型类型 T 视为 Object 类型。换句话说,虚拟机其实对泛型一无所知,所有的工作都是编译器做的。最终加了强制转换。
擦拭法的局限:
不能是基本类型(和 C++ 的不同,但是可以用包装类解决这个问题) - Object 字段无法持有基本类型
- 无法取得带泛型的 Class(因为在编译后就不存在范型类型了)
- 无法判断带泛型的 Class
1 | People p1 = new People<String>(); |
不能实例化 T 类型,因为擦拭后实际上是 new Object()。
1 | public class Pair<T> { |
而应该借助 Class
1 | // Constructor |
再有,要注意擦拭法带来的方法重名问题:
1 | public class Pair<T> { |

在调用泛型方法的时候,在不指定泛型的情况下,泛型变量的类型为该方法中的几种类型的同一个父类的最小级,直到 Object。在指定泛型的时候,该方法中的几种类型必须是该泛型实例类型或者其子类。
泛型继承:子类可以获取父类的泛型类型
- 父类的类型是 Pair
- 子类的类型是 IntPair
- 子类可以获取父类的泛型类型 Integer
1 | public class IntPair extends Pair<Integer> { |
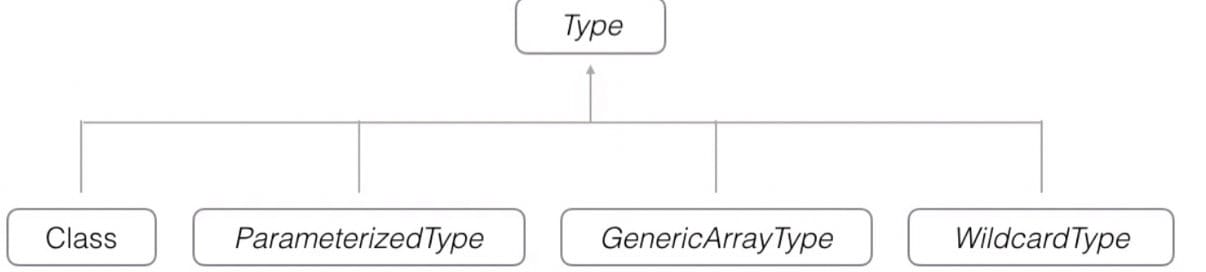
Type 接口:
通配符
转移阵地:好好调戏 Java 范型中的通配符以及边界限定规则
泛型和反射
部分反射 API 是泛型,如 Class
- T newInstance()。
1 | // compile warning if not w/ (String) |
- Class<? super T> getSuperclass()
1 | Class<? super String> sup = clazz.getSuperclass(); |
- Constructor
1 | Class<Integer> clazz = Integer.class; |
泛型数组
可以声明带泛型的数组,但不能用 new 创建带泛型的数组:
1 | Pair<String>[] ps = null; // OK |
这里实际上是利用了编译器的类型擦除,所以:
1 | (ps.getClass() == Pair[].class) // true |
不能直接创建 T[] 数组:擦拭后代码变成 new Object[5]。
- 借助 Class
:
1 | public class Abc<T> { |
- 利用可变参数创建 T[] 数组,用 @SafeVarargs 消除警告:
1 | public class ArrayHelper { |
集合
介绍 Java 集合的常用类,理解并掌握常用集合类包括 List、Set、Map、Queue、Stack 的数据结构、用法和适用场景。
简介
集合(Collection),这里不是指 set。
定义:一个 Java 对象可以在内部持有若干其它 Java 对象,并对外提供访问接口。Java 的数组可以看作是一种集合。
JDK 自带的 java.util 包提供了集合类:
- Collection:集合类的根接口
- List:一种有序列表
- Set:一种保证没有重复元素的集合
- Map:一种通过 Key 查找 Value 的映射表集合
Java 集合设计的特点:
接口和实现相分离:List 接口,ArrayList、LinkedList 实现支持泛型1
List<Student> list = new ArrayList<>()
访问集合有统一的方法:迭代器(Iterator),都实现了 Iterable 接口
JDK 的部分集合类是遗留类,不应该继续使用:
- Hashtable:一种线程安全的 Map 实现
- Vector:一种线程安全的 List 实现
- Stack:基于 Vector 实现的 LIFO 的栈
还有,Enumeration
List
List
- void add(E e) 在末尾添加一个元素
- void add(int index, E e) 在指定索引添加一个元素
- int remove(int index) 删除指定索引的元素
- int remove(Object e) 删除某个元素
- E get(int index) 获取指定索引的元素
- int size() 获取链表大小(包含元素的个数)
数组也是有序结构,但是大小固定,且删除元素时需要移动后续元素:
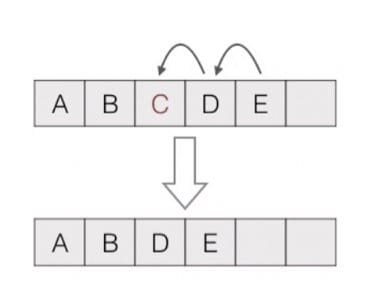
List 的元素可以重复,且可以是 null。
ArrayList
ListedList

遍历数组的方式:
在 for 中用 get(i) 来访问,对 ArrayList 来讲效率高,而对 LinkedList 来说较低。
Iterator
1
2
3for (Iterator<String> it = list.iterator(); it.hasNext(); ) {
String s = it.next();
}foreach(所有实现了 Iterable 接口都可以用这个方法遍历)
编译器会自动地把 foreach 循环改写成上面的 Iterator 迭代方式。
List 和 Array 转换:
- 把 List
变为 Array: - Object[] toArray()
T[] toArray(T[] a) 1
2
3
4
5
6Integer[] array = list.toArray(new Integer[2]);
// {1, 2, 3} new Integer[2] 无效,会被扔掉
Integer[] array2 = list.toArray(new Integer[5]);
// {1, 2, 3, null, null}
Integer[] array3 = list.toArray(new Integer[list.size()]);
// 最好的办法,大小一一对应。
- 把 Array 变为 List
: List Arrays.asList(T… a) 1
2
3
4
5
6
7
8
9
10
11
12
13
14Integer[] array = {1, 2, 3};
List<Integer> list = Arrays.asList(array);
// **注意返回的 list 并不是 ArrayList,而是 List**
// 这个 list 对象实际上是 Array 内部实现的一个 List 类,并且是只读的。
list.add(4); // UnsupportedOperationException!
// 如果想创建 ArrayList,还需做:
List<Integer> arrayList = new ArrayList<>();
arrayList.addAll(list);
// 或者一行代码:
List<Integer> arrayList = new ArrayList<>(Arrays.asList(array));
// 注意,如果不需要可变的 list,就没必要再转换成 ArrayList
equals()
List 中的 contains 和 indexOf 会用到所存对象的 equals 方法。
1 | public boolean equals(Object o) { |
Map
使用 Map
Map<K, V>
- SortedMap
- TreeMap
- HashMap
API:
- V put(K key, V value)
- V get(K key)
- boolean containsKey(K key)
1 | Map<String, Integer> map = ... |
最常用的实现类是 HashMap,HashMap 内部存储不保证有序。遍历时的顺序不一定是 put 放入的顺序,也不一定是 Key 的排序顺序。
SortedMap 是有序的(对 Key 排序,和 Value 无关)。
TreeMap 是一个有序的 key-value 集合,基于红黑树(Red-Black tree)的 NavigableMap 实现。
倒序排序 Key:
1 | Map<String, Person> map = new TreeMap<>(new Comparator<String>() { |
equals() & hashCode()
正确使用 Map 必须保证:
- 作为 Key 的对象必须正确覆写 equals() 方法,例如:String、Integer、Long
- 作为 Key 的对象必须正确覆写 hashCode() 方法
- 如果两个对象相等,则两个对象的 hashCode() 必须相等
- 如果两个对象不相等,则两个对象的 hashCode() 不需要相等
- 如果一个对象覆写了 equals() 方法,就必须覆写 hashCode() 方法
1 | // private String name; |
注意:默认的 equals 方法等价于 == 方法。
虽然,每个 Java 类都包含 hashCode() 函数。但是,仅仅当创建类的散列表时,该类的 hashCode() 才有用。其作用是:确定该类的每一个对象在散列表中的位置;其它情况下(例如,创建类的单个对象,或者创建类的对象数组等等,没有作用)。
hashCode() 和 equals() 的关系:
不创建类对应的散列表
在这种情况下,两者没半毛钱关系。hashCode() 根本不会起任何作用。创建类对应的散列表
如果两个对象相等,那么 hashCode() 值一定相等;如果两个对象 hashCode() 相等,equals 不一定等于 true。(哈希冲突)
Properties
Properties 用于读取配置,.properties文件只能使用 ASCII 编码。
如果要写中文,只能写 Unicode 码,如\u96c6\u5408\u7c7b。
读取:
1 | // 从文件系统中读取 |
可以读取多个.properties文件,后读取的 Key-Value 会覆盖已读取的 Key-Value。这个特性可以让我们先把默认的特性放在 classpath 中。
Properties 实际上侍从 Hashtable 派生:
- String getProperty(String key) √
- void setProperty(String key, String value) √
- Object get(Object key) ✕
- void put(Object key, Object value) ✕
但这种派生实际上是有误的,所以在实际中不要使用后面两个方法。
Set
- Set
- SortedSet
- TreeSet
- HashSet
- SortedSet
Set
- boolean add(E e)
- boolean remove(Object o)
- boolean contains(Object o)
- int size()
Set 实际上相当于不存储 Value 的 Map,放入 Set 的元素要正确实现 equals() 和 hashCode() 方法。
Set 不保证有序:
- HashSet 是无序的
- TreeSet 是有序的
- 实现了 SortedSet 接口的是有序的
Queue
使用 Queue
Queue
- 获取队列长度:size()
- 添加元素到队尾:boolean add(E e) / boolean offer(E e)
- 获取队列头部元素并删除:E remove() / E poll()
- 获取队列头部元素但不删除:E element() / E peek()
为什么都有两种方法?
当添加或获取元素失败时,左边的方法返回 Exception,右边的方法返回 false 或 null。
可以先用 isEmpty 判断,避免把 null 添加到队列。
使用 PriorityQueue
PriorityQueue
放入 PriorityQueue 的元素必须实现 Comparable 接口,或者通过在 new 的时候传入 Comparator 自定义排序的算法。
使用 Deque
Deque
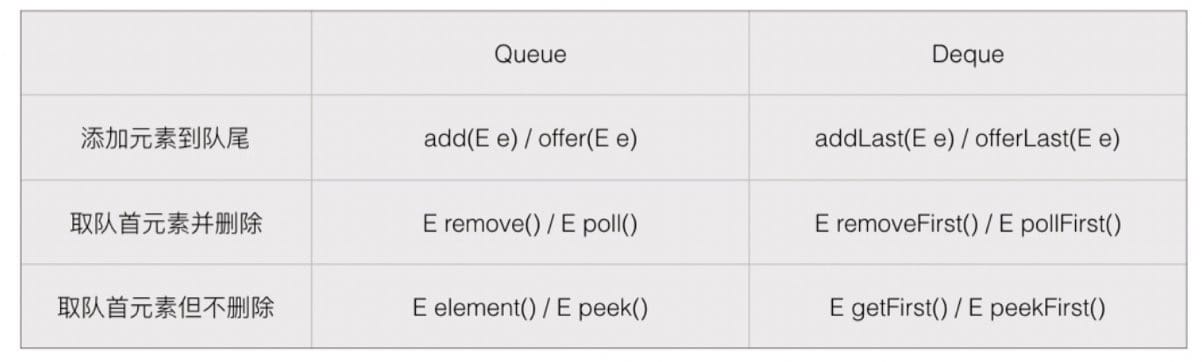
Deque 还有:
- addFirst(E e) / offerFirst(E e)
- E removeLast() / E pollLast()
- E getLast() / E peekLast()
- 直接写 offer() 是调用 offerLast 方法,但不要这么用。
Deque 的实现类:
- ArrayDeque
- LinkedList
1 | Deque<String> obj = new LinkedList<>(); |
可以看到 LinkedList 是全能选手。但是我们使用的时候总是用特定的接口去引用它,这是因为持有接口,抽象程度更高,而接口本身定义的方法代表了本身特定的用途。
这里可以看出面向对象抽象编程的原则之一:尽量持有接口,而不是实现类。
Stack
栈是一种后进先出(LIFO)的数据结构:
- push(E e):把元素压栈
- pop(E e):把栈顶的元素弹出
用 Deque 可以实现 Stack 的功能:
- push(E e):addFirst(E e)
- pop():removeFirst()
- peek():peekFirst()
最佳实践
给对象添加 Iterator 特性
如何让自己编写的集合类使用 foreach 循环:
- 实现 Iterable 接口
- 返回 Iterator 对象
- 用 Iterator 对象迭代
1 | public class ReadOnlyList<E> implements Iterable<E> { |
完整版:
1 | public class ReadOnlyList<E> implements Iterable<E> { |
使用 Collections
Collections 是 JDK 提供的工具类:
- boolean addAll(Collection<? super T> c, T… elements)
创建空集合(不可变):
- List
emptyList() - Map<K, V> emptyMap()
- Set
emptySet()
创建单元素集合(不可变):
- Set
singleton(T o) - List
singletonList(T o) - Map<K, V> singletonMap(K key, V value)
对 List 排序(必须传入可变 List):
- void sort(List
list) - void sort(List
list, Comparator<? super T> c)
随机重置 list 的元素顺序:
- void shuffle(List<?> list)
把可变集合变为不可变集合:
- List
unmodifiableList(List<? extends T> list) - Set
unmodifiableSet(Set<? extends T> set) - Map<K, V> unmodifiableMap(Map<? extends K, ? extends V> m)
1 | // 注意:通过 list 引用还是可以改的,所以最好写成一行(不要创建 list 引用) |
把线程不安全的集合变为线程安全的集合:
- List
synchronizedList(List list) - Set
synchronizedSet(Set s) - Map<K, V> synchronizedSet(Map<K, V> m)
- …(不推荐使用,有更好的方法)
IO 编程
介绍 Java 的 IO 流接口,掌握使用 InputStream / OutputStream 和 Reader / Writer,理解并应用 Filter 模式组合流接口。
IO 基础
简介
IO 流是一种流式顺序读写数据的模式:
- 单向流动
- 以 byte 为最小单位(字节流)

如果字符不是单字节表示的 ASCII:
- Java 提供了 Reader / Writer 表示字符流(其本质上是一个
能自动编解码的 InputStream / OutputStream) - 字符流传输的最小数据单位是
char - 字符流输出的 byte 取决于
编码方式

究竟使用 Reader 还是 InputStream,要取决具体的场景。如果数据源不是文本,只能使用 InputStream;如果数据源是文本,则使用 Reader 会方便一些。
同步 IO(JDK 提供java.io):
- 读写 IO 时代码等待数据返回后才继续执行后续代码
- 代码编写简单,CPU 执行效率低
异步 IO(JDK 提供java.nio):
- 读写 IO 时仅发出请求,然后立刻执行后续代码
- 代码编写复杂,CPU 执行效率高
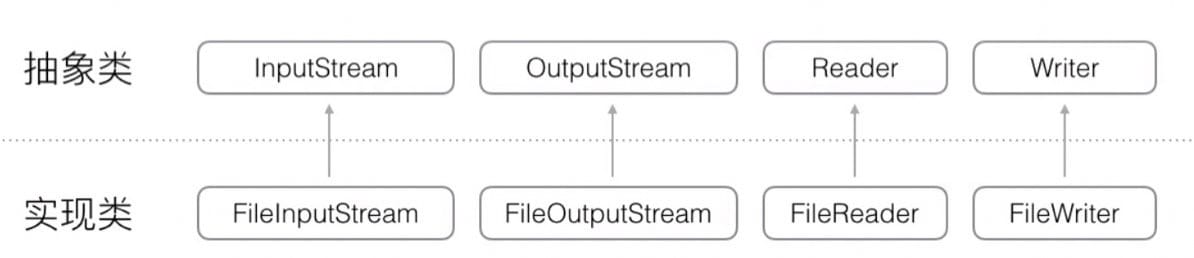
Java 的 IO 流的接口和实现是分离的:
- 字节流接口:InputStream / OutputStream
- 字符流接口:Reader / Writer
File 对象
java.io.File 表示文件系统的一个文件或者目录。
1 | File abs_f = new File("/usr/local/..."); |
注意的是:在构造一个 File 对象时,即使我们传入的路径不存在,也不会报错,因为构造的时候不会进行磁盘操作,直到调用某些 API 进行操作。还有很多 API,如 isFile、isDirector、canRead、createNewFile、list、listFiles(FileFilter filter)、mkdir 等等。
Input 和 Output
InputStream
java.io.InputStream 是所有输入类的超类:
- abstract int read()
- 读取下一个字节,并返回字节(0 ~ 255)
- 如果已读到末尾,返回 -1
- int read(byte[] b):读取若干字节并填充到 byte[] 数组,返回读取的字节数
- int read(byte[] b, int off, int len):指定 byte[] 数组的偏移量和最大填充数
- void close():关闭输入流
1 | public void readFile() throws IOException { |
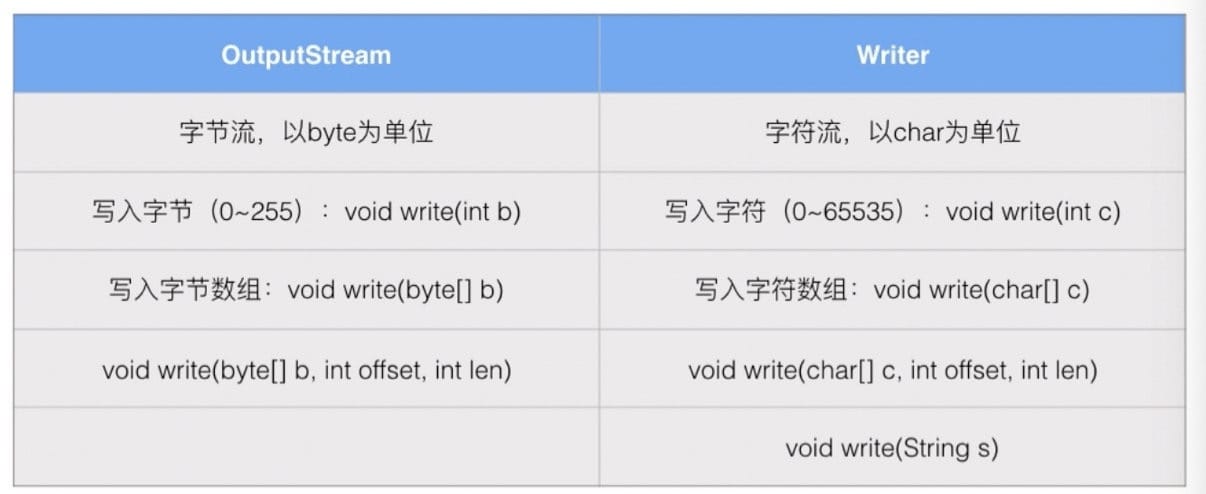
OutputStream
java.io.OutputStream 是所有输出流的超类:
- abstract write(int b):写入一个字节
- void write(byte[] b):写入 byte[] 数组的所有字节
- void write(byte[] b, int off, int len):写入 byte[] 数组指定范围的字节
- void close():关闭输出流
- void flush():将缓冲区的内容输出
1 | public void writeFile() throws IOException { |
Filter 模式(Decorator 模式)
filter 模式,在运行时动态增加功能。JDK 提供的 InputStream 包括:
- FileInputStream:从文件中读取数据
- ServletInputStream:从 HTTP 请求读取数据
- Socket.getInputStream():从 TCP 连接读取数据
下面是以 FileInputStream 为例:
添加缓冲功能:
BufferedFileInputStream extends FileInputStream添加计算签名的功能:
DigestFileInputStream extends FileInputStream添加加密、解密功能:
CipherFileInputStream extends FileInputStream
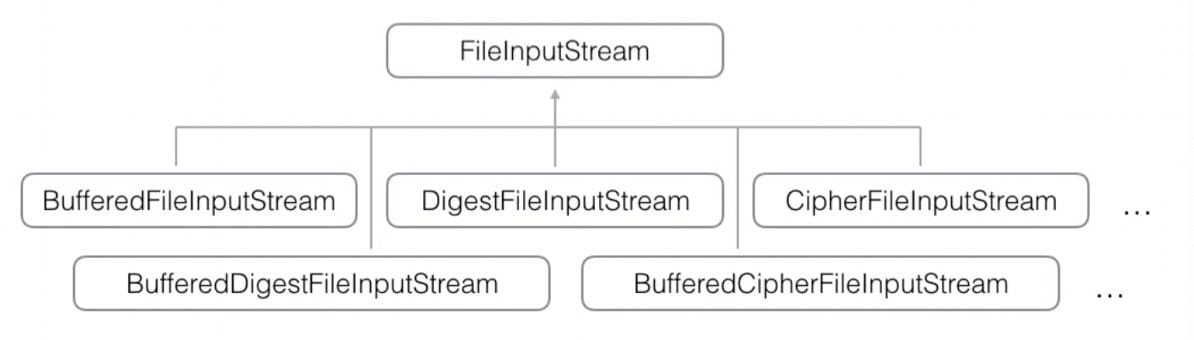
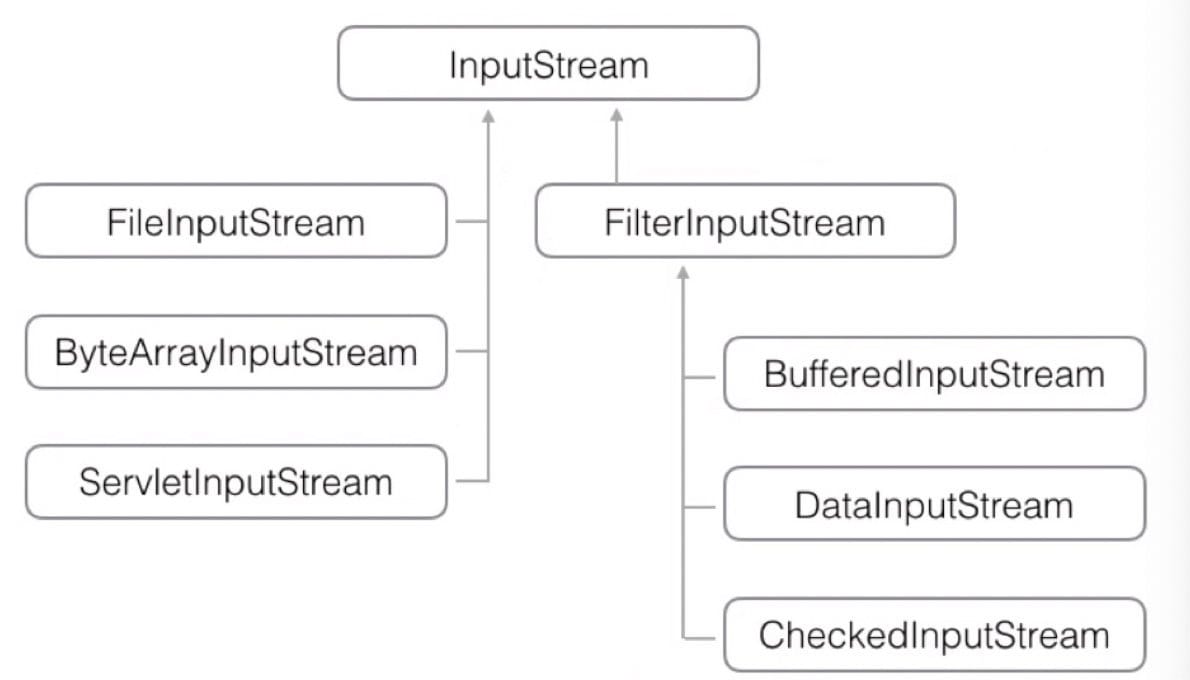
会导致子类爆炸。为了解决这种失控的问题,JDK 把 InputStream 分为两类:
- 直接提供数据的
InputStream:- FileInputStream、ByteArrayInputStream、ServletInputStream
- 提供额外附加功能的
FilterInputStream:- BufferedInputStream、DigestInputStream、CipherInputStream
组合功能而非继承的设计模式称为 Filter 模式(或者 Decorator 模式),通过少量的类实现了各种功能组合。
组合 InputStream:

1 | // 无论我们包装多少次,还是 InputStream |
操作 Zip
ZipInputStream 是一种 FilterInputStream,可以直接读取 Zip 内容。
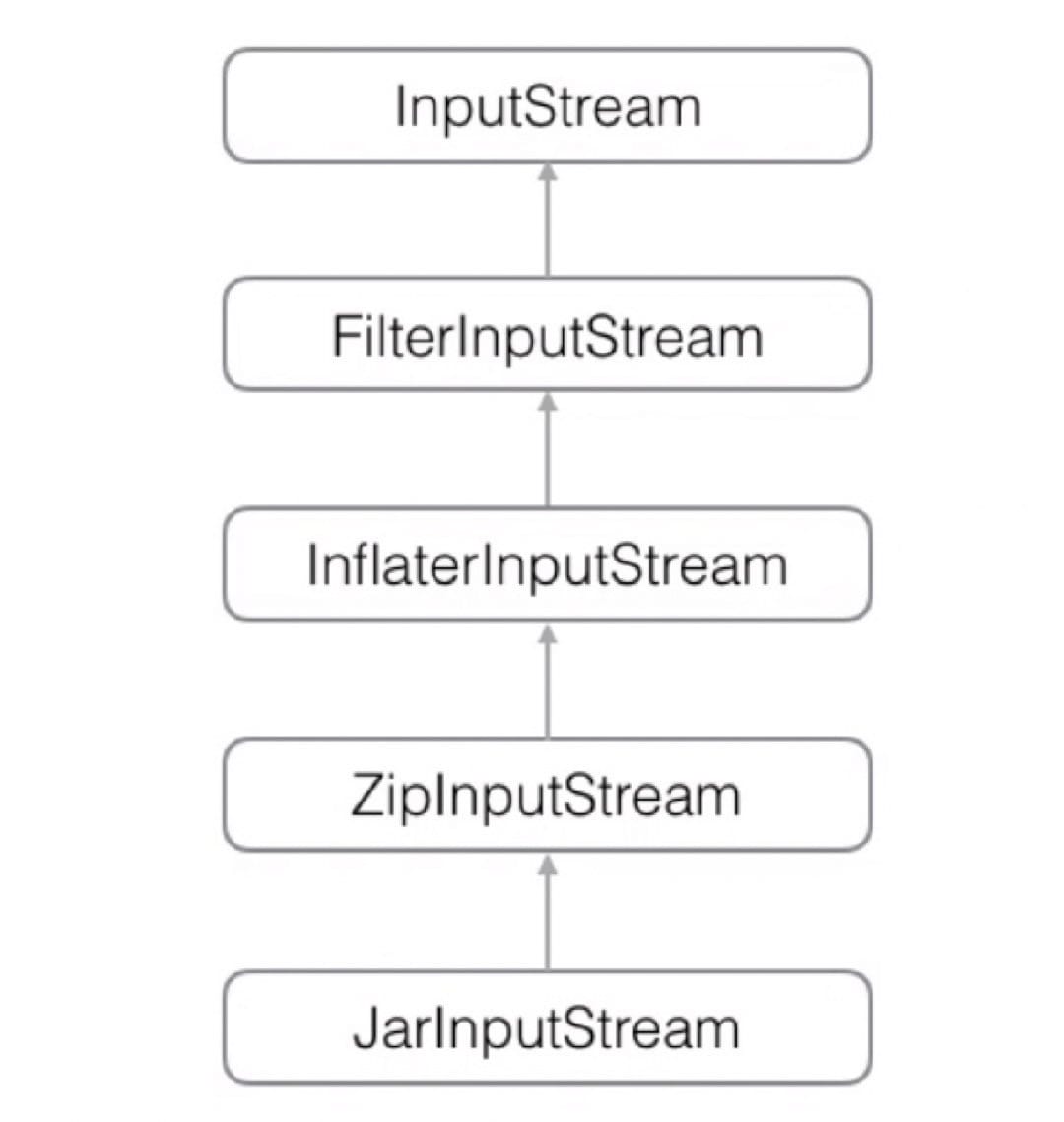
1 | // ZipInputStream |
classpath 资源
Java 存放 .class 的目录或 jar 包也可以包含任意其他类型的文件:.properties、.txt、.jpg、.mov 等等。
从 classpath 读取文件可以避免不同环境下文件路径不一致的问题:
1 | try (InputStream input = getClass().getResourceAsStream("/default.properties")) { |
序列化
序列化是指把一个 Java 对象变成二进制内容(byte[]):
- 序列化后可以把 byte[] 保存到文件中
- 序列化后可以把 byte[] 通过网络传输
一个 Java 对象要能序列化,必须实现 Serializable 接口:
- Serializable 接口没有定义任何方法
- 空接口被称为
标记接口(Marker Interface)
反序列化是指把一个二进制内容(byte[])变成一个 Java 对象。
1 | // 把一个 Java 对象写入二进制流: |
反序列化的重要特点:
反序列化是由 JVM 直接构造出 Java 对象,不调用构造方法。
序列化的类可以添加一个 serialVersionUID 作为版本号(非必需)作对比。
Java 的序列化机制仅适用于 Java。如果需要与其它语言交换数据,必须使用通用的序列化方法,例如 JSON。
Reader 和 Writer
Reader
Reader 和 InputStream 的区别:

1 | public void readFile() throws IOException { |
Reader 实际上是基于 InputStream 构造的:
- FileReader 内部持有一个 FileInputStream
- Reader 可以通过 InputStream 构造
1 | InputStream input = new FileInputStream(filename); |
Writer
Writer 和 OutputStream 的区别:
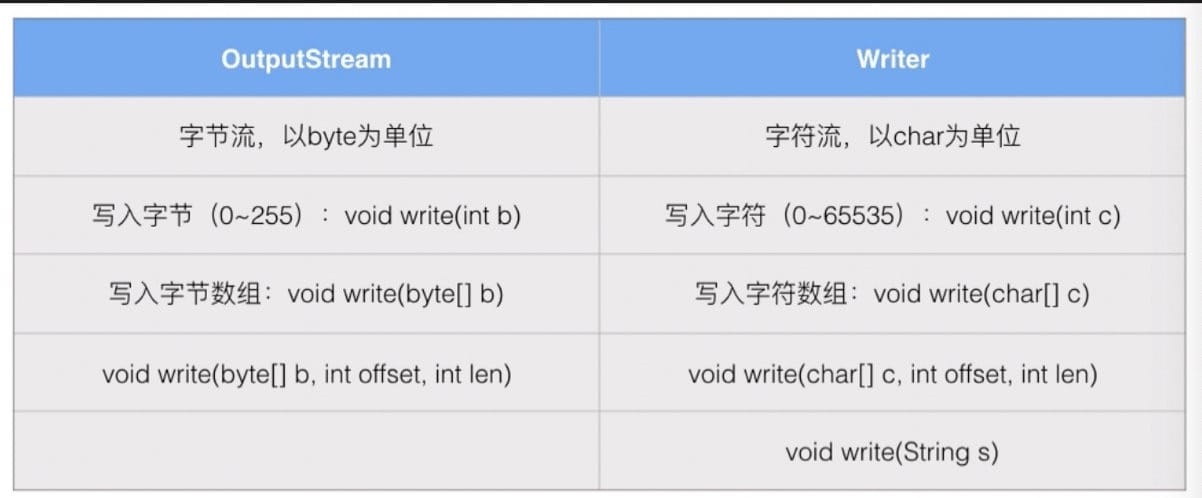
1 | public void writeFile() throws IOException { |
Writer 实际上是基于 OutputStream 构造的:
- FileWriter 内部持有一个 FileOutputStream
- Writer 可以通过 OutputStream 构造
1 | OutputStream output = new FileOutputStream(filename); |